Common DFOS tools:
Documentation
|
| dfos
= Data Flow Operations System, the common tool set for DFO |
Note: In this documentation, three different processing modes for phoenix are covered:
- IDP means Internal Data Product and stands for processing normal (OB-based) science data products.
- MCALIB is short for master calibrations, if reprocessed in a PHOENIX process.
- DEEP means the processing of cross-OB science data products.
Details of the phoenix process and configuration differ for these three modes. In some parts, this documentation splits into sections applicable to the specific modes, while other parts are generic.
The COMPLETE mode is a special mode of the IDP mode. |
| |
Parts specific to the IDP mode are shaded light blue (like this cell). |
Parts specific to the MCALIB mode are shaded light-yellow (like this cell). |
| Parts specific to the DEEP mode are shaded light-red (like this cell). |
PHO
ENIX |
phoenix: workflow
tool for automatic science processing |
![[ top ]](/images/arr1red-up.gif "[top]") Description and process
Description and process
The phoenix tool is the workflow tool to support the automatic and efficient processing
of large homogeneous science datasets
into IDPs. (IDP
is the acronym for science data products produced in-house, in contrast to
the science data products produced externally by PIs which are called EDPs.)
The phoenix tool supports the following modes:
- classical OB-based IDPs,
- reprocessing of master calibrations,
- DEEP IDPs (combined across OBs),
- reprocessing of CALIBs as needed for IDPs, plus the IDPs (COMPLETE mode).
Depending on mode and configuration, the processing is based on
- certified and ingested master calibrations which went through the classical QC processing,
scoring and certification workflow (separate processing that might have occurred years before the IDP processing); OR
- new master calibrations created together with the IDPs (COMPLETE mode);
- existing associations (stored on the qcweb QC server); OR
- new associations (created by calSelector).
The benefits of phoenix processing are:
- the homogeneous processing of a large dataset with a mature and reviewed pipeline;
- best-possible processing parameters;
- extraction of QC parameters for quality assessment.
DEEP mode: The meaning of DEEP combination is "to combine datasets across OBs". This is usually intended by the PI for going deeper than possible in a single OB (which is constrained by the 1 hr rule). A pre-selection of input datasets needs to be done by special preparation tools, because this is conceptually not part of the standard (DFS or DFOS) workflows. Usually the datasets need to be calibrated one by one, before they can then be combined in a final step ("step-2 processing"). This puts some requirements on the architecture of the pipeline. The second step might also be provided by a generic pipeline (like stacking by the HDRL pipeline).
The internal organization of the processing is also different from the normal (OB-based) processing, because it needs to be done by runID and not by date.
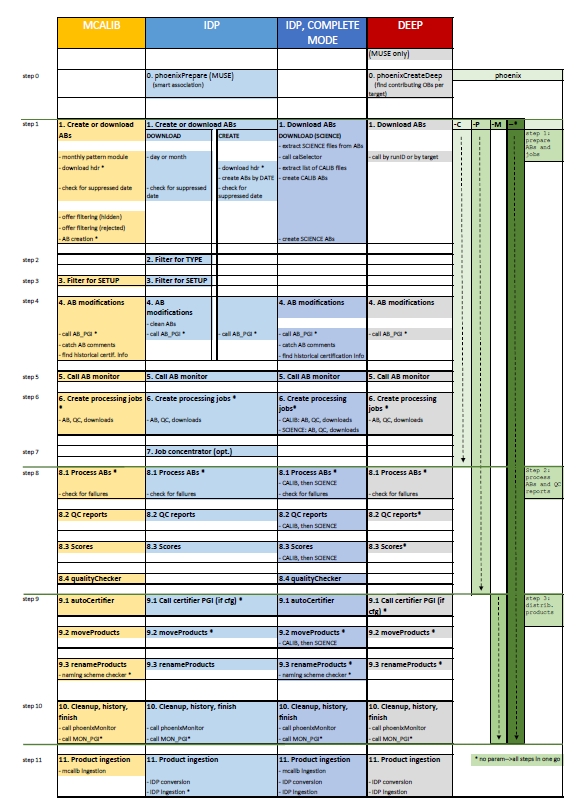
Workflow
description (see also 'Operational workflow' here)
The IDP process has three components:
- the preparation (pre-processing) component: download or create the ABs, scan them, define/re-define input datasets (currently for MUSE and MUSE-DEEP only), covered by phoenix and its pgi's;
- the processing component, covered by phoenix;
- the post-processing (ingestion) component covered by a conversion tool (for header manipulation, or DFS
reformatting tools like uv2p3) and the DFS ingestionTool, both plugged into the standard DFOS ingestProducts.
The phoenix processing workflow has many similarities with the autoDaily workflow.
A) For IDPs (OB-based or DEEP), the phoenix workflow has the following components:
| |
pre-processing |
|
phoenix -d <date> (call
by date) or phoenix -r <runID> (call
by runID) if DEEP mode |
|
ingestProducts -m SCIENCE -d <date> |
| step |
- special preparation step, existing for MUSE only;
- optimize associations for MUSE_smart;
- create DEEP associations for MUSE_DEEP |
- download ABs from $ORIG_AB_DIR;
- filter by raw_types, setups
(as configured)
- edit ABs (remove outdated content; call configured pgi);
- OR, under certain conditions: create SCIENCE ABs |
- prepare execution jobs: download raw, download mcalib, AB and QC queues
|
- execute job files |
- review |
- distribute products |
- finish that date |
- convert products into proper IDP format (if configured)
- ingest into phase3 archive
|
| calling ... |
plugins like:
- phoenixprepare_MUSE
- phoenix_getInfoRun
- phoenix_createDeep |
[within phoenix] |
createJob |
ngasClient, vultur, processAB, processQC, scoreQC, QC procedures |
|
moveProducts, renameProducts |
finishNight; phoenixMonitor |
idpConvert_xx (as configured);
call_IT and ingestionTool |
| |
If major changes to ABs have to be done, there is the tool phoenixPrepare_<instr> that needs to be customized for the specific instrument and needs to be called before phoenix. |
With v4.1, there is also an association module in phoenix for IDPs (conditions apply, see below); if not used, all ABs are downloaded from
a central source. Then, editing (by a PGI) of ABs is done to remove obsolete content (like RB_CONTENT)
and add e.g. new processing parameters. |
The call of createJob follows the current scheme on the mucs; download
job files are essential since muc08/10/11 processes are massively parallel (up to 56 jobs). Both
the pipeline and the QC procedures are queued under condor. A "job concentrator" for QC jobs is available, for better efficiency. Non-standard job execution patterns are available (like 2stream processing for MUSE). |
After the execution of the download jobs, two queues are executed: first the
processAB queue, and then the processQC queue. |
In general not formalized; in most cases quick check for red scores sufficient; if needed, a CERTIF_PGI can be used; automatic comments are provided by pgi's. In DEEP mode, there is a mandatory certification module. |
This is the standard moveProducts call, with all products, logs and
plots in the final DFO directories and the logs+plots exported to qcweb. |
The phoenixMonitor is called to provide the
processing overview, in the histoMonitor style. An ingestion call is written
into JOBS_INGEST. |
The files are ingested in a separate workflow step. |
While this is the basic processing step, the typical processing pattern in IDP mode is
by month. An exception is the daily mode for MUSE IDPs. The DEEP mode is run by run_ID, encoded as pseudo-date.
B) For MCALIBs, the phoenix workflow has the following components:
| |
[no pre-processing] |
phoenix -m <month> (call
by month) |
|
ingestProducts -m CALIB -d <date> |
| step |
|
- create ABs for the data pool;
- filter for hidden or previously rejected files
- filter by setups
(as configured)
- edit ABs |
- prepare execution jobs: download raw, AB and QC queues |
- execute job files |
- review |
- distribute products |
- finish that date |
- detect and delete pre-existing products
- ingest as normal MCALIB into archive |
| calling ... |
createAB |
createJob |
ngasClient, vultur, processAB, processQC, scoreQC, QC procedures |
[within phoenix: qualityChecker, autoCertifier] |
moveProducts, renameProducts |
finishNight; phoenixMonitor |
ingestProducts |
| |
Headers are downloaded if not existing in the system. They can be filtered and even edited (with DATA_PGI). Editing of ABs is done to edit processing parameters. |
The call of createJob follows the current scheme on the mucs; download
job files are essential for raw data. Both
the pipeline and the QC procedures are queued under condor. |
After the execution of the download jobs, two queues are executed: the
processAB queue, and then the processQC queue. |
qualityChecker is a component to combine new (score-based) and historical information; autoCertifier is a simple version of certifyProducts |
This is the standard moveProducts call, with all products, logs and
plots in the final DFO directories and the logs+plots exported to qcweb. For the renaming, versioned config files are supported. phoenix does a check on the final MCALIB names. |
The phoenixMonitor is called to provide the
processing overview, in the histoMonitor style. An ingestion call is written
into JOBS_INGEST. |
The products are ingested in a separate workflow step. |
C) In COMPLETE mode, the phoenix workflow has the same logical steps as under A), with the modified behaviour that all AB-based workflow steps are executed first for the CALIBs and then for the SCIENCE ABs. The SCIENCE ABs are recreated with calSelector/createAB. The CALIB ABs are created and executed only for those calibrations that are required for processing the SCIENCE ABs. Other than in daily QC, the creation of the CALIB ABs is not strictly day by day, but governed by the date of the SCIENCE ABs.
| |
[no pre-processing] |
phoenix -d <date> (call
by date) |
|
ingestProducts -m SCIENCE -d <date> |
| step |
|
- download SCIENCE ABs from $ORIG_AB_DIR, filter for raw_types;
- extract list of SCIENCE files
- expose them to calSelector;
- extract list of CALIBs from txt files
(those needed for SCIENCE)
- create new ABs for CALIBs and then for SCIENCE
|
- prepare execution jobs for CALIB and for SCIENCE: download raw, create AB and QC queues |
- execute job files |
- review |
- distribute products |
- finish that date |
- convert products into proper IDP format (if configured)
- ingest into phase3 archive |
| calling ... |
[within phoenix] |
createJob (twice) |
ngasClient, vultur, processAB, processQC, scoreQC, QC procedures |
|
moveProducts, renameProducts |
finishNight; phoenixMonitor |
ingestProducts -m CALIB: using dpQuery
ingestProducts -m SCIENCE:
idpConvert_xx (as configured);
call_IT and ingestionTool |
| |
The ABs are created from scratch, starting with calSelector content for SCIENCE and then calling createAB. All CALIBs needed for a set of SCIENCE are processed first, then the SCIENCE. |
The call of createJob follows the current scheme on the mucs; all steps are done twice, for CALIB and then for SCIENCE |
After the execution of the download jobs, four queues are executed: the processAB queues for CAL and SCI, and the processQC queues. |
Because of the creation of new mcalibs, there is the autoCertifier/ qualityChecker module called for the CALIBs (see under B). |
This is the standard moveProducts call, first for CALIB, then for SCIENCE. |
The phoenixMonitor is called to provide the
processing overview, in the histoMonitor style. An ingestion call is written
into JOBS_INGEST. |
The files are ingested in a separate workflow step. |
Find below a flow diagram that might also help to understand the processing workflow [click for full-size]:
Technical implementation
A) Workspace.
