
1 INTRODUCTION
The software described in this manual is intended to be used in the ESO VLT project by ESO and authorized external contractors only.
While every precaution has been taken in the development of the software and in the preparation of this documentation, ESO assumes no responsibility for errors or omissions, or for damage resulting from the use of the software or of the information contained herein.
1.1 Purpose
It is intended to provide all the necessary information to use this software to develop application software running on LCUs and to use the provided Engineering User Interface.
The manual assumes that the reader has a good knowledge of UNIX, VxWorks, Motif GUI, C language and is familiar with VxWorks development environment.
User's Guide, describing the functionality provided by the software, including examples of utilization.
Syntax Validation Tools, describing the tools provided to validate the syntax of Command Definition and Command Interpreter tables, and database Point Definition files.
Reference, describing all the functions, commands and tools available to the applications and the application developers.
Error Messages and Recovery. Provides a list of errors and diagnostic messages and possible recovery actions.
1.2 Scope
The LCU Common Software provides a set of common services and procedures which shall be available on each LCUs, and tools running on the workstations for maintenance and debugging, the Engineering User Interface and the syntax verification tools. The LCC shall be the basis for the development of subsystem specific application software.
� lccdt, lccit and lccdb - Tools to validate the syntax of Command Definition tables, Command Interpreter tables and database Point Definition files
1.3 Reference Documents
[7] VLT-MAN-ESO-17210-0667, 1.3 - VLT Software - Guidelines for the Development of Application Software
1.4 Abbreviations and Acronyms
1.5 Glossary
A Message System based application performing a well defined task. It can be an application controlling some hardware functional unit, but can also be a pure software device, e.g. coordinating other software devices or performing some general service.
Simulation - Hardware Simulation
The software of various modules, including subsystems and instruments is required to have simulation modes. By this is meant that the software can work without any real hardware connected and nevertheless appears as if it were executing commands. Simulation can also be applied to individual control functions, in case some hardware is missing.
Simulation - Software Simulation
It can also be that some of the software has to be simulated, as for example it cannot be used at the moment, e.g. preparations of observations off-line. In this case commands to the simulated software cannot be sent, but get nevertheless a realistic reply. The syntax and parameters are checked but independently of the existence of the destination software.
1.6 Stylistic Conventions
1.7 Naming Convention
1.8 Problem Reporting / Change Request
The form described in [8] shall be used.
2 USER'S GUIDE
This chapter provides a functional description of the LCU Common Software: how to use it and what to use it for.
2.1 Overview
2.1.1 Local Control Unit
A Local Control Unit (LCU) consists of a VMEbus backplane with a number of standard hardware modules. These normally are a CPU module with Ethernet and terminal interfaces and a number of process I/O modules. The number and type of I/O modules depends on the application.
2.1.2 LCU Common Software
The LCU Common Software provides a set of common services and tools to support the LCU application software. The purpose is to provide a standard solution to requirements common to all LCU application software.
� Engineering User Interface running on the workstations, a complete description of the Engineering User Interface is provided in chapter [3].
2.1.3 Availability
The LCU Common Services are available as direct procedural call from any program in the same LCU or via the message system to any process, running in the same LCU or in a remote node. The following sections describe the functions provided by the LCU Common Software.
At the end of each family of functions, a quick reference section lists the procedures, the commands and the include files provided by each function of the software. The name of the command corresponding to a procedure is given between brackets after the name of the procedure. If no command is available, the brackets are left empty.
2.2 LCU Management
2.2.1 Purpose
2.2.2 Basic Concepts
A "software device" is a Message System based application, which is defined in the "devicesFile" file under the BOOT directories, and related to each LCU. The application can be based on the Command Interpreter, see 2.11. The software device can be an application controlling some hardware functional unit but it can also be a pure software device coordinating other software devices. Examples of software devices are applications controlling the M3 rotating mirror, adapter rotating arm, M2 focusing stage, instrument grism, filter wheel, detector, etc.
The status of an LCU node reflects its working condition (its STATE): it is the combination of the states of the LCU Common Software and of the software devices. It can be one of the following:
� LOADED, when LCC or any software device is in the state LOADED or if any software device is in the state OFF: all application software is loaded, the database is configured, the software is initialized and ready to initialize the hardware.
� STAND-BY if LCC or any software device is in the state STAND-BY and neither LCC nor any software device is in the state OFF or LOADED: all software is loaded and initialized, all hardware is initialized, the software is operating but all software devices are in stand-by mode e.g. possibly switched off, brakes engaged; the actual state of a software device in stand-by mode has to be defined for each subsystem.
� STAND-ALONE, if LCC is in the state STAND-ALONE and all software devices are in the state ON-LINE: all software is loaded and initialized, all hardware is initialized, power is switched on (this is the state normally used for maintenance and for instrument operations in the not-active focus station). Stand-alone is a special category of the state on-line with normally certain restrictions. An example of this is an application in the state on-line accessing other LCU nodes but in the state stand-alone not. The concept of stand-alone and on-line is mainly used by the system controlling the LCU, e.g. telescope control system, instrument control system.
� ON-LINE, if LCC and all devices are in the state ON-LINE: all software is loaded and initialized, all hardware is initialized, power is switched on (this should be the normal state).
� INITIALIZING, the LCU is in the process of initializing the hardware; the transition state INITIALIZING is also a phase of the transition phases COLD-START and WARM-START and is indicated during these phases,
� SHUTTING DOWN, the LCU software is in the process of shutting down all functions it is controlling; takes the LCU into the state LOADED.
� SIMULATION MODE, the LCU is running in simulation mode; simulation mode can only be entered from the states LOADED, STAND-BY, STAND-ALONE or ON-LINE; exiting simulation mode will take the LCU into the state LOADED. The LCU can be in SIMULATION mode simultaneously with any of the main LCU states (LOADED, STAND-BY, STAND-ALONE or ON-LINE).
� DEVICE IN SIMULATION, indicating that some software devices are in simulation mode. When a software device exits simulation, the LCU is taken into the state LOADED: any active start-up or shutdown procedure is stopped and the stop and off commands are sent to all the software devices.
The flag is set when any software device enters simulation (lccDevEnterSim) and reset when all software devices have exited simulation (lccDevExitSim).
