2.5 ON-LINE DATABASE
2.5.1 Purpose
The On-Line database provides real-time data store/access capabilities on a distributed architecture to the environment database: RTAP one for FULL CCS, equivalent data stores for LCUs and CCS_LITE. Access methods, unless explicitely specified, are the same for the three platforms. Its main functions are:
· Data dependencies within the database (Rtap Calculation Engine, partly supported under CCS_Lite; See below in the Calculation Engine paragraph)
2.5.2 Basic Concepts
There is one database per environment, and it is referenced by the "environment name". It can be located either in workstations or in LCUs. The system file /etc/services provides a list of all known environments.
Values stored in the On line database are stored as "attributes" and grouped in "points".
The database organization is hierarchical and similar to that of a 'file system'; the environment name is equivalent to a file system, points are like directories and attributes can be considered as files within the directory.
Database elements can be referenced by their "Symbolic Address" or by "Direct Address"
2.5.3 Current Working Point
In order to reduce the overhead of a full absolute path search, there is the concept of the Current Working Point (CWP). This information is private to each process and allows it to set its area of interest to a certain point's sub-tree in the hierarchy, then to ``perform accesses relative to that point".
· Until the CWP is changed, all successive non-absolute or incomplete path accesses are relative to this point.
2.5.4 Direct Address
Allows a fast access to a database element and it is recommended when a fast periodic access is required.
The direct address is called PLIN (Point List Index Number) and is a unique reference number that identifies each point within the database and can be used as a direct address of the point.
The PLIN is automatically assigned to each point when the point is created - that is, when using the RTAP interactive utility RtapDbConfig() or the utility RtapDbLoader() - and remains the same until the point is deleted. A new point can be assigned a PLIN that was used by a deleted point, however this cannot be the case under CCS_Lite, since database structure is not dynamicalloy modifiable on-line.
The use of the "direct address" is restricted to the local environment
2.5.5 Symbolic Address
Allows the user to address a database element through the use of a name.
The database allows two main kinds of addressing:
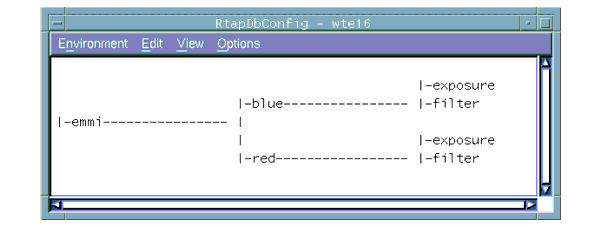
The database offers a `hierarchical' view of its structure and the location of each element is identified specifying the `path' leading from the root or from the "Current Working Point" to the addressed element. The following picture shows an example of hierarchical structure of a database.
The hierarchical organization makes use of three levels, somehow analogous with the respective Unix notions of host, directory and file. These levels are:
· The Attributes can appear everywhere in the database, attached to a point. They identify the physical storage place for data. Three main structures can be used to organize data: scalars, vectors and tables.
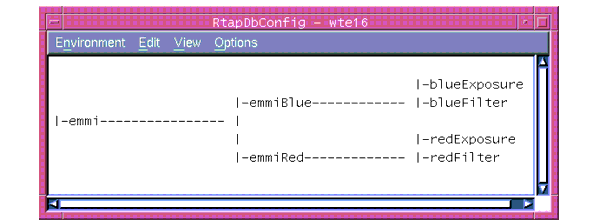
The database offers a `flat' view of its structure and the location of each element is identified by a name which is unique in all the database. The following picture shows the `alias' view of the previous picture. In this case database elements can be directly addressed by names such as: emmiBlue, redExposure, etc ...
2.5.6 Syntax Rules
A database element is addressed by specifying the environment (optional), point and attribute name. All these names are strings separated by special characters, as follows:
The RTAP syntax is used to specify the database element within an environment and repeated in points 2) and 3).
Point 1) is a VLT extension which allows us to specify a different environment in the symbolic address.
2.5.6.1 Environment Specification
Databases are referenced by the "environment name".
The environment name is the uppermost level of the database hierarchy and it is specified as first, optional, parameter of the symbolic name.
The environment name is prefixed by the symbol "@", as follows:
The naming rules for the environment are described in document [2], section "Naming and Address Allocation".