IDP mode: Each PHOENIX process has its own workspace, in order not to interfer with other PHOENIX accounts. This is currently established by having PHOENIX accounts on dedicated PHOENIX servers. There are sciproc (for UVES; the non-standard name is heritage and has no special meaning),xshooter_ph, giraffe_ph etc. on the server muc08. There are also the PHOENIX accounts muse_ph2 on muc10, and muse_ph3 on muc11. Find the up-to-date list here: phoenix_instances.
The workspace is defined in the resource file .dfosrc which is called upon
login from .qcrc.
To switch to COMPLETE mode, the config key COMPLETE_MODE is set to YES in config.phoenix. |
MCALIB mode: There is a special mechanism to use the same account for PHOENIX projects of both flavours:
- Define the config key MCAL_CONFIG in config.phoenix. This will mark this account as being used for MCALIB production. The phoenix tool then uses the config file as defined by this key, instead of the normal config.phoenix which is reserved for IDP configuration. The key should be set to config.phoenix_mcal.
- Fill that config file with the configuration for the MCALIB production, while you keep config.phoenix for the (follow-up) IDP production.
- In addition, the resource file ~/.dfosrc_X needs to be defined. This file is always sourced by phoenix when it is called in MCALIB mode (with option -X).
For instance, you need to keep the $DFO_CAL_DIR for IDPs (which is just a storage area for downloads) separate from the one for MCALIBs (where it is the main product area from where you want to ingest into the archive). See below for more details. |
DEEP mode: There is a special mechanism to define a separate workspace for phoenix running in DEEP mode, and also to tell the tool to use certain reserved configuration keys:
- Define the config key DEEP_CONFIG in config.phoenix which should be set to config.phoenix_deep.
- Fill that config file with the configuration for the DEEP production. You can create it as a copy of config.phoenix and then add a few specific keys.
- Define the resource file ~/.dfosrc_deep. It is listed in the config file and is sourced to define the workspace for DEEP.
The phoenix tool auto-recognizes the DEEP mode because it is called with the parameter -r <run_id>. |
B) Data directories
IDP mode: The data directories are split by PHOENIX instrument. As per standard IDP installation, all products go to $DFO_SCI_DIR, all logs to $DFO_LOG_DIR
and all QC reports to $DFO_PLT_DIR. There is also the $DFO_MON_DIR hosting the reprocessing
history (in $DFO_MON_DIR/FINISHED).
In COMPLETE mode, there is also the $DFO_CAL_DIR tree used to store the new master calibrations. |
MCALIB mode: All fits products go to $DFO_CAL_DIR which needs to be different from the one for the IDP production. Also, $DFO_LOG_DIR, $DFO_PLT_DIR and $DFO_MON_DIR should be separated from the respective IDP directories. $HOME, $DFO_HDR_DIR, $DFO_LST_DIR can be the same. |
| DEEP mode: All fits products go to $DFO_SCI_DIR which needs to be different from the one used for the IDP production. Also, $DFO_LOG_DIR and $DFO_PLT_DIR need to be separated from any other IDP directories. |
C) Tools
For the pipeline, check $HOME/.esorex/esorex.rc to contain the
proper pipeline version in the key esorex.caller.recipe-dir. Make sure to specify all pipelines needed, including the generic one (HDRL) if appropriate.
The PHOENIX process requires a tool set which consists of a stripped-off version of the DFOS tools, and of some tools dedicated to the PHOENIX workflow. The most important key in the .dfosrc file of a PHOENIX installation is the key THIS_IS_PHOENIX which is set to YES for a PHOENIX installation (while it does not exist for a DFOS installation).
For a PHOENIX MCALIB installation, you also need the key THIS_IS_MCAL set to YES.
The installation is monitored by the standard tool dfosExplorer which is reading THIS_IS_PHOENIX and, if YES, downloads a reference file appropriate for PHOENIX (and different from a DFOS installation). The DFOS tools required for a PHOENIX installation are all evaluating the key THIS_IS_PHOENIX.
Only a subset of DFOS tools (blue in the following table) is needed for PHOENIX, plus some special tools (red):
| tool |
config file |
comments |
| phoenix |
config.phoenix |
|
| pgi |
|
optional, instrument-specific PGIs to control and fine-tune the workflow |
| Examples for UVES: |
pgi_phoenix_UVES_AB |
|
configured as AB_PGI in config.phoenix, to edit ABs |
pgi_phoenix_UVES_MCAL |
|
configured as HDR_PGI in config.phoenix, to update downloaded
MCALs for header issues |
pgi_phoenix_GEN_ERR |
|
configured as FINAL_PLUGIN in config.processAB, to suppress
error messages from the QC procedures spoiling the processing log |
pgi_phoenix_UVES_ABSCELL |
|
configured as COMMON_PLUGIN in config.processAB,
to manage the PRO.CATG of ABSORPTION_CELL data properly |
pgi_phoenix_UVES_AIRM |
|
configured as PRE_PLUGIN in config.processAB, to fix missing TEL.AIRM.START/END keys in raw files |
| |
|
|
| [createAB |
standard; OCA can be versioned |
for MCALIB production or COMPLETE mode only] |
| [filterRaw |
standard |
for MCALIB production or COMPLETE mode only] |
| getStatusAB |
standard |
PHOENIX-aware: the TAB files are created
by phoenix; historical scores added for MCALIB mode and COMPLETE mode |
| createJob |
standard |
|
| ngasClient |
|
|
| processAB |
standard |
configure COMMON_PLUGIN and FINAL_PLUGIN; make sure to configure all SCIENCE
(and/or CALIB if applicable) RAW_TYPEs |
| processQC |
standard |
configure QCBQS_TYPE=PAR; make sure to configure all SCIENCE (and/or CALIB if applicable) RAW_TYPEs |
| moveProducts |
standard |
make sure to configure all SCIENCE (and/or CALIB if applicable) RAW_TYPEs |
| renameProducts |
standard |
for MCALIBs: config files can be versioned |
| ingestProducts |
standard |
to use idpConvert_xx and call_IT for the ingestion of
the IDPs; configure PATH_TO_IT and PATH_TO_CONVERTER |
| [idpConvert_xx |
|
instrument specific conversion tool, for IDPs only] |
| [call_IT |
|
wrapper for phase3 ingestion tool, for IDPs only] |
| finishNight |
|
|
| cleanupProducts |
|
for IDP: cleans $DFO_SCI_DIR/<date>/conv (fits-->hdr; symlinks for graphics); empties $DFO_SCI_DIR/<date>
for MCALIB: like for DFOS
for DEEP: like for IDP |
| getObInfo |
|
for OB-related nightlog information |
| phoenixMonitor |
config.phoenixMonitor |
adapted from histoMonitor for PHOENIX process |
| mucMonitor |
|
|
| dfoMonitor |
standard |
PHOENIX-aware: autoDaily etc. checks removed |
| createReport |
standard |
called only if no data report found on $DFO_WEB_SERVER |
| dataLoader |
standard |
same |
| calSelector |
standard |
required for COMPLETE mode, or the normal IDP mode used after 2020-12-01 |
D) Multi-instance processing (MASTER/SLAVE model).
For heavy processing tasks, it might be useful to have multiple phoenix accounts on different machines. This is currently the case for MUSE, where historically up to 4 accounts on 4 machines were used. All accounts use the same tools and configuration (with the exception of a few keys that specify accounts).
All accounts can run independently, from AB downloads up to ingestion. Only when it comes to the final step (cleanupProducts), it is important to join the bookkeeping information (so far by account) on a central installation. This is called the MASTER. The other account are called the SLAVEs.
To define the SLAVE, use the keys IS_SLAVE, MASTER_ACCOUNT, SLV_ROOT and MST_ROOT in config.phoenix.
To define the MASTER, no additional phoenix configuration is necessary (but for config.phoenixMonitor).
Logs
The process log is created per standard execution (-d <date>). It goes to the command line
and is stored under $DFO_MON_DIR/AUTO_DAILY/phoenix_<date>.log (in analogy to autoDaily logs).
Output of phoenix tool
IDP mode:
- SCIENCE (or ANY, if DP_CATG=ANY) products in $DFO_SCI_DIR/<date> (fits files),
ready to be picked up by ingestion or conversion tool
- ancillary information in $DFO_LOG_DIR/<date>: AB, alog,
rblog etc., exported to qcweb
- QC reports in $DFO_PLT_DIR/<date>, also exported to qcweb
- processing logs in $DFO_MON_DIR/AUTODAILY (!)
- statistics in $DFO_MON_DIR/PHOENIX_DAILY_<RELEASE>
- ingestion calls in $DFO_JOB_DIR/JOBS_INGEST
if COMPLETE_MODE=YES:
- CALIB products in $DFO_CAL_DIR/NEW/<dates> where <civil_dates> refers to their logical (real) dates, which might differ from the date called for science
- ancillary information as above
if CREATE_SCIAB=YES:
- new ABs, alog, rblog etc., exported to qcweb
|
MCALIB mode:
- MCALIB products in $DFO_CAL_DIR/<date> (fits files),
ready to be ingested in the normal way
- ancillary information in $DFO_LOG_DIR/<date>: AB, alog,
rblog etc., also exported to qcweb
- QC reports in $DFO_PLT_DIR/<date>, also exported to qcweb
- processing logs in $DFO_MON_DIR/AUTODAILY
- statistics in $DFO_MON_DIR/PHOENIX_DAILY_<RELEASE>
- ingestion calls in $DFO_JOB_DIR/JOBS_INGEST
|
DEEP mode:
- the same as for the IDP mode, with $DFO_SCI_DIR etc. separated from the IDP installation and defined in .dfosrc_deep.
|
How to use
Type
phoenix
-h for on-line help, and
phoenix
-v for the version number.