After power up, hardware reset or a reboot command, the LCU will boot over the LAN from a control node (this node is called the host computer).
� download the LCU Common Software; downloading of software is part of the VxWorks environment, and is not covered by the LCU Common Software,
2.2.3 Node Management
Several service functions are provided to switch the LCU between different states. In addition it handles the management of software devices.
Each software device shall accept a set of standard commands which are sent to the software device by the node management module when it goes from one state to another. The standard commands used by the node management functions described in section 2.2.3.2 are:
� SELFTST to perform a self-test of the software device. Selftest shall be performed on the lowest level only checking software devices, but not moving any hardware.
The standard commands are sent to all software devices listed in the node management device file. This file has the name devicesFile and must reside in the boot directory.The commands are sent with one parameter, the name of the software device (string).
2.2.3.1 Device File
The device file lists the software devices controlled by LCC. The device file contains the definition of a TABLE attribute of the database used by LCC (:LCC:DEVICES.deviceTable). The table contains the following fields:
� simulation status of software device (Logical) [LCC internal use, updated by lccDevEnterSim and lccDevExitSim],
The attribute is restored by LCC using the dbRestoreFile function (see section 2.3.8) when the corresponding LCU is rebooted.
As described in section 2.3.8, the values 0 - 2 and 0 - 5 in the above example give respectively the records in the table and the fields of each record. The number of records corresponds to the number of software devices, e.g. 0 - 2 corresponds to 3 software devices. One software device corresponds to the record numbers
0 - 0. The number of fields shall not be modified.
2.2.3.2 Standard Mode Switching Functions
lccColdStart first sends an exit command to all software devices then reboots the LCU. After rebooting, it loads and initializes all software modules, initializes all hardware modules and sets them in stand-by or on-line mode. The software is active and all monitoring activities continues. It takes the LCU subsystem from state OFF to state STAND-BY, STAND-ALONE or ON-LINE. An init command is sent to the software devices, followed by either stand-by command if end mode is STAND-BY or on-line command for other end modes. This implies that the application program for each software device must accept exit, init, stand-by and on-line commands.
lccWarmStart initializes all software modules, initializes all hardware modules and sets them in stand-by or on-line mode. The software is active and all monitoring activities continues. Initial state must be LOADED. It takes the LCU subsystem from state LOADED to state STAND-BY, STAND-ALONE or ON-LINE. An init command is sent to the software devices, followed by either stand-by command if end mode is STAND-BY or on-line command for other end modes. lccWarmStart is the normal start-up function after the LCU has booted and the software is downloaded.
lccStandAlone takes the LCU subsystem from state LOADED or STAND-BY to state STAND-ALONE. The command on-line is sent to all software devices. This implies that all software devices must accept the command on-line.
lccOnLine takes the LCU subsystem from state LOADED or STAND-BY to state ON-LINE. The on-line command is sent to all software devices. This implies that all software devices must accept the command on-line.
lccStandBy sets the LCU in stand-by mode. The software is still active and all monitoring activities continues. A stand-by command is sent to all software devices. This implies that all software devices must accept a stand-by command. Initial state must be LOADED, STAND-ALONE or ON-LINE.
lccShutdown stops all hardware activities in a controlled way, aborts all software activities and initializes the LCU software. A stop command then an off command are sent to the control software of all software devices on the LCU. This implies that all software devices on the LCU must accept stop and off commands. It takes the LCU subsystem from states STAND-BY, STAND-ALONE or ON-LINE to state LOADED.
lccStop stops the active start-up or shut-down procedure, e.g. initialize, reload. The reboot procedure can't be stopped with this command. A stop command is sent to all software devices on the LCU.
The LCU will not change the state after a stop command.
2.2.3.3 Auxiliary Functions
The auxiliary functions are used during tests and debugging of the system, but not during normal operation.
lccInitFull initializes all software devices belonging to the LCU. Takes the LCU subsystem to the state STAND-BY, STAND-ALONE or ON-LINE. This procedure will first perform a general initialization of the LCU. An init command is sent to all the software devices configured in the LCU, followed by either stand-by command if end mode is STAND-BY or on-line command for other end modes.
lccReload stops all hardware activities in a controlled way, aborts all software activities and reloads the LCU software (this command does the same as the command lccShutdown and additionally reloads the LCU software). Reloading is a quick way to reload the LCU software without starting up the system.
lccReconfigure stops all hardware activities in a controlled way, aborts all software activities, initializes the LCU software and reconfigures the software and all parameters (this command makes a shutdown and reconfigures the LCU). Reconfiguration is a quick way to reload the LCU software and to configure the database with a new set of values.
lccReboot reboots the LCU and loads and initializes all software modules. All activities in the LCU are immediately aborted and the LCU reboots. Takes the LCU to the state LOADED.
2.2.3.4 Status Functions
When software devices are being initialized, service functions allow to wait for software devices belonging to the LCU to finish initializing.
lccWaitFullInit returns when all the software devices it is waiting for have finished initializing, or a specified time-out time has elapsed, or an error occurs.
lccWaitFirstInit waits for software devices belonging to the LCU to finish initializing and returns when the next software device has initialized. It can be called several times and returns the name of the next software device that has initialized.
lccGetId returns the identification of the LCU node, i.e. name, internet address and boot node name and internet address.
lccGetDeviceList returns a list of the software devices configured on the LCU along with their initialization status.
lccGetDeviceState returns the state (OFF, LOADED, STAND-BY or ON-LINE) of a software device and also indicates if the device is in simulation mode.
lccRegisterDevice is used for checking the I/O hardware device configuration. Each I/O hardware device shall be registered at hardware device installation. LCC will then check that the hardware and the device driver is installed. The presence of the hardware is done through a probe address given as input parameter to lccRegisterDevice. The device driver installation is checked by opening the driver read-only.
2.2.3.5 Monitoring and Self-Test
The LCU Common Software has a monitoring routine checking that the LCU is working normally (interrupts are not blocked, dead-lock, if the shell or the Message System is blocked etc) using a hardware watch-dog timer to generate a System Reset in case of failure.