Among the rules, those relevant to the database access are reported hereafter:
The name of an environment for a generic name of WS or LCU begins with w/l and is followed by the name of the node, for example: wte16 or lte21.
The default database (specified by environment variable RTAPENV, both for CCS & CCS_LITE) is accessed if the environment name is not specified.
2.5.6.2 Points Specification
Points in the database can be addressed giving the full absolute path name, a relative one, or by alias (see section 2.5.9).
The Naming rules for points are described in section 2.5.10.
The point hierarchy starts from a 'special' point called root point.
This is formed by a concatenation of point names starting with ":" and the path is relative to the root point of the local environment.
This is formed by a concatenation of point names starting without ":" and the path is relative to the Current working point (CWP)
Example: If the Current Working Point is set to "@LCU1:point1", the symbolic address "point2" names is equivalent to the full symbolic address "@LCU1:point1:point2"
2.5.6.3 Attribute Specification
A point can contain data which are stored into its "attributes" and each attribute has a unique symbolic name within the same point.
Naming rules for points apply also for attributes. See section 2.5.10.
Values in the database can be stored into three basic data structures:
· Specifying "Start element" means "only that element''. For example, vector(3) is equivalent to specifying vector(3:3).
· Specifying a "$" as second element means "to the end of the vector". For example, vector(3,$) is equivalent to accessing the array from element 3 to the end.
· If the second index of the record/field range is omitted, it is assumed to be the same as the start. For example, table(3,8) is equivalent to table(3:3,8:8).
· Specifying a "$" as second index for the record/field means "to the last record/field". For example: table(1:$,1:2) tells the system to read the first two fields of all records, while table(1:3,1:$) read all the fields of the first three records.
2.5.7 Record Addressing by Content.
The selection of records in tables and vectors can be done according to the record's content, instead of explicitly specifying the record position of a table or a vector with a number. It is up to the user to be sure that the first field of all records contains meaningful contents.
For Tables the record numbers are replaced by strings and such strings are internally converted to the data type of the first field of the record.
To select a single record, a linear search on the first fields is performed. This stops when the first occurrence of the search criterion is found.
You can enter two search criteria to select a range of records.
Example: table("hello":"goodbye",0:4) selects all records beginning with the first record having a first field containing "hello" and ending with the first record having a first field containing "goodbye".
For vectors the same mechanism applies and the search is done with the content of the record.
This addressing uses a linear search algorithm in tables and vectors. This makes the access time longer, and unpredictable.Although it is a very useful and powerful addressing mode, it must be avoided where time performances are critical. A typical use is configuration tables where the first field can contain the configuration/set-up name and the parameters are given in the remaining fields of the record.
2.5.8 Examples of Symbolic Addresses
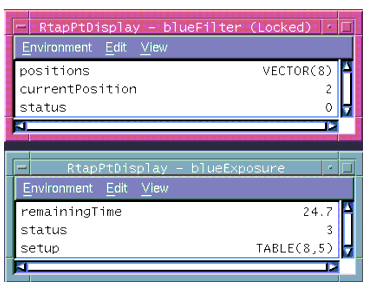
The examples refer to a read operation using the database sub-tree shown in the previous figures, whose points contain `exposure' and `filter' of the following data structures.
2.5.9 View Specifiers
RTAP defines the general concept of "view specifier" which applies only to the local database, and is also supported by CCS_Lite.
The view specifier is added in front of the symbolic name according to the following syntax:
and forces the system to regard the following symbolic address in a specific way.
The view specifier <alias> can be added in front of the symbolic name to specify that the name is an alias. The alias must be unique within a given database environment.
Alias names follow the same rule as point names -.e.g.- myAlias.attribute, but there is no hierarchy reflected in the address.
Interprets the following symbolic name as relative to the Current Working Point or as a child of the current point.
This view specifier is assumed if the address has no leading ":" after the environment specification.
This is used to remove any previously specified name interpretation and the address is considered to be relative to the root point.
This view specifier is assumed if the address has a leading ":" after the environment specification.
2.5.10 Naming Rules
This section specifies how to choose valid names for points and attributes.