| IDP mode: |
|
phoenix -d <date> |
process all SCIENCE ABs for a specified
date |
phoenix -m <month> |
process all SCIENCE ABs for a specified month (in a loop over all
dates) (steps 1-3 not available for MUSE) |
phoenix -d <date> -C |
download & filter all ABs (step 1 only) |
phoenix -d <date> -P |
download & filter & process all ABs (steps 1 and 2) |
phoenix -d <date> -M |
call moveProducts (step 3 only, requires steps 1 and 2 executed before) |
| |
Note: all three options C|P|M also work with -m <month> |
| phoenix -d <date> -M -n |
same, but no cleanup of mcalibs done (useful in dry runs) |
|
phoenix -d <date> -p
|
process all ABs as filtered with config.phoenix; no update of processing
statistics (aiming at partial reprocessing of data after an issue has been discovered
and fixed) |
finishNight -d <date> -c |
cleanup all remnants of date (only needed in manual use, if options
-C or -P have been called before) |
| |
| MCALIB mode: |
|
phoenix -X -m <month> |
create and process all CALIB ABs for a specified month (for a given pool), steps 1-3 |
phoenix -X -m <month> -C [-x] |
create all CALIB ABs (step 1 only) (with -x you control that the HISTO information is kept in $DFO_AB_DIR/HISTO, otherwise it gets removed at the end of a month; useful if you process multiple months; for the HISTO information see here) |
phoenix -X -m <month> -P [-x] |
create & process all CALIB ABs (steps 1 and 2) (with -x option as before) |
phoenix -X -m <month> -M |
call moveProducts (step 3 only, requires steps 1 and 2 executed before) |
finishNight -d <date> -c |
same as above |
| phoenix -X -d <date> [-C|-P|-M] |
exceptionally you can also call the tool in X mode by date, but then you might end up with incomplete ABs because, in mode -X, the VCAL directory always needs to be erased before a new call |
| |
| DEEP mode: |
|
phoenix -r <run_ID> |
process all SCIENCE ABs for a specified
run_ID (e.g. -r 094.D-0116A) |
phoenix -r <run_ID> -C |
download & filter all ABs for the specified run (step 1 only) |
phoenix -r <run_ID> -P |
download & filter & process all ABs (steps 1 and 2) |
phoenix -r <run_ID> -M [-n] |
call moveProducts (step 3 only, requires steps 1 and 2 executed before); flag -n: no cleanup of mcalibs done (useful if several ABs need to processed one after the other) |
phoenix -r <run_ID>
-a <ab name> -C|-P |
same as above, for one deep AB only (one target); options C|P also work with -a <ab> and can accumulate ABs (for very large runs); option -M will ask user then whether to work on the last AB only or on all accumulated ones |
Use the various options on the command-line. In mass production, when you use phoenix for reprocessing
of historical data, you may want to use it typically like that:
IDP mode:
a) standard mass production, full steam:
phoenix -m 2005-09
phoenix -m 2005-08
phoenix -m 2005-07
phoenix -m 2005-06
phoenix -m 2005-05
[this mode is not available for MUSE, because of its high data volume and long execution times; always use daily mode here]
b) more careful: chance to review products, fine-tune scoring etc.
phoenix -m 2005-09 -P
phoenix -m 2005-08 -P
phoenix -m 2005-07 -P
phoenix -m 2005-06 -P
phoenix -m 2005-05 -P
... and later, after review, replace -P by -M.
c) even more careful, check content of ABs, explore data history etc.:
phoenix -m 2005-09 -C
phoenix -m 2005-08 -C
phoenix -m 2005-07 -C
phoenix -m 2005-06 -C
phoenix -m 2005-05 -C
... and then, after review, replace -C by -P, and then -P by -M.
In either case, the JOBS_INGEST file needs to be executed ultimately, off-line.
|
MCALIB mode:
standard mass production, full steam:
phoenix -m 2005-09 -X
phoenix -m 2005-08 -X
phoenix -m 2005-07 -X
phoenix -m 2005-06 -X
phoenix -m 2005-05 -X
... and all other cases just like above, always adding '-X'. |
DEEP mode:
if managable in terms of required disk space:
phoenix -r 296.C-0123B -P and then -M
and then the next runID.
if not:
phoenix -r 296.C-0123B -a <dpc AB> -C/-P and then -M; and then for the next AB etc.
|
Pseudo dates
DEEP mode:
The fundamental data pool for the DEEP mode is the run_ID, while the date is almost meaningless. Since most dfos tools, and also phoenix, are designed around the concept of a day, the pseudo-date has been developed. It maps the run_ID to the date format:
094.A-0116A --> 1094-01-16
094.A-0116B --> 2094-01-16
295.B-5985A --> 1295-59-85
060.D-9337E --> 5060-93-37
This is the mapping scheme: |
| OLD format (all cases before P105): 295.B-5985A --> A295-59-85 --> 1295-59-85 |
NEW format (all cases for P106+): 106.20CY.002 --> 2106-20-CY |
- the last character (A,B,...) is moved to the first position and then mapped into a number (A-->1, B-->2 etc.);
- the first character behind the point has no particular relevance and is dropped;
- the dot is dropped;
- the 4digit proposal ID is converted into a pseudo month and day.
|
- the last digit (1,2,...,0) is moved to the first position, hoping there is no more than 10 runs per programme;
- the 3digit period follows;
- the 4char proposal ID (unique forever) is converted into a pseudo month and day, preserving characters if existing.
|
| This scheme is unambiguous for all practial purposes. It is visible, e.g., on the AB monitor, and in the $DFO_LOG_DIR and $DFO_PLT_DIR subdirectories. It is also used inside the ABs, where the pseudo dates are used as DATE, while the real date is stored as CIVIL_DATE. |
OCA rules and data pool
|
IDPs, if COMPLETE_MODE=YES:
OCA rules can be versioned both for the CALSELECTOR and for DFOS (createAB).
The data pool for SCIENCE data is strictly daily. For CALIBs, it contains all calibs extracted from the SCIENCE data, and therefore might go beyond the SCIENCE data, to younger as well as to older dates. All such CALIBs are processed under the nominal SCIENCE data. |
IDPs, if CREATE_SCIAB=YES:
OCA rules can be versioned both for the CALSELECTOR and for DFOS (createAB). The versioning applies beyond the configured DATE for AB creation (DFOS_NOAB_DATE, 2020-12-01 by default). |
| MCALIBs:
An important concept required for the MCALIB production is the data pool. For MCALIBs, the ABs for processing need to be created using OCA rules, defining the calibration cascade with its data types, dependencies and validities. These OCA rules are derived from the operational rules, but they can be stripped-off versions, focusing on the instrument mode of the project. Also, only the data types need to be included that are relevant for the (follow-up IDP) science reduction.
It is possible (and often needed) to maintain several versions of those rules, depending on the data history. The OCA rule versioning is configured in the config file.
In general, calibrations are not taken every day, and some are not even taken at regular intervals, but maybe driven by science observations, or by scheduling constraints or ambient conditions (like twilight flats). Therefore, working on a day-by-day basis is the wrong strategy for MCALIBs. Instead, phoenix works on a data pool which is considerably larger than a day, namely a month. In general this data pool size is a good compromise between validity issues (we want to avoid too small pool sizes which by chance have important calibrations missing) and performance issues (like number of ABs and products, disk space, which all grow with pool size). To find a solution for the latter issue, the user can decide to choose smaller slices of a month, namely POOL_SIZE=10/15/30 days. The tool is then still called by month, but 3 times/2 times/once for the appropriate time range.
In general there is no overlap between different pools: calibrations for month 2005-01 are processed independently from the ones in 2005-02. This is mainly done for simplicity, and is also true for the pool slices. There is no VCAL memory in phoenix beyond the execution of a month. All VCALs are erased before createAB is called, otherwise the VCAL management would become very difficult and error-prone. One could e.g. not work on a month 2005-01 and immediately afterwards on 2008-08, which is however often needed for MCALIB production. |
RELEASE definition
The configuration key RELEASE is used to define the name
of the release. While the concept of $DFO_INSTRUMENT and $PROC_INSTRUMENT relates to the
instrument-specific aspects of the processing (like definition of RAW_TYPEs), the RELEASE
defines the logics of the (re)processing. It describes aspects like "this is the reprocessing
version 2 of all UVES ECHELLE data" where this current reprocessing scheme includes certain
pipeline parameter choices, or improved reduction strategies as opposed to e.g. version
1.
The RELEASE tag could be e.g. 'UVESR_2' where 'UVESR' stands
for 'UVES reprocessing' and '2' for the current version.
|
| For MCALIB projects, a tag like 'GIRAF_M' is reasonable where the M stands for 'master calibrations'. This tag is of course not a real release but only used to define the workspace uniquely and distinguish it from the IDP releases. (The corresponding IDP project has the release name 'GIRAF_R'.) |
| For DEEP projects, a tag like 'MUSE_DEEP' is reasonable and helps to distinguish from the classical 'MUSE_R' (OB based). |
QC procedures
While the original concept of phoenix did not include certification and scoring, it turned out that it is
extremely useful to create QC reports, mainly for the purpose of quick look. This is true for all kind of PHOENIX projects. QC reports could
also be used to e.g. quickly check that the reduction strategy is the correct one, that the
flux calibration looks reasonable etc. These QC reports can likely be easily derived from
existing, historical QC procedures for science data.
It is also extremely useful to maintain a set of QC1 parameters and store
them in a QC1 database table. This is needed for process control (for instance for proving statistically
that the SNR is correctly computed) and also for the scoring. To run a PHOENIX project without QC1 parameters, reports and scores, means essentially flying blind!
The existing IDP streams all have scoring, refer to these examples for gathering more information. Generally the scoring for IDPs, and also for MCALIBs, should focus on key parameters relevant for science reduction. They should check for saturation, negative fluxes etc. It is also a good idea to measure and score association quality, i.e. proximity in time of an IDP to a key calibration.
Technical hints:
- If you use scoring, don't forget to set the TMODE configuration key to HISTORY in your config.scoreQC, to have the red and green buttons returning useful database queries.
- Note that it is extremely useful to make the QC procedures executable
in parallel, then handled by condor in the same way as the AB pipeline jobs. Otherwise phoenix execution times will be dominated by the QC procedures (running one after the other in
an extremely inefficient way). Actually it is unclear whether phoenix will run at all with
QC procedures not enabled for parallel execution.
History scores, qualityChecker, autoCertifier (MCALIBs; for IDPs see below)
This part is relevant for MCALIBs.
phoenix has a component (embedded procedure) called qualityChecker that establishes and evaluates historical processing information. It is based on the assumption that historical processing information might be useful for the quality assessment of the MCALIB products. The historical information is automatically retrieved from a configured data source (exported $DFO_LOG_DIR on qcweb).
In the following table all conditions apply to previous (historical) processing with autoDaily for the daily QC loop. Of course this requires that historical ABs exist on qcweb, and that the information is stored in those ABs. Not finding any such information does not imply an error condition but effectively means more efforts for the current scoring. Without such current scoring, those products would need to be reviewed one by one.