In addition there is a software watch-dog task, which after being started reboots the system if it is not triggered regularly. Before rebooting, however, it sends an abnormal event indicating a time-out. Note that the event may not be forwarded successfully if the watchdog has expired due to a deadlock, a communication failure, etc.
The LCU has also self-test software which runs automatically at start-up and at other times on request. It checks that the boards configured with the LCU are present and configured properly. This is done for all I/O hardware devices that have registered to the LCC, including also CPU, time interface, etc. Then it sends a self-test command to all software devices. The software devices are listed in a configuration table in the database. This means that all software devices shall accept a self-test command and perform the necessary tests on its hardware and its functionality. The self-test at this level shall not move any mechanical functions.
� self-test procedure of the LCU; it will send the command self-test to the application programs controlling the software devices configured on the LCU,
� check that the correct hardware configuration is set up without making any further tests; the hardware devices are declared to the LCU Common software using the lccRegisterDevice function.
2.2.3.6 Simulation Mode
Simulation is available at different levels; at the LCU level where all the LCU hardware is simulated and at software device level where each software device can be simulated individually. This means that software devices shall accept the commands to enable/disable simulation mode. The remote database access and the time reference system are not included in the general simulation, but have their own simulation mode. The LCU software is not allowed to enter simulation mode if any hardware device is active e.g. a motor is moving, a detector is integrating etc. In simulation mode the LCU shall be able to work without external hardware. Hardware input signals will return default values set up at configuration. It will be possible to change these values dynamically.
Service functions are available to enter/exit simulation mode of the LCU. They will send the command enter/exit simulation mode to the software devices configured on the LCU. Software devices exiting simulation mode shall have the status non-initialized.
A software device entering or exiting simulation mode shall use the function lccDevEnterSim/lccDevExitSim.
These functions will set the proper status in the LCC device table. lccDevExitSim will additionally send the commands STOP and OFF to all software devices which will shut down the LCU and put it in the state LOADED.
2.2.4 Memory Tracing
LCC provides a utility to do tracing of memory allocation/deallocation. By including the include file lccMemoryTrace.h all calls to malloc() and free() are replaced by lccMalloc() and lccFree(). These functions allow tracing of the memory usage on the LCU. Each call to malloc() of free() leads to print out a message on the LCU console indicating how many bytes are allocated/freed and the total number of allocated bytes. The tool function lccPrintMemory() displays the all memory partitions up to 5000 entries.
2.2.5 Symbol Table Access
To provide transparent access to the VxWorks symbol table for 68k and PowerPC CPUs LCC provides symbol table access functions lccFindFunctionEntry(), lccFindSymbolAddress() and lccSymFindByName(). The VxWorks function symFindByName() shall not be used from applications to avoid porting problems.
2.2.6 NON-Posix Functions and Floating Point Library
For MV167 68K CPUs VxWorks supports some NON-Posix functions like round() or iround(). These functions are not supported any longer on the MV2604 PowerPC CPUs. The compiler generates the following warnings:
myFile.c:58: warning: implicit declaration of function
`round_is_not_POSIX_compliant_use_lccRound'
myFile.c:58: warning: implicit declaration of function
`cosf_is_not_POSIX_compliant_use_cos'
For the 2 widely used functions round() and iround(), LCC provides the wrappers lccRound() and lccIRound() with identical prototypes.
2.2.7 Task management
For applications requiring to spawn frequently the same task, the memory fragmentation increases. This might lead to run out of memory as the system can not find a block large enough to allocate the necessary memory space for the task control block and its stack. In order to reduce the latency of this problem, LCC provides a set of wrapper functions (see lccTaskLib(3)) that allow to reuse the same memory block each time the task has to be spawned.
2.2.8 Examples
Register analog I/O hardware device at address 0xffff8000 using word length probe access with input and output voltage range +10 -10V:
2.2.9 Reference
lccBootResult() [] - display summary of LCC initialisation on the LCU console
lccCheckConf() [LCCCHK] - check LCU hardware configuration
lccColdStart() [LCCCOLD] - cold start of LCU node
lccDevEnterSim() [LCCISIM - notification of software device entering simulation
lccDevExitSim() [LCCOSIM] - notification of software device exiting simulation
lccDisSim() [LCCDSIM/STOPSIM] - disable LCU simulation mode
lccEnSim() [LCCESIM/SIMULAT] - enable LCU simulation mode
lccFind() [] - search a file in INTROOT and VLTROOT environments
lccFindFunctionEntry() [] - replacement for VxWorks symFindByName()
lccFindSymbolAddress() [] - replacement for VxWorks symFindByName()
lccFmod() - replacement for VxWorks fmod() function
lccGetDeviceList() [LCCGDEV] - get list of configured software devices
lccGetDeviceState() [LCCGDST] - get state and simulation mode of software device
lccGetDeviceTimeout() [] - get device timeout
lccGetId() [LCCGID] - get LCU node identification
lccGetStatus() [LCCGST/STATE] - get current status of LCU
lccGetVersion() [LCCGVER/VERSION] - get version of LCU Common Software
lccInitFull() [LCCINIT/INIT] - Initialize all configured software devices
lccIRound() [] - replacement for VxWorks iround()
lccOnLine() [LCCONLN/ONLINE - set LCU node in ON-LINE mode
lccReboot() [LCCBOOT] - reboot LCU node
lccReconfigure() [LCCRCNF] - shutdown LCU node and reconfigure LCU
lccRegisterDevice() [] - register an I/O hardware device
lccReload() [LCCRLD] - shutdown LCU node and reload software modules
lccRound() [] - replacement for VxWorks round()
lccSelfTest() [LCCTEST/SELFTST] - execute self-test procedure
lccSetDeviceState() [LCCSDST] - notify LCC of software device state
lccSetDeviceTimeout() - set device timeout
lccShutdown() [LCCSHUT/OFF] - shutdown LCU node
lccStandAlone() [LCCSTAL/STANDAL] - set LCU node in STAND-ALONE mode
lccStandBy() [LCCSTBY/STANDBY] - set LCU node in STAND-BY mode
lccStop() [LCCSTOP/STOP] - abort current LCU management procedure
lccStopWatchdog() [WSTOP] - stop LCU software watchdog
lccSymFindByName() [] - replacement for VxWorks symFindByName()
lccWaitFirstInit() LCCWFST] - wait until next software device has initialized
lccWaitFullInit() [LCCWFUL] - wait until all software devices have initialized
lccWarmStart() [LCCWARM] - warm start of LCU node
2.3 Database
The local database provides real-time data store/access capabilities. It permits data sharing among processes and event generation based on change of data value.