In RTAP a name consists of up to 19 characters chosen from the following set:
2.5.11 VLT Naming Rules
For the VLT the naming conventions are restricted as follows:
NOTA BENE: The VLT naming rules are more restrictive than the Rtap ones. They shall apply to all application databases. However, since some of the basic configuration points are inherited from Rtap, their name and spelling had to be kept as defined by Rtap, although they are not fuly compliant with the VLT naming rules.
· Attributes and Point names follows the programming Standard naming rules concerning 'Local Variables'. A name is formed by several words each having the first letter in capitals.
2.5.12 Data Structures
The following types of data are supported:
Points have up to 255 attributes which can be of three types:
2.5.13 Calculation Engine
It is possible to introduce run time data dependencies within the database: that means that the value of an attribute will be derived from the value of one or several other attributes, using a mathematical formula. The formula and the way it should be applied must be declared in the dbl file defining the database structure.
2.5.13.1 Calculation Engine Operation
The Calculation Engine is automatically triggered by write operations in the database. Whenever an attribute is written in a database point, all formulas depending on any attribute of that same point are re-evaluated and results are written in the corresponding attributes.
A CE operation indicator is controlling this automatic triggering. This indicator is defined on point level, i.e. its value is the same for all attributes belonging to the respective point. The possible operation modes are:
· enabled: If the Calculation Engine is enabled for a point any write access to an attribute causes the Calculation Engine to run. It runs on the point containing the attribute written to and on all other points which have attributes whose values depend on the data just written.
· disabled: If the Calculation Engine is disabled for a point the attribute's values of this point and of any dependent points are not updated.
· optimised: If the Calculation Engine operation mode is chosen to be optimised for a point the Calculation Engine behaves as follows:
· If only CE definitions in other points than the one containing the attribute just written use the value, the Calculation Engine is triggered on exactly those points.
After a CE definition has been processed the result value and additionally the data quality are stored in the database attribute. Currently four qualities are defined:
· · ERROR: A new value could not be calculated because of an internal error (e.g. data type mismatch, division by zero etc.) or because all used data had the quality ERROR. The result remains unchanged.
· DISABLED: The Calculation Engine is disabled for the point containing this attribute and therefore no new value has been calculated.
· SUSPECT: At least one value which was involved in the calculation had the data quality ERROR, DISABLED or SUSPECT. But not all data had the quality ERROR, this would have resulted in ERROR. The calculation has completed and the attribute value is updated.
· OK: In all other cases. The calculation has successfully completed and the attribute value is updated.
Just after loading the database, the calculation engine is also run once for the complete database to insure data consistency.
2.5.13.2 Calculation Engine Order
The Calculation Engine supports two methods of processing order:
· Natural order: The basic idea behind this type of calculation order is to evaluate the attribute's values according to their dependencies. This means that if an attribute depends on some others those other attributes are evaluated first.
· User defined order: All attributes are simply evaluated in the order they appear in the point, i.e. the order they have been defined in the dbl file.
1. It is possible to implement CE definitions in the following way: An attribute a of point A contains a definition that refers to an attribute b1 of point B which is below A. The CE definition of another attribute b2 of point B may refer to attribute a . This is called a circular reference. In this case the Calculation Engine does not re-evaluate points. It immediately stops following dependencies, if this would mean to calculate a point again which already has been calculated. To avoid some confusion resulting from this behaviour you can use only one triggering dependency and some more non-triggering dependencies (see section below).
2. Not allowed, however, are implementations of CE definitions which would lead to circular dependencies. As examples assume that an attribute a refers to an attribute b of an arbitrary point and this attribute b directly refers back to attribute a. Or the attribute a refers to attribute b, this indirectly refers back to attribute a by referring to an attribute c of an arbitrary point which itself refers to attribute a.
2.5.13.3 Calculation Engine Definitions
Calculation Engine definitions (mostly abbreviated as CE definitions) are strings, which define the operations the Calculation Engine must perform at runtime to get the value of an attribute, if there is more to do than simply to write the value. It can be assigned to any attribute of type SCALAR or VECTOR. The CE definitions work on attribute level.
They must be defined in the dbl configuration files.
Definition = <CE definition string>
A <CE definition string> may consist of up to 2048 characters. It can contain combinations of Constants, mathematical or logicaloperators, Calculation Engine functions and references to other attributes which can be evaluated to a value, which on his part can be coerced to the data element type of the attribute the CE definition is assigned to. E.g. it is not allowed to assign a CE definition which results in a string to an attribute of data element type dbINT8.