The following conditions apply: |
The COMPLETE mode for IDPs uses a similar concept for presenting the historical processing, scoring and certification of the CALIB ABs. |
| |
processed |
scored |
certified |
| no info about previous processing |
0 |
. |
. |
| previous processing failed |
1 |
. |
. |
| previous processing successful |
2 |
. |
. |
| previous scoring: none |
. |
0 |
. |
| previous scoring ylw/red |
. |
1 |
. |
| previous scoring green |
. |
2 |
. |
| previous certification: none |
. |
. |
0 |
| previous rejection |
. |
. |
1 |
| previous certification |
. |
. |
2 |
These are the possible combinations:
| total history score |
conditions |
support* by new scores? |
auto-certification possible? |
| 222 |
previous processing OK, scored green, certified |
useful |
yes (even w/o new scores) |
| 022 |
no information about previous processing in the AB, but scored green+certified: likely a glitch in the AB content, handled like 222 |
useful |
yes (even w/o new scores) |
| 220 |
previous processing OK, scored green, no info about certification: handled like 222 |
useful |
yes (even w/o scores) |
| 200 |
previous processing OK, no info about scores or certification: handled like 222 |
mandatory |
yes if new scores exist and are green |
| 212 |
previous score ylw/red, certified |
very useful |
yes if new scores exist and are green |
| 211 |
previous score ylw/red, rejected: decide (put into REJ list or accept) |
very useful |
no (forced review) |
| 012/011 |
same but without processed info: glitch, same handling as 211 |
very useful |
no (forced review) |
| 202 |
processed, no scores, certified |
mandatory |
yes (trust history) |
| 201 |
processed, no scores, rejected |
mandatory |
no (review) |
| 100 |
previous failed |
mandatory |
no (review) |
| 000 |
no previous information |
mandatory |
yes (ACCEPT_NOSCORE=YES) |
* in order to be auto-certified, otherwise one-by-one assessment needed
The auto-certifier is another embedded procedure of phoenix that uses the history score, plus the current score if available, to automatically decide about certification.
These are the concepts behind the auto-certifier:
| history score |
new score |
conditions |
auto-certified? |
| 222, 022, 220 |
green |
all flags green: auto-certification safe |
yes |
| |
ylw/red |
current red scores: always review! |
no, review |
| |
none |
auto-certification a bit risky; current scoring safer (and easy since there was historical scoring!) |
yes |
| 200, 202 |
green |
previous processing OK, no info about scores or certification: handled like 222 |
yes if new scores green |
| |
ylw/red |
current red scores: always review! |
no, review |
| |
none |
auto-certification unsafe |
no, review |
| 000 |
green |
current scores green: auto-certification safe |
yes |
| |
ylw/red |
current red scores: always review! |
no, review |
| |
none |
auto-certification impossible |
no, review |
| 212/012 |
green |
previous score ylw/red but certified; could be risky |
review? (unclear what to do) |
| |
ylw/red, none |
current red scores, or no scores: review! |
no, review |
| 211, 011, 201, 100 |
any score or none |
decide (put into REJ list or accept) |
no, review |
In essence:
- if there are current green scores: always auto-certify, unless there is historical evidence about an issue;
- if there are current ylw/red scores: always review;
- if there are no current scores: auto-certify only if there is additional historical information supporting this case (but it is highly recommended to always have current scores!)
Obviously the fraction of ABs to be reviewed can be reduced drastically with a significant current scoring system. Once the current scoring system is enabled and fine-tuned, it is realistic to expect that many months completely auto-certify.
To assist with the auto-certification, the AB monitor under phoenix displays the history scores in the 'comment' column.
If the optional config key ACCEPT_NOSCORE is set to YES, then having no new score is accepted by the auto-certifier as normal behaviour (instead of an issue). This simplifies the certification of cases like KMOS_MCAL where a valid QC system with historical scores was in place from the begin on and no new scores need to be calculated. |
For IDPs (both normal and DEEP ones), there is an optional step for certification (set CERTIF_REQUIRED=YES), just before calling 'moveProducts'.
In a situation with SCIENCE ABs that are cascaded (like for MUSE), one might want to have a certification step that goes beyond the automatic scoring and includes e.g. visual inspection of the QC plots. The classical DFOS tool certifyProducts cannot be easily used for this task since it was designed for the case for CALIBs. You can call a pgi (configured under CERTIF_PGI) that you have to provide yourself (e.g. as a customized version of certifyProducts). For MUSE this exists as 'phoenixCertify_MUSE' (see here). If CERTIF_REQUIRED=YES you also need to specify CERTIF_PROCATG (the pro.catg to be certified, in case of cascaded ABs). |
| For DEEP mode, it is strongly recommended to use this mechanism for certification. |
Job execution patterns
Normally the DRS_TYPE to be chosen is CON (for condor) which can use all available cores for parallel processing, both for AB processing and for QC reports. The execution pattern is then identical to the one known from the autoDaily DFOS processing.
The following special cases exist (because standard condor processing would be too inefficient):
| 1. QCJOB_CONCENTRATION (for QC jobs and IDP processing): this is a special queue optimization to collect QC jobs for a full month (instead of daily QC jobs). It is used for efficiency if an individual QC job takes long and only few exist in daily processing: then the standard queue mechanism would be inefficient since the processing machine cannot be saturated. Efficiency gains can be as high as 30 (running 30 jobs in parallel instead of just 1). See here for more. |
2. Multi-stream processing: this is special for MUSE. The MUSE pipeline uses an internal parallelization using 24 cores at certain phases of a recipe. With a custom JOB_PGI a multi-stream processing can be set up, with N=2 (muc10) or even 3 (muc11). N ABs can run in parallel, using all available cores in parallel and delivering corresponding efficiency gains.
3. Multi-instances processing (for MUSE only): a phoenix process can be implemented on several different accounts, for gaining efficiency. While both instances can execute independently, at the end one wants to bring all relevant information to a central account, which is then the MASTER, while the other account is called the SLAVE. See here for more.
| 4. For MCALIB mode, the monthly execution pattern can be split into 1, 2, or 3 slices, of 30,15, or 10 days each. The processing jobs are split into corresponding parts and executed one after the other. |
| 5. For DEEP mode, the daily (or monthly) execution pattern is replaced by a processing by run_ID. The phoenix tool is normally called by run_ID which is the natural data organization unit then. Exceptionally (in case of very high data volume), the tool can be called for a selected target AB (extension dpc) for a given run_ID. Option -M (certification and bookkeeping) can be done for this AB only or for all ABs for a given run_ID, if they have been accumulated. Make sure to have UPDATE_YN (update an existing $DFO_SCI_DIR) set to YES! |
AB pre-selection and creation
1. Normal situation before 2020-12-01:
Normally, the AB source is the operational log directory on qcweb, created by the DFOS tools (in particular by createAB and verifyAB for SCIENCE data). For reprocessing projects, the AB source is the previous IDP project. In those cases there is no need for AB creation within phoenix.
2. Normal situation after 2020-12-01:
After that date, no SCIENCE ABs have been created any longer by the DFOS tools, due to the reorganization of QC1. The normal (IDP) mode of phoenix creates the SCIENCE ABs, using calSelector and DFOS_OPS OCA rules. This only applies if the AB source is the operational log directory on qcweb. It does not apply to reprocessing projects. The date 2020-12-01 is the default date for this breakpoint. It can be changed or configured to any date with the config key DFOS_NOAB_DATE.
3. In certain special cases the ABs are not "good enough" and need additional modifications. For DEEP projects, the deep ABs need to be created from the existing tpl ABs. This needs to be done before the PHOENIX process can start.
There are currently two main cases:
- The MUSE ABs, as created in the DFOS environment, are based on obs.start. There are many cases with irregularities, and the scheme "MUSE_smart" has been developed to prepare and deliver optimized ABs from the pool of the DFOS ABs. The optimized ABs are then the source for the PHOENIX process.
|
- For DEEP projects, there is a complex preparation process to scan all existing IDPs, sort them by runs and by targets, and then create the deep ABs by target. These ABs have the extension 'dpc' which stands for 'deep combined'.
|
Find more under the phoenix operational pages, e.g. here.
QCJOB_CONCENTRATION (IDPs only)
[This section is currently only relevant for IDPs on the giraffe_ph@muc08 account.] In normal cases the execution time for pipeline jobs (ABs) is longer than for the QC jobs, and the number of daily jobs is high enough to saturate the multi-core machine:
| 1 |
AB |
QC |
First the AB and then the QC jobs are executed; condor manages the proper distribution; the processing system is saturated, the scheduling is optimal. |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
| 6 |
|
|
| 7 |
|
|
| 8 |
|
|
| ... |
|
|
| 30 |
|
|
| 31 |
queue |
|
Once a job is finished, condor schedules the next waiting job, until the queue is empty. |
| ... |
|
|
| n |
|
|
In that regime all phoenix jobs are executed day after day, and within a day batch there is first the AB call and then the QC call. Let's call this regime the "normal condor regime".
For giraffe_ph, the situation is different: typically there are only a few jobs (let's say 2) per day, meaning the muc machine cannot saturate, most cores are idle and the processing is not optimal. Furthermore, the QC jobs take much longer than the AB jobs (because a single QC jobs actually loops over up to 130 MOS products). For this regime (let's call it the "MOS condor regime") there is a special operational setup needed to optimize the processing. It is possible only for monthly processing (because then a sufficient number of AB/QC jobs exist to saturate the muc machine). In a first step all AB jobs are processed in the "normal" way (day by day, without saturation). This is suboptimal but because of the short execution time not critical for optimization. The daily QC jobs are collected but not executed. Only after all AB jobs of the month are done, the QC jobs are executed in one big call, thereby saturating the muc machine and optimizing the processing scheme. Let's call this regime the "QC job concentration regime".
| |
day1 |
day2 |
day3 |
... |
last day |
all days of the month |
First all ABs are executed, day by day; QC jobs are collected and executed at the end, in one batch for the whole month; condor manages the proper distribution; the processing system is saturated by QC jobs, the scheduling is optimal for QC jobs. |
| 1 |
AB#1 |
AB#4 |
AB#5 |
AB#9 |
AB#43 |
QC#1 |
| 2 |
AB#2 |
|
AB#6 |
|
AB#44 |
QC#2 |
| 3 |
AB#3 |
|
AB#7 |
|
AB#45 |
QC#3 |
| 4 |
|
|
AB#8 |
|
|
QC#4 |
| 5 |
|
|
|
|
|
QC#5 |
| 6 |
|
|
|
|
|
QC#6 |
| 7 |
|
|
|
|
|
QC#7 |
| 8 |
|
|
|
|
|
QC#8 |
| ... |
|
|
|
|
|
|
| n |
|
|
|
|
|
|
In some test runs, the effective processing time for a month worth of GIRAFFE IDP processing with phoenix went down from more than 6 hours for "normal condor processing" to about 2 hours for the "QC job concentration processing".