Values in the database are stored as "attributes" grouped in "points". The database organisation is hierarchical and similar to that of a `file system': the environment name specifies the file system, points are organised just like directories. Each point is defined by one file containing the description of all attributes belonging to that point.
Databases are referenced by the "environment name" and can be located either in workstations or in LCUs. The system file /etc/services provides a list of all known environments.
2.3.1 Current Working Point
In order to reduce the overhead of a full absolute path search, there is the concept of the Current Working Point (CWP). This information is private to each process and allows it to set its area of interest to a certain point's subtree in the hierarchy, then to perform accesses relative to that point.
� Until the CWP is changed, all successive nonabsolute or incomplete path accesses are relative to this point.
2.3.2 Direct Address
Allows a fast access to a database element and it is recommended when a fast periodic access is required.
The direct address is called PLIN (Point List Index Number) and is a unique reference number that identifies each point within the database and can be used as a direct address of the point. The PLIN is automatically assigned to each point when the point is created and remains the same until the point is deleted.
2.3.3 Symbolic Address
� The Attributes Name can appear everywhere in the database and are used to collect data. Data can be stored into three main structures: scalars, vectors and tables.
The database offers a `flat' view of its structure where each point is identified by a name which is unique in the complete database. In this case database points can be directly addressed by names such as: emmiBlue, redExposure, etc...
A database element is addressed by specifying the environment (optional), point and attribute name. All these names are strings separated by special characters, as follows:
2.3.3.1 Environment Specification
The environment name is the uppermost level of the database hierarchy and it is specified as first, optional, parameter of the symbolic name.
"@environment_name:point1:...:pointN.Attribute"
The naming rules for the environment are described in document [4], section "Naming and Address Allocation". Among the rules those relevant to the database access are:
The name of an environment for a generic name of WS or LCU begins with w/l and is followed by the name of the node, for example: wte16 or lte21.
2.3.3.2 Points Specification
Points in the database can be addressed giving the full absolute path name, a relative one, or by alias (see section View Specifiers).
� Absolute path name It is formed by a concatenation of point names starting with ":" and the path is relative to the root point of the local environment.
� Relative Path Name It is formed by a concatenation of point names starting without ":" and the path is relative to the Current working point (CWP)
If the Current Working Point is set to ":l1:l2", the two following symbolic names address the same database element:
2.3.3.3 Attribute Specification
A point can contain data which are stored into its "attributes". Each attribute has a unique symbolic name within the same point.
Vector attributes are addressed by specifying: Point name. Attribute name (Start element: End element)
� Specifying only "Start element" means "only that element". For example, vector(3) is equivalent to specifying vector(3:3).
� Specifying a "$" as second element means "to the end of the vector". For example, vector(3:$) is equivalent to access the array from element 3 to the end.
� If the second index of the record/field range is omitted, it is assumed to be the same as the start. For example, table(3,8) is equivalent to table(3:3,8:8).
� Specifying a "$" as second index for the record/field means "to the last record/field". For example: table(0:$,0:2) tells the system to read the first two fields of all record, while table(0:3,0:$) reads all the fields of the first three records.
2.3.3.4 View Specifiers
The view specifier <alias> can be added in front of the symbolic name to specify that the name is an alias.
Alias names follow the same rule as point names -.e.g.- myAlias.attribute, but there is no hierarchy reflected in the address.
Interprets the following symbolic name is relative to the Current Working Point or it is a child of the current point.
It is used to remove any previously specified name interpretation and the address is considered to be relative to the root point.
The view specifier is: <absolute>
2.3.4 Data Types
� Tables: bi-dimensional arrays. Up to 65535 records (lines) of the same format, each record may have 255 fields (columns). Each field contains a scalar value of any of the previous data type
.
2.3.5 Naming Rules
� Attributes and Point names follows the programming Standard naming rules for what concerns `Local Variables' (see [1]). A name is formed by several words each having the first letter in capitals (except the first word).
2.3.6 Functions
The access to the database values can be done programmatically or via the message system (from a remote node).
� lock/unlock an attribute: a lock disables all write accesses from all processes except the requesting process,
� lock, unlock a point; a lock disables all read and write accesses of all attributes of the requested point from all processes except the requesting process,
Database locations will normally be accessed logically by name. However, to speed up the operations, internal direct addressing is also available for local data only and in programmatic mode.
Access to multiple database values is done storing in a description list the information about all the attributes that must be accessed with a single operation. A single call to one of the basic read/write functions performs the actual access to the database. This is equivalent to multiple calls to simple read/write database routines, but provides better performance or data integrity during write operations.
� The list is created for READ or WRITE operation. It is not possible to change this setup at run time. Attributes which must be accessed both for read and write must be placed in two different lists, one used only for READ and the other only for WRITE.
� A list is identified by a name and by a list identifier. The list identifier is used for performance reasons to manipulate the list. Once a list is created, the name can be used everywhere inside the application program to retrieve the identifier.
2.3.7 Database Loading/Unloading
The database structure is created during loading of the database from a set of definition files stored on disk. These files are created from a set of Database Description Files by the Database Loader, see [3]. See also [7] for database organization.
The loading can be done at start-up of the database manager, giving the root directory of the database definition files in the run-string or to a running database manager as a service function. It is also possible to load or unload a database branch, i.e. all points and attributes under a given point.
Loading of an existing database will destroy the present content and structure of the database. Loading a database branch will destroy the present content and structure of the loaded branch.
� unload, i.e. save the structure and content of the database or a database branch in a set of definition files.
When the database is loaded a snapshot of the database is created in the LCU environment directory, $VLTDATA/ENVIRONMENTS/<lcuEnv>, called lccSnapshot.db. The next time the LCU boots it will load the database from the snapshot file. This will be significantly faster than loading from the definition files.