This function returns the result of <expression1> if the evaluation of <condition> results in true, i.e. in a scalar numerical value which is non-zero. Otherwise it returns the result of <expression2>. Both expressions must be of the same type, i.e. both must be numbers or both must be strings etc.
This function returns the factorial of the input parameter <integer>. <integer> may be any expression of scalar integer type with a value between 0 and 169. The result is returned as data type vltDOUBLE.
This function returns the maximum value of the parameter list <value1> to <valueN>. The number of parameters is variable and they may be scalars, vectors or tables, provided all elements fit in the scope of a vltDOUBLE. The result is returned as data type vltDOUBLE.
This function returns the minimum value of the parameter list <value1> to <valueN>. The number of parameters is variable and they may be scalars, vectors or tables, provided all elements fit in the scope of a vltDOUBLE. The result is returned as data type vltDOUBLE.
This function returns the value of <base> raised to the power of <exponent>. Both parameters may be any expressions resulting in scalar real numbers within the scope of a vltDOUBLE. Additionally, if <base> is zero, <exponent> must be positive and if <base> is negative, <exponent> must be an integer. The result is returned as data type vltDOUBLE.
This function returns the square root of the input parameter <real>. <real> may be any expression resulting in a scalar number within the non-negative scope of a vltDOUBLE. The result is returned as data type vltDOUBLE.
This function returns the vector-product of the input vectors <vector1> and <vector2> as defined for a right handed three-dimensional coordinate system. The input parameters <vector1> and <vector2> must be vectors of record length 3 and data type vltDOUBLE. The result is returned as a vector of record length 3 and data type vltDOUBLE.
This function returns the absolute value of the input parameter <val>. <val> may be any expression resulting in a scalar number within the scope of a vltDOUBLE. The result is returned as data type vltDOUBLE and possibly coerced to the destination attribute type.
This function returns the floating point remainder of the division of val1 by val2, with the same sign as val1 just like the fmod function of the mathematical c library. The result is returned as data type vltDOUBLE and possibly coerced to the destination attribute type.
This function returns the floating point average of the values val1 to val n. Any of the values can be a vector, in which case all the elements within the vector addressing range are counted for individual values.The result is returned as data type vltDOUBLE and possibly coerced to the destination attribute type.
This function returns the floating point Tangent of val expressed in radians. The result is returned as data type vltDOUBLE and possibly coerced to the destination attribute type.
This function returns a vector of logicals. int1 can be an integer, or the address of an integer attribute, whose bits will be individually extracted to fill the corresponding elements (bit 0 goes to element 0,...) of the destination vector of logicals. The destination vector must have exactly the matching size: 8 elements to unpack an int8, 32 elements for an int32 or uint32
NOTE: If a CE definition contains one of the following data movement functions this function cannot be combined with any additional function and it cannot be part of a mathematical/logical expression. The reason for this is the fact that these functions may return values of various data types which depend on the data types of the function's input parameters. This means that the return type is set by the function itself during runtime of the function.
This function returns the result of the expression <expression> and writes it into the database attribute specified by <address>. If <address> is a scalar the function must get only two parameters. If <address> is a vector, <RecOff> is the offset at which the <expression> is placed, relative to the beginning of the vector address <address>. In this case the function must get three parameters. And if <address> is a table, <RecOff> is the offset record and <FieldOff> is the offset field, respectively, which define the location relative to top left corner of the table area specified. In this case the function must get all four parameters.
This function returns the value of the single data element out of the vector or table area specified by the parameter <vectab>. <record> describes the desired record or vertical offset from the beginning of the area specified by <vectab>. If a vector is referenced the function must get only the first two parameters and if a table is referenced the function must get all three parameters. Then <field> additionally specifies the field or horizontal offset from the beginning of the area specified by <vectab>.
This function simply returns the resulting value of the expression <value> if the expression <condition> can be evaluated as logical true, i.e. if the result of it is a non-zero integer or real number. If the result is logical false (zero) then the quality of the returned value is set to ERROR. This function can be used to force the quality of an attribute to ERROR.
NOTE: If a CE definition contains this function it cannot be combined with any additional function and it cannot be part of a mathematical/logical expression. The reason for this is the same as for the data movement functions (see above).