The switch to this processing scheme is made via configuration (key QCJOB_CONCENTRATION). It can be used for any PHOENIX account, but currently makes sense for giraffe_ph only.
COMPLETE_MODE (IDPs only)
This mode is an extension of the classical IDP mode for those cases where a significant pipeline improvement merits the reprocessing of calibrations. If for certain reasons a MCAL reprocessing project is not feasible, or not desired, a more pragmatic approach is available with the COMPLETE_MODE. Here, in a first step all SCIENCE ABs for a specified DATE are retrieved. But instead of downloading the master calibrations listed in these ABs, the SCIENCE file names are extracted from the ABs, and then exposed to calSelector in raw2raw mode. This will deliver xml files with calib file names. The headers of those CALIB files are then downloaded, exposed to createAB. Finally the SCIENCE files are exposed to createAB.
Thereby, only the calibrations required for the new IDPs are re-created, and the SCIENCE ABs all point to these new masters. All products (CALIB and SCIENCE) are created with the same association scheme and latest pipeline version.
Technically, the DATE is applicable to the SCIENCE ABs only, while the CALIBs might come from other dates. They are all collected under the same 'processing date', appear on the same AB monitor. The final distribution of the new master calibrations respects the original dates.
After processing, the new masters need to be reviewed before they can be accepted (certified). As far as possible, the historical processing, scoring, and certification information is used, in the same schema as for the MCAL mode of phoenix.
If desired, the new masters can be renamed and ingested.
Since the COMPLETE_MODE is designed in particular for older dates, it supports historical versioning of the OCA and of the calSelector association schemes.
Normal mode with SCIENCE AB creation
In the classical IDP mode the ABs are downloaded from qcweb. This has several advantages: besides simplicity, this approach provides ABs from the daily workflow which have been checked for consistency with the OCA rules. After the date 2020-12-01, these ABs are no longer created and uploaded for operational reasons. Therefore, ABs as needed for IDPs have to be created within phoenix then. This applies only to IDP projects using the DFOS directory on qcweb (i.e. public_html/<instr>/logs).
The approach is rather similar to the one for the COMPLETE_MODE, but it is simpler since we don't want to recreate CALIB ABs. Instead, it is based on existing master calibrations for the desired DATE. If such masters do not exist, you cannot use phoenix in the IDP mode but you must create the masters first (either in an MCALIB project or in COMPLETE_MODE).
For the SCIENCE AB creation in normal mode, you need to prepare the configuration file config.phoenix:
- set the appropriate DATE for the breakpoint (DFOS_NOAB_DATE), from when on SCIENCE ABs must be created instead of being downloaded (default: 2020-12-01);
- specify CALSEL_OCA_RULE and make sure it is downloaded from the DFOS_OPS system into the phoenix system into the proper directory $DFO_CONFIG_DIR/CALSELECTOR;
- specify DFOS_OCA_RULE and make sure it is downloaded from the DFOS_OPS system into the phoenix system into the proper directory $DFO_CONFIG_DIR/OCA; this is the association.h file, only;
- optionally, you can set the config key CREATE_TXT_FILE to YES or NO which will create the calSelector txt files for you; these are not needed by the tool, but you may want to check them initially, and later turn them off since their creation costs some time.
It is possible to have several versions of CALSEL_OCA_RULEs and DFOS_OCA_RULEs in your system, separated by validity dates. Technically, don't forget to also have a copy of the CSConfiguration.properties file in $DFO_CONFIG_DIR/CALSELECTOR.
Also, make sure to edit config.createAB such that TOOL_MODE=AUTO, and N_MCAL_LIST=1 (because your MCAL pool is only one "pseudo-day" deep, namely the $DATE that you are using in the phoenix call).
The SCIENCE AB creation has been implemented for purely operational reasons. The process of creating SCIENCE ABs is closely connected to the QC1 process for calibrations. As such, it is migrated to the QC-v2 schema and not maintained in this form any longer. Therefore, SCIENCE ABs for the IDP production have to be created from the DFOS_NOAB_DATE on (2020-12-01).
This is achieved by the following steps:
- first, all SCIENCE files for a specified DATE are downloaded as headers;
- then they are exposed to calSelector in raw2Master mode; this will deliver xml files with mcalib file names;
- then the headers of those mcalib files are downloaded into $DFO_CAL_DIR/$DATE;
- then createAB for SCIENCE files is used to create the SCIENCE ABs.
Technically, the DATE is applicable to the SCIENCE ABs only, while the CALIBs might come from other dates.
After the SCIENCE ABs have been created, the workflow for phoenix is the same as if the ABs would have been downloaded. In particular, the next step is the application of the AB_PGI. In many cases, this important pgi might be simplified a lot once all SCIENCE ABs are created in this way and no fixes for historical content are needed anymore.
The creation of SCIENCE ABs for normal IDPs after DFOS_NOAB_DATE applies only if the ORIG_AB_DIR (the AB source) is configured to point to the DFOS ABs (public_html/$DFO_INSTRUMENT/logs). Only then we want to create ABs. If the AB source is already a previous IDP project, these ABs remain the valid source, and no creation is done within phoenix.
Ingestion
Each phoenix call results in an entry in the $DFO_JOB_DIR/JOBS_INGEST file, in the traditional
DFOS way. The standard dfos tool ingestProducts is aware of running in the phoenix environment
if
- INGEST_ENABLED is set to YES in config.phoenix
- PATH_TO_IT and CONVERTER are properly filled in config.ingestProducts.
If INGEST_ENABLED=YES, the tool is enabled to call the converter tool (optional) and the ingestionTool.
Find more about the IDP ingestion process here.
After ingestion, don't forget to call the tool cleanupProducts to replace the fits files with their extracted headers, in the standard DFOS way. For SLAVE accounts, the headers are transfered to the MASTER account, for central bookkeeping.
Installation
phoenix is required as the central tool for the PHOENIX process.
The PHOENIX process requires a customized file .dfosrc and a standard file .qcrc. The following keys are needed in .dfosrc in addition to the one used in DFOS:
| export THIS_IS_PHOENIX=YES |
YES | NO |
marking this account as PHOENIX account; many dfos tools then behave differently than in DFOS environment (optional, default=NO meaning normal DFOS) |
| export THIS_IS_MCAL=YES |
YES | NO |
for PHOENIX accounts: mark the environment for MCAL processing (YES) or IDP processing (default: NO)
Since for MCAL processing, a dedicated file .dfosrc_X
is expected, that key can be set to YES only in .dfosrc_X. Don't forget to enter 'NO' in .dfosrc (important if you switch between MCAL and IDP processing). |
The PHOENIX process requires the dfos tools listed above. That list might evolve. Please always use dfosExplorer to control your current PHOENIX installation.
The workspace as defined in the .dfosrc file is defined by $PROC_INSTRUMENT.
Configuration
files
phoenix can run several configuration files:
- the standard one, config.phoenix, is used for IDPs (always needed);
- an optional second one, either config.phoenix_mcal, or config.phoenix_deep, for the MCALIB and DEEP modes, to replace the standard one. Both have the same structure:
| name: |
config.phoenix |
config.phoenix_mcal |
config.phoenix_deep |
| used for: |
IDP mode |
|
|
| |
MCAL_CONFIG config.phoenix_mcal --> |
MCALIB mode |
|
| |
DEEP_CONFIG config.phoenix_deep --> |
|
DEEP mode |
| rc file |
.dfosrc |
MCAL_RESOURCE=.dfosrc_X |
DEEP_RESOURCE=.dfosrc_deep |
| |
switching between two different IDP releases: |
|
|
| |
OTHER_RESOURCE=.dfosrc_tell |
|
|
The name of the MCALIB config file is not hard-coded, you might use another name but it needs to be registered in the main config file under MCAL_CONFIG. In MCALIB mode, the config file config.phoenix is only read to find the MCALIB config file, no other information is used. The MCALIB config file has the same structure as the IDP config file. (This has the effect that it is very easy to use the same account for either MCALIB or IDP production, by simply switching on or off the MCAL_CONFIG key in the IDP config file.)
In DEEP mode, the same is true for the config.phoenix_deep file.
In normal IDP mode, you can turn on the COMPLETE mode by using the COMPLETE_MODE=YES key.
In the normal IDP mode, there is the additional possibility to switch to a second PHOENIX installation with OTHER_RESOURCE. This is useful e.g. for the XSHOOT_TELL stream which is a stream additional to the XSHOOT_R IDP stream. Both are running from the xshooter_ph account. The configured OTHER_RESOURCE file (if enabled) defines the directories $DFO_MON_DIR, $DFO_SCI_DIR, $DFO_LOG_DIR, $DFO_PLT_DIR to be different from the ones used for the normal IDP stream.
Both configuration files go
to the standard $DFO_CONFIG_DIR. The following configuration keys exist (a few keys are specific for a mode, they are marked below in the corresponding colours):
Section 1: GENERAL
This section controls the general tool behaviour. |
| MCAL_CONFIG (only in config.phoenix!) |
|
empty --> this is for IDP production |
| config.phoenix_mcal |
go to that one and use it for MCALIB production |
| MCAL_RESOURCE (only for MCALIBs) |
.dfosrc_X |
source this file to define the workspace for MCALIB production |
| CHECK_VCAL (only for MCALIBs) |
YES |
YES|NO (YES): send notification if no VCAL exist after running createAB (which would be indicative of an issue with /opt/dfs tools) |
| DEEP_CONFIG |
config.phoenix_deep |
go to that one and use it for DEEP production |
| DEEP_RESOURCE |
.dfosrc_deep |
source this file to define the workspace for DEEP production |
| OTHER_RESOURCE |
.dfosrc_<other> |
source this resource file and work in a different workspace than usual (for a second stream) |
| MAIL_YN |
NO |
YES|NO (NO): send notification when finished |
| UPDATE_YN |
YES |
YES|NO (YES): moveP handling of pre-existing $DFO_SCI_DIR:
update (YES)
or create from scratch |
| INGEST_ENABLED |
YES |
YES/NO (NO): enabled for IDP ingestion (requires IngestionTool and probably conversion
tool) or for MCALIB ingestion |
| The following keys apply to IDP and to DEEP but not to MCALIB. |
| ACCEPT_060 |
NO |
YES/NO (NO): --> accept PROG_IDs starting with 60. or 060. (for testing or SV runs) |
| CERTIF_REQUIRED |
NO |
YES|NO (NO): --> certification required before IDPs can be moved; if YES, custom certification tool must be defined under 2.3 (CERTIF_PGI) and provided. |
| QCJOB_CONCENTRATION |
NO |
YES/NO (NO): YES --> collect all QC jobs of a month in one single vultur_exec call, to be called after all daily AB jobs have been executed; applicable if QC jobs dominate the total execution time and if their daily number is small; more see here |
| The following keys apply to multi-instance installations (IDP or DEEP, but not MCALIB); the following four keys need to be defined for the SLAVE only: |
| IS_SLAVE |
YES |
YES/NO (NO): if YES, this is the second installation; all logs and plots information is added to qcweb, but also transfered to the MASTER account, for central bookkeeping. |
| MASTER_ACCOUNT |
muse_ph2@muc10 |
logs/plots are copied to that account (but not fits files!); after ingestion, also the IDP headers are collected there. |
| SLV_ROOT |
/fujisan3/qc/muse_ph |
root directory name for data on slave account |
| MST_ROOT |
/qc/muse_ph2 |
same, on the master account |
| for MCALIB projects: |
| POOL_SIZE |
30 |
10/15/30: pre-defined values for MCALIB processing which comes always per month |
| OCA_SCHEME |
VERSIONED |
VERSIONED|STANDARD: VERSIONED means you have OCA rules per epoch, to be defined in Sect. 2.6 (default: STANDARD) |
| RAWDOWN_SLEEP |
600 |
optional: forced sleep time between call of RAWDOWN file (in background) and start of processing; default: 60 [sec]. If too long, system is waiting idle; if too short, ABs might fail because system cannot download fast enough |
| REPLACE_LOGIC |
SELECTIVE |
SELECTIVE|COMPLETE: SELECTIVE means that already archived MCALIBs should be replaced by the same name (because then historical ABs can be used for IDP production)
COMPLETE means complete creation from scratch (because no pre-existing MCALIBs, or all have been deleted) |
|
Section 2: SPECIFIC for RELEASE
This section defines properties of the supported instrument(s).