LCC will load from the snapshot file if it exists. To force loading from the definition files, for example when the database structure has been changed, delete the snapshot file.
A set of ASCII files describing the hierarchical structure and the content of each point is used to load the data base and a similar set of files is produced by the database when it is unloaded (for Backup purposes or off line modifications). The file structure reflects the hierarchical structure of the database: each point is represented by a subdirectory having the point name as name.
The attributes are described in a Point Configuration File. The syntax of a Point Configuration File is described in rtap1 documentation.
The LCC also accepts Point Configuration Files unloaded by RTAP, although RTAP unloads in a format slightly different than LCC. Point Configuration Files unloaded by RTAP also contains keywords not used by LCC.
Caution: the point configuration files are located on the boot host and are accessed by the LCU through NFS. NFS allows the filename including the complete path (as defined on the host, not as it is NFS mounted on the LCU) to have a length of maximum 256 characters.
When a database is unloaded by the LCC software, the header written at the beginning of each Point Configuration File is taken from a specific Database header File, see section 6.
2.3.8 Data Base Backup/Restore
To backup/restore data from the database, use the CCS utilities dbBackup/dbRestore. See [2] for detailed description. There is also a new LCC function dbRestoreFile, to restore data saved by the CCS utility dbBackup.
The LCC utilities dbBackup/dbRestore to backup/restore are still available, but should no longer be used.
2.3.9 Simulation Mode
2.3.10 Memory Usage
� vector: (140 + recordNbr * 12) bytes for numeric types
(140 + recordNbr * (12 + X)) bytes for BytesX types
� tables: (140 + fieldNbr * 24 + recordNbr * S fieldSize) bytes where fieldSize is 12 bytes for
numeric types and (12 + X) bytes for BytesX types
2.3.11 Examples
status = dbReadDirect(&dbAddress, type, (char*)&speed, sizeof(vltFLOAT), &actual,
&recordCount, &attributeType, &error);
status = dbWriteSymbolic(":motor.speed", NULL, type, (char*)&speed,
sizeof(vltFLOAT), &actual, &recordCount, attributeType,
&error);
2.3.12 Reference
dbAliasToName() [DBATON] - get symbolic address from alias
dbDeToStr() [] - format database element value into a string
dbDirAddrToName() [] - get symbolic address from direct address
dbDisRemoteAccess() [DBDREM] - disable access to remote databases
dbDisSim() [DBDSIM] - disable remote databases simulation mode
dbEnRemoteAccess() [DBEREM] - enable access to remote databases
dbEnSim() [DNESIM] - enable remote databases simulation mode
dbFillBuf() [] - fill buffer with database element value
dbGetAlias() [DBGALS] - get the alias of a point
dbGetAttrInfo() [DBGAINF] - get attribute information
dbGetAttrNames() [DBGANAM] - get name and internal number of attributes in a point
dbGetAttrNumber() [DBGANUM] - get number of attributes in a point
dbGetCwp() [DBGCWP] - get current working point
dbGetDirAddr() [DBGDIRA] - get direct address of point or attribute
dbGetFamily() [DBGFAM] - get internal number of parent point and attributes
dbGetFamilyNames() [DBGFAMN] - get internal number of parent and children points
dbGetFieldNames() [DBGFNAM] - get name of parent and children points
dbGetParent() [DBGPAR] - get internal number of parent point
dbListAdd() [] - insert a new element in the list
dbListChangeEnv() [] - replace the environment name with another
dbListCreate() [] - create an empty a list of attributes
dbListDestroy() [] - destroy a list of attributes
dbListExtract() [] - get the information returned after a read/write operation
dbListGetId() [] - get the list identifier from the name
dbListModify() [] - modify the configuration parameters of an element of the list
dbListRemove() [] - remove an element from the list
dbLoad() [DBLOAD] - load local database from disk
dbLoadBranch() [DBLDB] - load local database branch from disk
dbLockAttr() [DBLCKA] - lock attribute for exclusive write access
dbLockPoint() [DBLCKP] - lock point for exclusive read and write access
dbMemCpy() [] - copy single database element value
dbMultiRead() [] - read list of attributes
dbMultiWrite() [] - write list of attributes
dbNameToType() [] - convert database data type mnemonic into value
dbReadDirect() [] - read attribute using direct address
dbReadScalar() [DBREADS] - read scalar attribute using symbolic address
dbReadSymbolic() [DBREAD] - read attribute using symbolic address
dbRestoreFile() [] - restore database attribute values
dbSetCwp() [DBSCWP] - set current working point
dbStrToDe() [] - convert string into database element value
dbUnload() [DBULOAD] - dump local database to disk
dbUnloadBranch() [DBULDB] - dump local database branch to disk
dbUnlockAttr() [DBULCKA] - unlock attribute
dbUnlockPoint() [DBULCKP] - unlock point
dbWriteDirect() [] - write attribute using direct address
dbWriteScalar() [DBWRITS] - write scalar attribute using symbolic address
dbWriteSymbolic() [DBWRIT] - write attribute using symbolic address
2.4 I/O Signal Handling
A signal is defined as an input or output or a group of inputs or outputs on a digital I/O board or any other board containing digital inputs or outputs. A signal can also be an analog input or output. This section describes how signals are configured and accessed.
For each configured input or output signal, an attribute in the local database shall contain the current value of the signal, dbUINT32 for a digital I/O signal, dbFLOAT for an analog I/O signal. The attribute value is updated automatically when a signal access function is called. The name of the attribute in the database is identical to the name of the signal.
For each signal, a second mandatory database attribute of type rtLOGICAL contains the status of the signal. The name of the attribute is composed of the name of the signal, followed by the "_status" suffix, i.e. :motor.speed_status for signal :motor.speed.
Signals are accessed logically by name locally or from another node. Addressing of signals are done according to addressing of local database locations.
The status attributes indicates if the last driver call was successful. The value is ccsTRUE if the last was successful and ccsFALSE if the last call failed.
2.4.1 Functions
The common service functions described below are only available for standard digital and analog I/O boards:
2.4.2 CAN bus I/O
From the APR2004 release is analog and digital I/O over CAN bus available. To access CAN bus I/O signals use the same functions as for standard VME I/O boards. The access time for CAN bus signals is however much longer than for signals connected to VME boards. For example reading an analog signal over the CAN but takes in the order of 8 ms, compared to less than 100 microseconds for VME bus signals (using direct access methods).