NOTE: The scan system (see corresponding section) internally uses these two functions to relate an attribute with its scan link, and the user shall never modify directly a formula with a scan function, but rather use the provided scan utilities. A fundamental consequence is also that since only one formula can be associated to an attribute, a scanned attribute cannot be the result of a calculation. However, it can be used within formulas to calculate other attributes.
The 5following functions are used by the alrm system, and are automatically generated by the alrm system macros when alrm points are instantiated into the online database. The user has no need to manipulate them directly.
Accepted database addressing are symbolic and alias, and they follow the standard naming rules previously described in this db section. A database reference can take two forms:
[Point_P.Attribute_a] or {Point_P.Attribute_a}
The first form (usage of []) indicates true dependency: whenever an attribute will be written in Point_P, the formula will be re-evaluated. The second form (usage of {}) indicates a pseudo dependency: the formula won't be re-evaluated for every write. See third example below.
2.5.13.4 examples of CE definitions:
Definition = IF([.temp] >= 95.0, "ALARM", "OK")
Definition = SQRT([.kappa] * 287 * [.temp])
Definition = ({Constants.gravity} * [Body.mass])/POW({.c},2) That formula will be re-evaluated only in case an attribute of the "Body" point is written, while changes in the "Constants" point won't trigger re-evaluation.
· Definition = SQRT(1/([.ind]*[.cap]) - POW([.res]/(2*[.ind]), 2))
2.5.14 Programmatic Interface
A library allows programmatic access to data which can be stored in memory or on disk and located locally or in another host.
It follows a brief description of the routines, which are divided according to their functionality.
The environment name is used to 'open' a given database. If the environment name is not explicitly specified, the default local database is used, according to what specified by the environment variable RTAPENV(valid also for CCS_LITE).
To get connected to a database an implicit open operation takes place the first time the database is accessed, otherwise the application can perform an explicit open (dbOpen).
The latter method can be used, for example, at the beginning of the application, (but after a call to ccsInit) when the application designer knows he needs access to a given database. In this way the application can detect the availability of the specific database before starting.
A Remote environment can become unreacheable, for example, because of a temporary shutdown. When it starts up again all applications that used to access the environment will have not valid connections and therefore an attempt to access the remote database will fail.
This condition is detected by one of the following errors ccsERR_ENV_NOT_ACTIVE or ccsERR_REMOTE_LINK and the database routines react as follows :
· Try to re-open the database to repeat the database operation. This is done in the case that the environment is `up' again and we only need to re-establish the connection.
· If the environment is unreacheable the connection is marked `down' and a re-open operation will automatically take place at the next access.
Read operations are allowed concurrently with writes and an interlock method arbitrates the access to the database in order to ensure that the read operations get correct data.
Applications can have exclusive access to database elements by locking the point containing the data (see section "Locking Database Point").
The read routines check internally the 'quality' flag associated with the database value and return an error in case of 'bad' quality.
Elements of a remote database are accessible by specifying, in the symbolic address, the environment name of the remote database regardless whether they run on a WS or on a LCU.
Access to multiple database values is done storing in a description list the information about all the attributes that must be accessed with a single operation. A single call to one of the basic functions:
performs the actual access to the database. This is equivalent to multiple calls to the simple read/write database routines, but provides better performance or data integrity during write operations. In particular dbMultiWrite() provides an option which allows the user to write values of a set of parameters as an atomic operation to warrant consistency of the written set of data.
· All the database elements in the list are searched in the same environment. Workstation (Full CCS as well as CCS_LITE) and LCU databases are supported.
· The list is created for READ or WRITE operation. It is not possible to change this setup at run time. Attributes which must be accessed both for read and write must be placed in two different lists, one used only for READ and the other only for WRITE.
· A list is identified by a name and by a list identifier. The list identifier is used for performance reasons to manipulate the list. Once a list is created, the name can be used everywhere inside the application program to retrieve the identifier.