2.1 Define RELEASE and PROC_INSTRUMENT
|
| PROC_INSTRUMENT |
UVES |
|
| #TAG |
#PROC_INSTR |
#VALUE |
|
| RELEASE |
UVES |
UVESR_2 |
uves reprocessing v2 (2000-2013+) |
| INSTR_MODE |
UVES |
UVES_ECHELLE |
instrument mode, for ingestProducts statistics |
| |
|
|
|
| #multiple entries possible: |
#PROC_INSTR |
#source |
#validity until |
#comment |
| ORIG_AB_DIR |
UVES |
public_html/UVESR_1/logs |
2007-03-31 |
source of ABs on qc@qcweb
up to until 2007-03-31 |
| ORIG_AB_DIR |
UVES |
public_html/UVES/logs |
2099-99-99 |
until CURRENT period |
The following keys apply to IDPs in COMPLETE_MODE only: |
| COMPLETE_MODE |
UVES |
YES | NO |
YES: all CALIBs required for SCIENCE are created in the first place, then SCIENCE is processed (using the new mcalibs as VIRT then); default: NO |
| COMPLETE_DATE |
UVES |
2015-06-30 |
COMPLETE_MODE=YES applied only before that date |
| COMPLETE_CALIBQC |
UVES |
YES | NO |
YES: we create new QC plots and ingest into QC1 table; default: NO |
| COMPLETE_ADD_HC_CALIBS |
UVES |
&&DPR.TYPE DET.WIN1.BINX DET.READ.SPEED INS.GRAT1.WLEN | grep WAVE | grep 346 grep 1.00&& |
define HC calibs: Add fits key names to read via fitsort, and grep conditions to extract HC calibs (multiple lines supported; all enclosed with &&...&&, last char must be &) |
| RAWFILE_SOURCE |
2004
or 2004-12
or 2004-12-23
(multiple lines supported) |
RAW_HDR |
RAW_HDR or HISTO_AB (default), applicable to selected YEAR, MONTH or DATE;
HISTO_AB means: take the historical ABs from ORIG_AB_DIR as configured above, extract the raw science files and then use CalSelector+ABbuilder to create new ABs (CALIB and SCIENCE);
RAW_HDR means: take the raw hdr directory for extraction of raw science files (because no historical ABs exist) |
| CAL_ORIG_AB_DIR |
UVES |
public_html/UVES/logs |
original source for historical CALIB QC info (scores) |
| CAL_ORIG_PLT_DIR |
UVES |
public_html/UVES/plots |
original PLOT_DIR for historical CALIB QC info (QC plots) |
| CREATE_TXT_FILE |
UVES |
YES|NO |
YES: txt files created by CalSelector for better readibility (otherwise XML only); optional, default=NO |
| # list of versioned calSelector OCA rules (2099-99-99 always stands for 'until now and into the future') |
| #CALSEL_OCA_RULE |
#PROC_INSTR |
#source |
#validity until |
#comment |
| CALSEL_OCA_RULE |
UVES |
UVES_raw2master.2004-10-02.RLS |
2007-03-31 |
downloaded and edited for SCIENCE phoenix processing case |
| CALSEL_OCA_RULE |
UVES |
UVES_raw2master.2007-04-01.RLS |
2099-99-99 |
same |
| # list of versioned DFOS OCA rules (association part) |
| #DFOS_OCA_RULE |
#PROC_INSTR |
#source |
#validity until |
#comment |
| DFOS_OCA_RULE |
UVES |
UVES_association.h_early |
2007-03-31 |
early associations |
| DFOS_OCA_RULE |
UVES |
UVES_association.h_current |
2099-99-99 |
current associations |
NEW with v4.1:
The following keys apply to IDPs in normal mode, for SCIENCE AB creation: |
| DFOS_NOAB_DATE |
GIRAFFE |
2020-12-01 |
for DATEs beyond that date, ABs are created instead of downloaded, if the applicable ORIG_AB_DIR is public_html/GIRAFFE/logs in this example (default: 2020-12-01) |
| CREATE_TXT_FILE |
GIRAFFE |
YES|NO |
YES: txt files created by CalSelector for better readibility (otherwise XML only); optional, default: NO |
| # list of versioned calSelector OCA rules (2099-99-99 always stands for 'until now and into the future') |
| #CALSEL_OCA_RULE |
#PROC_INSTR |
#source |
#validity until |
#comment |
| CALSEL_OCA_RULE |
GIRAFFE |
GIRAFFE_raw2master.2008-04-01.RLS |
2099-99-99 |
downloaded and edited for SCIENCE phoenix processing case |
| # list of versioned DFOS OCA rules (association part) |
| #DFOS_OCA_RULE |
#PROC_INSTR |
#source |
#validity until |
#comment |
| DFOS_OCA_RULE |
GIRAFFE |
GIRAFFE_association.h_current |
2099-99-99 |
current DFOS associations |
2.2 Definition of RAW_TYPEs as used in the ABs
|
Needed for IDPs only; for MCALIBs this part is ignored and replaced by the RAW_TYPEs in the OCA rule.
Multiple entries possible; in case it matters, ABs get processed in the sequence of this configuration. |
| RAW_TYPE |
UVES |
SCI_POINT_ECH_BLUE |
|
| RAW_TYPE |
UVES |
SCI_POINT_ECH_RED |
|
| DP_CATG |
XSHOOTER |
ANY|SCIENCE |
SCIENCE by default; ANY if processing should be opened to all configured RAW_TYPEs, independent of SCIENCE or CALIB |
2.3
Definition of pgi's and SUPPRESS_DATE
(all optional) |
| |
|
|
|
| DATA_PGI |
VIMOS |
pgi_phoenix_VIMOS_fixhdr |
# optional pgi for ins-specific header manipulation (under $DFO_BIN_DIR); for MCAL mode only |
| AB_PGI |
UVES |
pgi_phoenix_UVES_AB_760 |
# optional pgi for ins-specific AB manipulation (under $DFO_BIN_DIR) |
| HDR_PGI |
UVES |
pgi_phoenix_UVES_MCAL |
# optional pgi for ins-specific header manipulation, called in MCALDOWNFILE
(under $DFO_BIN_DIR) |
| JOB_PGI |
MUSE |
pgi_phoenix_MUSE_stream |
# optional pgi for managing the process streams in MUSE-like environments (non-condor) |
| MULTI_STREAM |
MUSE |
3 |
# optional, for managing the processing streams in MUSE-like environments (non-condor) (note: only used by JOB_PGI and by post-processing pgi of processAB, NOT by phoenix itself) |
| CERTIF_PGI |
MUSE |
phoenix_certifyP_MUSE |
# if CERTIF_REQUIRED=YES: pgi for ins-specific certification, to be provided under $DFO_BIN_DIR |
| CERTIF_PROCATG |
MUSE |
PIXTABLE_REDUCED |
# if CERTIF_REQUIRED=YES: pro.catg to be called for certification |
| MON_PGI |
XSHOOTER |
pgi_phoenix_XSHOOTER_getTell |
# optional, to be called after phoenixMonitor (in this example: tool to sort XSHOOT_TELL results by target) |
| |
|
SUPPRESS_DATE
|
UVES |
2008-03-25 |
# optional; list of dates to be avoided (because of e.g. very high number of
ABs) in monthly execution mode
|
| AB_FILTER_COMMENT |
[RELEASE:] GIRAF_STACK |
&&For better overview, enter 1001 to see the master ABs only&& |
# optional, used by getStatusAB; this free text is displayed on the AB monitor as info for the search window; enclosed by &&...&& |
2.4 SETUP filter |
|
#SETUP filter (multiple): positive list: only the listed setups get
processed (useful only for selective reprocessing of certain setups)
|
| SETUP |
UVES |
_346 |
string, evaluated from SETUP keys in ABs |
| etc. |
|
|
|
2.5 RENAMING scheme (MCALIBs only) (in order to match historical naming scheme, you may need to support versioning here; not needed for IDPs) |
| #RENAME |
#RELEASE |
#config filename |
#valid until |
#comment |
| RENAME |
GIRAF_M |
config.renameProducts_2009 |
2009-12-31 |
#old schema, with one read mode only |
| RENAME |
GIRAF_M |
config.renameProducts_CURRENT |
2099-99-99 |
#current schema |
2.6 OCA scheme (MCALIBs only) (in order to match evolution of header keys or cascade, you may need to support versioning here; not needed for IDPs; note the versioning for organization and association files!) |
| #OCA |
#RELEASE |
#organization filename |
#association filename |
#valid until |
#comment |
| OCA |
GIRAF_M |
GIRAFFE_organization.h_first |
GIRAFFE_association.h_first |
2004-04-01 |
first half year had no INS.EXP.MODE |
| OCA |
GIRAF_M |
GIRAFFE_organization.h_second |
GIRAFFE_association.h_second |
2008-05-01 |
old CCD: some old static tables don't work with PREVIOUS rule |
| OCA |
GIRAF_M |
GIRAFFE_organization.h_curr |
GIRAFFE_association.h_curr |
2099-99-99 |
new CCD: current OCA rule, edited for applicable raw_types |
2.7 Handling of noscores in auto-certifier (MCALIBs only) (for situations where no scoring is foreseen, e.g. complete reprocessing of data with a good QC system, driven by pipeline format changes)
|
| ACCEPT_NOSCORE |
YES|NO |
YES: having no score is not considered an issue; default: NO |
In addition to the phoenix configuration file(s), there are also the config files for the DFOS tools called. For the modes using calSelector (COMPLETE_MODE and normal IDP mode with DFOS_NOAB_DATE set), don't forget to provide the CSConfiguration.properties file in $DFO_CONFIG_DIR/CALSELECTOR (take it from your DFOS account). For the normal IDP mode with DFOS_NOAB_DATE set, don't forget to set N_MCAL_LIST=1.