In order to speed this up access of analog input signals there are now functionality to use the CAN bus sync signal. CAN bus analog input signals can be configured to use the sync signal with the function ioConfigCANAnalogSync(). Then before being able to read a new value it has to be transferred from the CAN node to the VME system using the function ioCANSendSync(). If using only one signal, the use of the sync signal does not bring any big performance improvement. But the more signals are used with sync, the bigger will the performance improvement be. Then it is possible to achieve CAN bus signal access times in the order of 0.7 ms (for reading).
2.4.3 Simulation
In simulation mode, the above functions will not affect the hardware or its configuration. Write requests will only return the proper status. Read requests will return default values.
2.4.4 Memory Usage
The amount of memory used for a signal is 346 bytes, not including the size of the two database attributes associated to the signal.
2.4.5 Examples
Configure analog input signal ":motor.speed", signal 3 of hardware device "/aio0", conversion factor 33.3, range 0 to 100, gain 1 and 20 as default simulation value.
Configure digital output signal ":motor.onOff", bit 32 of hardware device "/acro0", active low, default simulation value 0:
2.4.6 Reference
ioChangeBit() [BITCHG] - change state of single bit digital output signal
ioClearBit() [BITCLR] - set single bit digital output signal to inactive state
ioConfigAnalog() [AIOCNF] - configure analog signal
ioConfigCANAnanlogSync() [AIOCFS] - configure CAN bus analog input signals to use sync
ioConfigDigital() [DIOCNF] - configure digital signal
ioConfigMenDigital() [DIOMCNF] - configure MEN digital signal
ioDChangeBit() [] - change state of single bit digital output signal
ioDClearBit() [] - set single bit digital output signal to inactive state
ioDisableInterrupt() [DIODSI] - disable interrupts from MEN digital I/O module
ioDPulseBit() [] - pulse single bit digital output signal
ioDReadAnalog() [] - read analog input signal
ioDReadDigital() [] - read digital input signal
ioDSetBit() [] - set single bit digital output signal to active state
ioDWriteAnalog() [] - write analog output signal
ioDWriteDigital() [] - write digital output signal
ioEnableInterrupt() [DIOENI] - enable interrupts from MEN digital I/O module
ioGetAnalogConfig() [AIOGCNF] - get configuration of analog signal
ioGetDigitalConfig() [DIOGCNF] - get configuration of digital signal
ioGetDirectAddress() [] - get direct address of signal
ioGetList() [IOGLST] - get list of all configured signals
ioPulseBit() [BITPULS] - pulse single bit digital output signal
ioReadAnalog() [AIOREAD] - read analog input signal
ioReadAnalogRaw() [AIORRAW] - read analog input signal
ioReadDigital() [DIOREAD] - read digital input signal
ioSetAnalogSimValue() [AIOSIM] - set simulation value of analog signal
ioSetBit() [BITSET] - set single bit digital output signal to active state
ioSetDigitalSimValue() [DIOSIM] - set simulation value of digital signal
ioStartSampling() [IOSTART] - start monitoring of signals
ioStopSampling() [IOSTOP] - stop monitoring of signals
ioWriteAnalog() [AIOWRIT] - write analog output signal
ioWriteDigital() [DIOWRIT] - write digital output signal
2.5 Event Monitoring
2.5.1 Purpose
The main purpose of event monitoring is to report the LCU subsystem status to the control node to keep an image of the status in the On-Line Database on the workstations. The process on the workstation requesting event report is called the scan task.
2.5.2 Basic Concept
� the attribute value changes more than a deadband (evtDEAD_BAND). The deadband defines the minimum change before an event is reported. A value going out of limit, however, is reported immediately. The deadband is also used as hysteresis around the limit. The deadband is applicable only to database locations of type integer or real (including Polar, Rectangular and Times).
Events can also be configured for signals, through the signal image in the database. Signals configured to be reported on change of value (evtNOT_EQUAL or evtDEAD_BAND) are sampled by LCC at a configurable rate.
The requesting process sends an event request to the event monitoring module to specify database attributes or signals for which it wants to receive event reports. The event monitoring module will then start to send event reports to the requesting process when the trigger condition is fulfilled for the attribute.
An event report will contain the event identifier, the trigger condition, the id of the process that triggered the signal, the symbolic address of the attribute (or signal) for which the event is reported, the attribute type and event information:
Application programs wanting to report some event shall do this by using a local database parameter.
2.5.3 Functions
The following service functions allow to configure database parameters and signals for event monitoring and to request the sending of events:
� configure a database parameter or signal for event monitoring; any scalar database parameter can be configured for event monitoring, including elements of vectors and tables,
� request event reports for a database parameter or signal; events will start being reported after this request to the requesting process; requesting event reports will enable event reporting to the requesting process,
2.5.4 Simulation
2.5.5 Filtering of Events
To reduce the load on the LAN it is possible to limit the number of events or abnormal events in case a process continuously would change the same database attribute repetitively with high rate. To achieve this the event system can discard event messages from the same database attribute, if they occur more that a certain number of times during a specific time interval.
There are two lcc boot parameters (set in the file lcc.boot) to configure this filter, lccEvtDiscardDN to set the maximum number of event messages during the time interval set by lccEvtDiscardDT. See also section 7.3.3.3.
2.5.6 Examples
2.5.7 Reference
evtAttach() [EVTATT] - request events for a database parameter
evtConfig() [EVTCNF] - configure database parameter for event monitoring
evtDetach() [EVTDET] - remove an event definition
evtDisAllEvent() [EVTDAE] - disable the sending of event reports for all processes
evtDisEvent() [EVTDE] - disable the sending of event reports for a process
evtEnAllEvent() [EVTEAE] - enable the sending of event reports for all processes
evtEnEvent() [EVTEE] - enable the sending of event reports for a process
evtGetConfig() [EVTGCF] - get the event configuration of a database parameter
evtGetSampleRate() [EVTGSR] - get sample rate of signals monitored on change of value
evtParseMsg() [] - parse an event message
evtSetSampleRate() [EVTSSR] - set sample rate of signals monitored on change of value
evtSingleDisable() [EVTSDI] - disable a specific event
evtSingleEnable() [EVTSEN] - enable a specific event
no function [EVTGAE] - get list of all events
no function [EVTGE] - get list of events reported to given process
2.6 Abnormal Event Handling
2.6.1 Purpose
An abnormal event (or alarm) occurs when a signal or database parameter configured for abnormal event goes out of limit.