When created, the list requires some initialization. Two calls are used to `create' and `delete' a list:
After a call to dbMultiRead() or dbMultiWrite(), the information concerning each attribute currently described in the list can be retrieved using the function:
The returned data are placed in a structure of type dbATTRINFO, that provides the following information:
attrInfo.bufSize Size of the data buffer
attrInfo.buffer Pointer to the data buffer
attrInfo.recordCnt Number of records
attrInfo.dataType Pointer to the array with data types
attrInfo.attrType Type of attribute
attrInfo.actual Actual number of read/written bytes
attrInfo.status Completion status of the operation
Mutual exclusion allows an application to make a sequence of actions on a database element non-interruptible, such as: read a value, perform some calculations and update it.
It is implemented on a per-point basis, therefore an application must lock the whole point to have exclusive access to any of its attributes.
· A time-out parameters defines the maximum time an application can lock the point and it is fixed at the minimum: 3sec.
· The point is released either explicitly by the application (dbUnlockPoint) or automatically when the time-out expires.
2.5.15 Programming Rules
This section contains general remarks on the use of the on-line database routines.
· The database routines open automatically a given database the first time it is referenced, however for the application designer, there is also the possibility to make an explicit dbOpen whenever he knows that he needs to access a given database.
· The local environment is defined by symbol ccsLOCAL_ENV. In this case the routine will access the default database defined by the environment variable RTAPENV.
2.5.16 Access Permissions
This feature, provided by Rtap is not supported in CCS. Since it is not foreseen to implement the equivalent capabilities under CCS_Lite, it is strongly recommended to avoid any use of the Rtap security features within applications.
2.5.17 Backup/Restore to/from files
RTAP offers tools which support a 'static' and a 'dynamic' backup of the database configuration (see section "Configuring the Database" in the RTAP Integration Manual).
2.5.17.1 Static Backup(FULL CCS only)
The database structure can be mapped into an equivalent structure in the file system, where points are represented by directories and each point is described by an ASCII file called 'configuration file'.
The 'configuration file' contains:
The syntax used for the configuration file follows the instructions of section "Configuring the Database", paragraph ``Database Point Configuration File Format" in the RTAP Integration Manual)
RTAP provides the following two utilities:
· RtapDbLoader create new database points/sub-tree loading the corresponding directory/sub-tree from the file system. The attributes are initialized with the values specified in the configuration files.
· RtapDbUnloader maps the current database configuration, or part of it, into directories and configuration files. The current database values are copied into the configuration files.
2.5.17.2 Dynamic Backup
RTAP provides a mechanism to periodically save on disk the information related to the database which resides in RAM. The image on disk of the CCS database is called snapshot and the frequency of the snapshot generation is user configurable.
· Database values. These are alternately saved into two snapshot files RtapRamSnap0 and RtapRamSnap1 to ensure at least one valid snapshot data file.
The RTAP utility RtapForceSnap is used to force a database snapshot at any time.
An equivalent functionality is provided by dbForceSnap in CCS_Lite environments: the Database values are saved into a datafile called <envName.db> located into the environment directory, and Calculation engine formulas are saved into a file named <envName_CE.db> in the same directory.
It is also possible to force a snapshot during environment shutdown, using the option -s for RtapShutdown or -w for ccsShutdown. There is no automatic periodic scheduling of dbForceSnap in CCS_Lite; but it's possible to configure the environment to automatically produce a snapshot before shutdown. See dbForceSnap man page for configuration details.
2.5.17.3 Logical backup
In addition to the facilities mentioned above, CCS offers also the utilities dbBackup and dbRestore enabling a user to save and restore database values (CE formulas are not saved)on an attribute basis.
dbBackup creates a backup-file of all attributes specified either by command line parameters or in a input file.
dbRestore uses the backup-file to restore the values in the same attributes. The use of relative addressing allows through simple changes of the current working point to restore data in different branches of the database or in any other environment provided that the attributes are already existing.
2.5.18 Utilities
There is a group of `Utilities for Database Configuration' which provides means to modify the database structure such as: add, delete and move points and attributes. Some of the utilities can only be used interactively while others can be used in scripts.
There is a group of ` Utilities to Access Database values' which provides means to modify the values in the database attributes. Some of the utilities can only be used interactively while others can be used in scripts. The ccs engineering interface also provides tools to access database structures & data. Please refer to the ccsei section of this manual for further details.
2.5.19 Configuration
Define the following environment variables
2.5.20 Reference
|
Quadralay Corporation http://www.webworks.com Voice: (512) 719-3399 Fax: (512) 719-3606 sales@webworks.com |