Operational plug-ins (PGIs)
phoenix is a standard workflow tool. Usually instruments have a certain range of peculiarities which need to be handled via plug-ins (PGI's). This concept has proven useful for the daily workflow with autoDaily, and it is also used here. Some PGIs are configured directly in config.phoenix (or config.phoenix_mcal), others are PGIs for a specific dfos tool and are configured in their respective config files. All PGI's are expected under $DFO_BIN_DIR. Here is a list of PGIs directly related to phoenix:
phoenix PGI's |
| pgi |
name (examples) |
purpose |
| DATA_PGI |
pgi_phoenix_VIMOS_fixhdr |
ins-specific header manipulation; for MCAL mode only (example: replace indexed INS.FILT<n>.NAME by INS.FILT.NAME etc.); rarely needed, for cases that are in conflict with data flow rules |
| AB_PGI |
pgi_phoenix_GIRAFFE_AB |
for ins-specific AB manipulation; very important for IDP mode: it handles the historical evolution of ABs and makes them uniform and compatible with the current pipeline; it might even generate ABs (from existing information but it cannot replace createAB) |
| HDR_PGI |
pgi_phoenix_UVES_MCAL |
for ins-specific header manipulation of downloaded mcalib file, called in MCALDOWNFILE |
| JOB_PGI |
pgi_phoenix_MUSE_stream |
for managing the process streams in MUSE-like environments (non-condor) |
| CERTIF_PGI |
phoenixCertif_MUSE |
for ins-specific IDP certification (if CERTIF_REQUIRED=YES) |
| MON_PGI |
pgi_phoenix_XSHOOTER_getTell |
provide non-standard bookkeeping for phoenixMonitor |
Operational
workflow description
See also here.
| A1) IDP mode (basic operational mode: per date or per month) |
| Download ABs: DFOS_NOAB_DATE not set, or DATE is before DFOS_NOAB_DATE, or this is a reprocessing project |
Create ABs: DFOS_NOAB_DATE is set, and DATE is after DFOS_NOAB_DATE, and this is not a reprocessing project |
0. Prepare: source .dfosrc; if OTHER_RESOURCE is configured, source that file.
1. Get ABs (for -C, -P, and full execution)
1.1 check if DATE is configured as SUPPRESS_DATE; if so, exit
1.2 download all ABs/ALOGs from configured data source (ORIG_AB_DIR on qc@qcweb)
1.3 filter the ABs:
1.3.1 filter for SCIENCE (unless DP_CATG=ANY); if none found, exit
1.3.2 filter for configured RAW_TYPEs; if none remain, exit
1.3.3 filter for configured SETUPs; if none remain, exit
1.4 clean&move ABs
1.4.1 remove obsolete content (RB_CONTENT, PRODUCTS, FURTHER)
1.4.2 apply AB_PGI
1.4.3 move them to $DFO_AB_DIR
1.4.4 create AB_LIST
2. Prepare job file (for -C, -P, and full execution)
2.1 create TAB files if not yet existing
2.2 call 'getStatusAB'
2.3 call 'createJob', apply JOB_PGI
2.4 add the mcalDown file to the JOB_FILE (createJob doesn't do it for mode SCIENCE)
2.5 do some manipulations to the JOB_FILE
End of step 1; stop here for -C |
0. Prepare: source .dfosrc; if OTHER_RESOURCE is configured, source that file.
1. Create ABs (for -C, -P, and full execution)
1.1 check if DATE is configured as SUPPRESS_DATE; if so, exit
1.2 download all headers for DATE
1.3 create SCIENCE ABs
1.3.1 call calSelector in raw2Master mode and create XML files
1.3.2
scan XML files for list of mcalibs
1.3.3 download all mcalib headers into $DFO_CAL_DIR/$DATE
1.3.4 call createAB -m SCIENCE -d $DATE
1.4 manage ABs
1.4.1 obsolete
1.4.2 apply AB_PGI
1.4.3 move them to $DFO_AB_DIR
1.4.4 create AB_LIST
2. Prepare job file (for -C, -P, and full execution)
2.1 create TAB files if not yet existing
2.2 call 'getStatusAB'
2.3 call 'createJob', apply JOB_PGI
2.4 add the mcalDown file to the JOB_FILE (createJob doesn't do it for mode SCIENCE)
2.5 do some manipulations to the JOB_FILE
End of step 1; stop here for -C |
3. Call JOBS_FILE (for -P and for full execution)
3.1 call the AB and then the QC queue (unless in monthly mode QCJOB_CONCENTRATION=YES: then all AB queues are called, then the single QC queue)
3.2 check for failures; if found, send an email
3.3 stop here if -P is set (you could now investigate the products, fine-tune QC reports
etc.)
End of step 2; stop here for -P
Begin of step 3; enter for -M and for full execution
4. [optional: call CERTIF_PGI for certification]
5. Call moveProducts
5.1
call moveProducts -d <date> -m SCIENCE, including renameProducts
6. cleanup (finishNight)
5.1 manage content of $DFO_CAL_DIR (dates beyond +/-28d of current date are deleted; if
number of files in 2099-99-99 exceeds 1000, they get deleted)
5.2 call finishNight -d <date>
5.3 if this is a SLAVE account: transfer logs, plots and other information to the MASTER account
5.4 call phoenixMonitor
5.5 if configured, call MON_PGI
|
A2) IDP mode with COMPLETE_MODE=YES
0. Prepare: source .dfosrc; if OTHER_RESOURCE is configured, source that file.
1. Get all ABs (for -C, -P, and full execution)
1.1 check if DATE is configured as SUPPRESS_DATE; if so, exit
1.1.1 download all headers if not yet existing
1.2 download all SCIENCE ABs/ALOGs from configured data source (ORIG_AB_DIR on qc@qcweb)
1.3 filter the SCIENCE ABs:
1.3.1 filter for SCIENCE (unless DP_CATG=ANY); if none found, exit
1.3.2 filter for configured RAW_TYPEs; if none remain, exit
1.3.3 filter for configured SETUPs; if none remain, exit
1.4 COMPLETE_MODE=YES: find CALIBs required for SCIENCE ABs
1.4.1
extract list of science files for CalSelector call
1.4.2
call CalSelector Raw2Raw
1.4.3 extract list of calibs from xml files
1.4.4
download raw calib headers, remove the ones configured as HC calibs
1.4.5 call createAB to create the CALIB ABs
1.4.6 call createAB to create the SCIENCE ABs
1.5 clean&move ABs
1.5.1 apply AB_PGI
1.5.2 move them to $DFO_AB_DIR
1.5.3 create AB_LIST
1.5.4
retrieve historical CALIB AB comments, scores, certification info
2. Prepare job file (for -C, -P, and full execution)
2.1 call 'getStatusAB'
2.2 call 'createJob' for CALIB & SCIENCE, apply JOB_PGI
2.3 add the mcalDown file to the JOB_FILE
2.4 do some manipulations to the JOB_FILE
End of step 1; stop here for -C
3. Call JOBS_FILE (for -P and for full execution)
3.1 call the AB queues (CALIB, then SCIENCE), and then the QC queue
3.2 check for failures; if found, send an email
3.3 call qualityChecker (evaluate historical scores and current information)
3.4 stop here if -P is set (you could now investigate the products, fine-tune QC reports
etc.)
End of step 2; stop here for -P
Begin of step 3; enter for -M and for full execution
4. Call qualityChecker and autoCertifier for CALIBs
5. Call moveProducts
5.1
call moveProducts -d <date> -m CALIB, including renameProducts
5.2
call moveProducts -d <date> -m SCIENCE, including renameProducts
6. cleanup (finishNight)
5.1 manage content of $DFO_CAL_DIR (dates beyond +/-28d of current date are deleted; if
number of files in 2099-99-99 exceeds 1000, they get deleted)
5.2 call finishNight -d <date>
5.3 call phoenixMonitor
5.4 if configured, call MON_PGI
|
B) MCALIB mode (basic operational mode: per month)
0. Prepare:
0.1 read MCAL_CONFIG in config.phoenix
0.2 use the new config file
0.3 source the configured MCAL_RESOURCE
1. Create ABs (for -C, -P, and full execution)
1.1 Find the monthly pattern from config file (batches of 10/15/30 days)
1.2 check for SUPPRESS_DATE, exclude it
1.3 download headers as required; call DATA_PGI if configured
1.4 filter headers for:
1.4.1 hidden files (remove them)
1.4.2 previously rejected files (remove them)
1.5 Create ABs
1.6 Filter ABs for
1.6.1 HC calibrations (RAW_MINNUM etc., using filterRaw)
1.6.2
configured SETUPs (remove ABs)
1.7 apply AB_PGI; then
1.7.1 move them to $DFO_AB_DIR
1.7.2 create AB_LIST
1.8 Catch historical information:
1.8.1 AB comments
1.8.2 historical processing, scoring, certification information
1.8.3 if called with -x, previous content is kept, otherwise it is deleted
2. Prepare job file (for -C, -P, and full execution)
2.1 call getStatusAB
2.2 call 'createJob'
2.3 do some manipulations to the JOB_FILE
End of step 1; stop here for -C
3. Call JOBS_FILE (for -P and for full execution)
3.1 call the AB and then the QC queue
3.2 check for failures; if found, send an email
3.3 call qualityChecker (evaluate historical scores and current information)
3.3 stop here if -P is set (you could now investigate the products, fine-tune QC reports
etc.)