� to report an abnormal event to a local process to enable this process to take the appropriate action on the event
2.6.2 Basic Concept
The software on the LCU handling abnormal events is configurable, that is it is possible to specify which events are abnormal and associate an alarm number with the abnormal event. A process wanting abnormal event reports requests these and receives as replies to the request the abnormal event reports.
An abnormal event is reported with the event identifier, the id of the process triggering the alarm, the name of the signal or database parameter for which the alarm is reported, the type of value, the alarm number, the actual and previous alarm status (e.g. LowLow limit, Low limit, No limit, High limit, HighHigh limit) and the actual and previous value of the signal or database parameter.
When the conditions for the abnormal event no longer exist, an abnormal event is also sent to all processes which have requested abnormal events for the database parameter.
A value returning from an alarm limit has an hysteresis (deadband) which means that it will not exit alarm state until the value has decreased (for a high limit) or increased (for a low limit) more than the hysteresis below/above the limit. There is no hysteresis when a limit is entered.
Application programs wanting to report abnormal events shall use a database parameter for that purpose. The database parameter shall be configured in such a way that an abnormal event report is sent when the parameter reaches a certain value or range of values. The application program shall update the parameter accordingly when it wants an abnormal event report to be sent.
With each LCU subsystem there will be a text file for each software module associating alarm numbers with an alarm message.
Abnormal events can only be generated for database locations of type integer or real (including Polar, Rectangular and Times). For polar and rectangular types, each field is monitored independently and has its own alarm status; however they use the same error numbers.
The signals and/or database parameters for which alarms have to be reported must be configured for event monitoring.
2.6.3 Alarm Messages File
The alarm messages file is stored in one of the following directories: $INTROOT/ALARMS or $VLTROOT/ALARMS.
Help files are stored into one of the following directories: $INTROOT/ALARMS/HELP or $VLTROOT/ALARMS/HELP. Every software module/system previously defined in the central table groups its help files in a subdirectory having the same name as the module name. Additional subdirectory levels can be given in the Help file name. The file is ASCII text, lines must not be longer than 80 characters.
Alarm messages file: ASCII formatted, one entry of three consecutive lines per alarm message. Entries are ordered by increasing alarm number.
� alarm message: string including references to OLDB entries related to the alarm (between <>); their actual value will be plugged in at run time,
2.6.4 Functions
The following service functions allow to configure database parameters and signals for event monitoring and to request the sending of events:
� configure a signal or database parameter for abnormal event monitoring; any integer or real database parameter can be configured for abnormal event monitoring, including elements of vectors and tables,
� request abnormal event reports on change of value for a signal or database parameter; alarms will start being send after this request to the requesting process; requesting abnormal event reports will enable abnormal event reporting for the requesting process,
� get list of signals/and or database parameters reported for abnormal events to a specific process or all processes,
2.6.5 Simulation
The monitoring and reporting of abnormal events are not affected by simulation mode, except that signals are not sampled.
2.6.6 Generating Alarms/Abnormal Events
Alarms/abnormal events are generated through the database only, e.g. abnormal events are generated when writing a database attribute configured for abnormal events with a value outside the configured limits.
This is straightforward for events connected to already existing database attributes or signals (which are also represented by a database attribute). Configure the alarm limits with evtConfig and the corresponding alarm numbers with evtConfigAlarm. The alarm must also be entered into the alarm definition file with the corresponding alarm number. The alarm/abnormal event is generated when a value outside the configured limits is written into the database attribute.
To generate alarms/abnormal events from an application, add a database attribute for each alarm. This attribute can be a simple logical. Configure alarm limits and assign an alarm number. To generate the alarm/abnormal event, write a value outside the limit to the database attribute.
Processes to receive alarms/abnormal events must request them with evtRequestAlarm. The abnormal event is sent as an alarm message. To receive the abnormal event wait on a message with msgRecvMsg.
2.6.7 Examples
Configure database parameter for alarms with alarm numbers 10 to 13 respectively for high high, high, low and low low alarm status:
2.6.8 Reference
evtAttachAlarm() [EVTATTA] - request abnormal events for a signal or database parameter
evtConfigAbnormal() [EVTCNFA] - configure database parameter for abnormal event monitoring
evtDetach() [EVTDET] - remove an abnormal event definition
evtDisAlarm() [EVTDA] - disable the sending of alarms
evtDisAllAlarm() [EVTDAA] - disable the sending of alarms for all processes
evtEnAlarm() [EVTEA] - enable the sending of alarms
evtEnAllAlarm() [EVTEAA] - enable the sending of alarms for all processes
evtGetAlarmConfig() [EVTGCFA] - get the abnormal event configuration of a database parameter
evtParseAlarmMsg() [] - parse an abnormal event message
evtSingleDisable() [EVTSDI] - disable a specific abnormal event
evtSingleEnable() [EVTSEN] - enable a specific abnormal event
no function [EVTGA] - get list of alarms reported to given process
no function [EVTGAA] - get list of all alarms
2.7 Time Handling
2.7.1 Purpose
The purpose of time handling is to provide the Universal Time Coordinated (UTC) and to synchronize the execution of processes to the UTC.
2.7.2 Basic Concepts
The Time Reference System is based on the Global Positioning System (GPS) satellites. From the receiver the time reference is distributed via a Time Bus. The LCUs connected to TRS will receive the time through the Time Bus via a Time Interface Module (TIM), which decodes the signal into computer readable format. The Time Reference System will provide the Universal Time Coordinated.
LCUs requiring time synchronization better than 1 second shall be connected to the TRS, interfaced with a TIM. LCUs requiring less accuracy will synchronize their internal timers to UTC with TRS via the network.