End of step 2; stop here for -P
Begin of step 3; enter for -M and for full execution)
4. Call autoCertifier (in automatic mode, continue only if no issue occurred; in -M mode, offer issues for review); end of monthly mode
5. Daily loop: call moveProducts
5.1 call moveProducts -d <date> -m SCIENCE, including renameProducts
5.2 apply naming scheme checker, leave issues for clarification
6. Call finishNight
6.1 call finishNight -d <date>
6.2 update phoenixMonitor
6.3 if configured, call MON_PGI
7. Clean-up products
7.1 Call JOBS_CLEANUP for the stream
7.2 Call 'cleanupProducts -E' for the batch
|
C) DEEP mode (basic operational mode: per run_ID)
0. Prepare:
0.1 read DEEP_CONFIG in config.phoenix
0.2 use the new config file
0.3 source the configured DEEP_RESOURCE
1. Get ABs (for -C, -P, and full execution)
1.1 download all ABs/ALOGs from configured data source (ORIG_AB_DIR on qc@qcweb)
1.2 clean&move ABs
1.2.1 remove obsolete content (RB_CONTENT, PRODUCTS, FURTHER)
1.2.2 apply AB_PGI
1.2.3 move them to $DFO_AB_DIR
1.2.4 create AB_LIST
2. Prepare job file (for -C, -P, and full execution)
2.1 create ATAB files
2.2 call 'getStatusAB'
2.3 call 'createJob', apply JOB_PGI
2.4 add the mcalDown file to the JOB_FILE (createJob doesn't do it for mode SCIENCE)
2.5 do some manipulations to the JOB_FILE
End of step 1; stop here for -C
3. Call JOBS_FILE (for -P and for full execution)
3.1 call the AB and then the QC queue
3.2 check for failures; if found, send an email
3.3 stop here if -P is set (you could now investigate the products, fine-tune QC reports
etc.)
End of step 2; stop here for -P
Begin of step 3; enter for -M and for full execution
4. [optional: call CERTIF_PGI for certification]
5. Call moveProducts
5.1 call 'moveProducts -d <pseudo_date> -m SCIENCE', including renameProducts
6. cleanup (finishNight)
5.1 manage content of $DFO_CAL_DIR (delete all pseudo-dates unless option -m is called)
5.2 call finishNight -d <pseudo_date>
5.3 if this is a SLAVE account: transfer logs, plots and other information to the MASTER account
5.4 update 'phoenixMonitor'
5.5 if configured, call MON_PGI
|
Self-management
of $DFO_CAL_DIR and $DFO_RAW_DIR, and the other DFO directories with permanent data
Although the data disks on the phoenix machines are big (7-10 TB), it is reasonable to constrain the size of
these data directories. Here is a description of the applied strategies (same strategy applies for IDPs, MCALIBs and DEEP unless otherwise noted):
$DFO_HDR_DIR:
Filled for MCALIBs and DEEP, otherwise not needed routinely. |
$DFO_RAW_DIR:
The <date> directory is always deleted after processing.
$DFO_CAL_DIR for normal IDP mode:
The downloaded ABs have their master calibrations listed in the MCALIB section,
with a path $DFO_CAL_DIR/<date>. Depending
on the data source, the downloaded ABs might either have that section filled in the
standard DFOS way (by the actual date of acquisition; case 1), or in some non-standard way,
e.g. in a pool (2099-99-99 as for the UVES reprocessing project version 1; case 2).
For case 1, the phoenix tool checks at the end of processing all dates outside a window
of +/-28days of the current processing date. If found, these dates are deleted. In doing
so, all downloaded master calibrations for the next night can be used again, and only very
few files need to be downloaded, or deleted, in the routine loop mode.
While this strategy is already conservative (master calibrations are not deleted night by night but only for a monthly window), this step can be turned off entirely by calling the tool like 'phoenix -d <date> -M -n'. This is advantageous in a dry run situation when tests are being made across many different dates or months.
For case 2, all master calibrations are accumulated until their number reaches 1000, in
which case all files are deleted. |
$DFO_CAL_DIR for MCALIB mode:
This is the final product directory for MCALIBs (hence logically like the $DFO_SCI_DIR for IDPs). It is not managed by phoenix, hence the products will pile up. Once ingested they can be removed using cleanupProducts.
If you run an MCALIB and an IDP project on the same account, make sure to have the $DFO_CAL_DIR not overlapping, otherwise your MCALIB products might eventually disappear! |
$DFO_CAL_DIR for DEEP mode:
All master calibrations for a given run_ID are collected in a single directory, $DFO_CAL_DIR/<pseudo_date>. They are normally not useful for any other run_ID, therefore this directory is deleted at the end of a phoenix call.
If the tool is called in single-AB mode (i.e. with -r <run_ID> -a <dpc_ab>), the same happens but then it might be desirable to keep the directory for use for another dpc AB. Then call the tool like 'phoenix -r <run_ID> -M -n'. |
$DFO_SCI_DIR:
All products are stored here. The ingestion process takes them from here and ingests the
products as IDPs. Once ingested they are replaced by headers using cleanupProducts. On SLAVE accounts, the headers are transfered to the MASTER account, after the parent IDPs have been ingested.
If you want to add data to an existing folder underneath $DFO_SCI_DIR, this is possible only with the config key UPDATE_YN set to YES (evaluated by moveProducts). Be careful with the management of folders that have already been ingested, and possibly cleaned (headers instead of fits files). Best is probably to move those folders to e.g. <name>_old, then call 'phoenix -M' to fill the folder <name>, ingest it, clean it up, and only then merge the two folders <name> and <name>_old by hand. |
$DFO_LOG_DIR and $DFO_PLT_DIR:
The usual content of these directories is preserved and copied to qc@qcweb. All logs and
plots are accessible from the exported phoenixMonitor. On MASTER accounts, also logs and plots from the SLAVE account are collected.
$DFO_LST_DIR for IDP and DEEP modes:
Usually the content here is just copied from the operational accounts. |
$DFO_LST_DIR for MCALIB mode:
The content is filled from the downloaded headers (data report). |
Data structure on qcweb
AB source (IDP and DEEP modes):
For IDPs, the DFOS accounts on qcweb are the central source of ABs for phoenix. For DEEP, it is the configured AB source on qcweb. The
tool normally does not create its own ABs (but there are exceptions for complex science cascades like for MUSE!). Also, the processed ABs (which might be modified) are stored
after phoenix processing. The scheme is the following, for the example of UVES:
- the AB source is configured as $ORIG_AB_DIR, which gets expanded into qc@qcweb:${ORIG_AB_DIR};
- the processed ABs are stored locally, and also export to qc@qcweb:public_html/$RELEASE/logs
where $RELEASE is configured.
The input and output ABs are always kept separate. |
The phoenixMonitor tool creates an overview of the phoenix processing history, similar to histoMonitor for DFOS operations.
Special notes
- mcalDown file: it is called twice (to account for unsuccessful downloads in
the first instance).
|
- rawDown file: for the MCALIB mode running per month, it is important to have all raw data available before the condor queue starts. Because of dependencies between the data types, the processing does not start with an easily predictable dataset; incomplete ABs would then start firing many download requests for the missing raw files in parallel which might kill the queue. Therefore all download requests are channelled into 6 queues and launched in parallel. Condor is allowed to start only once they are all finished.
|
- VCAL directory: for MCALIBs, virtual calibrations are created and used for the AB creation in the standard way. Contrary to DFOS operations, there is no sequential processing, but processing within a data pool (a month). At the end of the AB creation, all VCALs are therefore deleted.
MCAL directory is empty for MCALIBs. Only the usual GEN_CALIB directory is needed (and could be identical to the one used for IDPs).
|
- config.createAB: the key N_MCAL_LIST should be set to '0' since there is no value in scanning the existing MCALIBs, all associations are done within the pool of VCALIBs.
|
- OCA rules: for the MCALIB mode you should edit the OCA rules (in particular the classification rule) such that only the data types relevant for the MCALIB project remain active. This is the most efficient way to restrict the number of ABs. Then, fine-tuning can happen as necessary using the SETUP configuration in the phoenix configuration.
|
- MCAL directory: for IDPs, a pool of downloaded master calibrations is kept for approximately one month around the current processing date, simply because of (download) efficiency. Therefore, going sequentially further back in time is more efficient (since donwloads are needed only incrementally) than jumping forth and back (then essentially all mcalibs need to be downloaded every time).
VCAL directory is emtpy for IDPs.
|
Don't do
- Never call 'moveProducts -m SCIENCE -d <date>' on the command-line in a PHOENIX environment. The tool will export all log and plot information to qc@qcweb:public_html/${DFO_INSTRUMENT}/logs/<date> and plots/<date> where it will a) get mixed up with dfos information (calibrations, historical science processing), and b) get used as AB source the next time you call the phoenix tool again on that date (if ever). There is no way to prevent this safely (setting DFO_INSTRUMENT to the value of RELEASE would also cause issues). Only if wrapped in 'phoenix -d <date> -M' (or 'phoenix -d <date>', the tool sets the target directory properly to qc@qcweb:public_html/${RELEASE}/logs/<date>.
Notification
about phoenix on operational account
In the following we assume that each PHOENIX account has an operational counterpart
on the mucs. (This will likely be modified, or removed, with DFOS-v2.)
For the stream part of a PHOENIX process (after the bulk processing has been
done), it is desirable to get a signal from the operational account that a certain set
of master calibrations has been finished and is available for phoenix. This 'batch unit'
for phoenix is one month, for no other than pragmatic reasons.
For 'PHOENIX-enabled' instruments, the dfos tools dfoMonitor and histoMonitor on the operational account can
be configured to become aware of the respective PHOENIX account. If the configuration keys PHOENIX_ENABLED and
PHOENIX_ACCOUNT are set in $DFO_CONFIG_DIR/config.dfoMonitor, then the following happens:
a) histoMonitor, when encountering a new month upon being called from 'finishNight',
sends a signal (email) to the QC scientist that a new month has started, meaning that a
set of certified master calibrations is available for the previous month. At the same time,
a new status flag 'phoenix_Ready' is written into DFO_STATUS, along with the previous month
(format YYYY-MM).
b) This flag is catched by dfoMonitor and used to flag that month on the
main output page:
PHO
ENIX:
2013-06
 |
If no new PHOENIX job is on the ToDo list, this field is empty: |
PHO
ENIX:
none
|
c) It is left to the QC scientist, when and how this new
PHOENIX task is launched. There is no automatic job launch, and there is no communication between the
operational machine and the PHOENIX machines.
The standard way is to launch 'phoenix
-m 2013-06' as sciproc@muc08 (or xshooter_ph@muc08 etc.). Depending on the data themselves, and on the data volume,
this might take a few hours. Since in principle it might be that in the future there are
several concurrent phoenix jobs, or an operational account in addition to sciproc, there
is no automatic mechanism to launch PHOENIX jobs.
d) When this step has been done, the QC scientist can confirm this PHOENIX
job to be done, by pushing the button 'done'. This triggers a dialogue, where the user
is asked to confirm the execution, and then this month is removed from the DFO_STATUS file.
If there is more than one month, all months will offered for confirmation, one after the
other. |
| Last update: April 26, 2021 by rhanusch
|