The time handling will provide the possibility to run processes on task level and on interrupt level, the latter only if the LCU is connected to TRS via a TIM. It is also possible to send messages to processes at specified times.
The TIM has 6 programmable timers, synchronized to UTC, where 1 is used for scheduling interrupt routines, 4 timers to run user routines on task level and the 6th is used as the timer for the VxWorks operating system. Additionally there are two other interrupt sources, one interrupt every second and one interrupt every 10 milliseconds. They also schedule user routines on task level.
2.7.3 Functions
Services functions are available to connect interrupt routines and tasks to the timers and to the one second and 10 millisecond pulses.
timerSetInterrupt connects an interrupt routine to a timer 0. This service is only available with the Time Interface Module. The following modes of interrupt are supported:
� interrupt once after the specified time starting on the hardware gating signal connected to the timer; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high',
� periodic interrupts with a given rate starting immediately; the first interrupt will occur after one interval,
� periodic interrupts with a given rate starting on the next 100 millisecond gating signal; the first interrupt will occur after one interval,
� periodic interrupts with a given rate starting on the hardware gating signal connected to the timer; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high'; the first interrupt will occur after one interval,
� interrupt a specified time after each time the hardware gating signal connected to the timer is set; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high',
timerSetInterruptTimer connects an interrupt routine to timer 0 or 5. This function is equivalent to timerSetInterrupt, but it is possible to select timer 0 or 5.
timerSetTask connects a task to a timer. Tasks can be connected to timers 1 to 4. A task using this service shall wait on a semaphore, which id is returned from this function. The semaphore will be given by the time handler at the specified time(s) (on interrupt from the timer). This service is only available with the Time Interface Module. The following activation modes are supported:
� activation once after the specified time starting on the hardware gating signal connected to the timer; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high',
� periodic activations with a given rate starting immediately; the first activation will occur after one interval,
� periodic activations with a given rate starting on the next 100 millisecond gating signal; the first activation will occur after one interval,
� periodic activations with a given rate starting on the hardware gating signal connected to the timer; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high'; the first activation will occur after one interval,
� activation a specified time after each time the hardware gating signal connected to the timer is set; if the gating signal changes when the timer is still counting, the timer stops when the signal is `low' and continues counting when the signal is `high',
timerConnectOnPulse connects a task to the second or 10 millisecond pulse. A task using this service shall wait on a semaphore, which id is returned from this function. The semaphore will be given by the time handler at the specified time(s) (on interrupt from the second pulse). This service is only available with the Time Interface Module. Available activation modes are once the next pulse or periodically on each pulse.
Additionally, functions allow to schedule processes and to send commands and replies synchronized on the Time Reference System. The resolution of these services is one VxWorks tick, normally 10 milliseconds., The following activation modes are provided:
An accurate task sleep function synchronised to the Time Reference System is provided for applications for which VxWorks taskDelay is not suitable or not precise enough.
It is possible to cancel any timer request, before it has occurred for one shot requests or at any time for periodic requests.
The following services are provided to get information from the time handling module or to manipulate time values:
2.7.4 Local mode
When the UTC time reference signal is not received, the TIM module is set in local mode. This is done automatically by the hardware, when it detects that the signal is lost. Function are provided to switch to local mode and to set UTC mode when the signal is received. In local mode the time handling will use an internal clock running on the time reference interface board (TIM).
2.7.5 Simulation
The time reference software is not affected by the general LCU simulation mode. Instead there is a specific simulation mode for the time reference which shall be used when the there is no TIM module in the LCU.
The time handling will in this case use the internal CPU clock to perform the service functions, except for interrupts, which will not be available.
� set the Universal time, available when the time reference system is in local or simulation mode, used to synchronize the internal clock to the Universal Time.
All time handling function except timerSetInterrupt and timerSetInterruptTimer are available in simulation mode, i.e. without TIM module.
2.7.6 Examples
Program timer 0 for a one shot activation at (timeNow + 200 seconds) with interrupt routine myHandler:
Program timer 1 for periodic activation with a 100 ms rate starting on the next 100 ms gating signal:
2.7.7 Reference
timerCancelRequest() [TIMCAN] - cancel timer request
timerConnectOnPulse() [] - connect task on timer pulse
timerGetStatus() [TIMGST] - get status of Time Handling module
timerGetTimerStatus() [TIMGTST] - get status of specific timer
timerScheduleProcess() [TIMSCHE] - schedule process synchronized to Time Reference System
timerSendCommand() [TIMSCMD] - send command synchronized to Time Reference System
timerSendReply() [TIMSRPY] - send reply synchronized to Time Reference System
timerSetInterrupt() [] - connect interrupt to timer 0
timerSetInterruptTimer() [] - connect interrupt to timer 0 or 5
timerSetTask() [] - connect task to timer 1-4
timerSleep() [] - delay calling process
timsAddTime() [] - add two time values
timsGetMode() [TIMGMODE] - get mode of Time Handling module
timsGetUTC() [TIMGUTC] - get UTC time
timsIsoStringToTime() [] - convert ISO time string to time value
timsJDToUTC() [] - convert Julian Date to UTC
timsMJDToUTC() [] - convert Modified Julian Date to UTC
timsSetMode() [TIMSMOD] - set mode of Time Handling module
timsSetUTC() [TIMSUTC] - set UTC time
timsSubTime() [] - add two time values
timsTimeToIsoString() [] - format a time into an ISO time string
timsUTCToJD() [] - convert UTC to Julian Date
timsUTCToMJD() [] - convert UTC to Modified Julian Date
no function [TIMGREP] - get formatted report of all times on time list
timer.h - constants, types and function prototypes for Timers
tims.h - constants, types and function prototypes of Time System
2.8 Logging
2.8.1 Purpose
The purpose of the logging system is to provide the user with facilities to log information and to retrieve it later.
The logging system supports also automatic logging of events happening on the LCU. Its purpose is to support maintenance and debugging. The idea is that the user can start logging of some events happening on the LCU to see how the LCU software reacts or how the LCU works together with some other system. The log message is sent to the Central Control Software.
2.8.2 Basic Concept
Logging can generate a lot of traffic on the control LAN, therefore the logging facility has to be used with care. To further reduce the traffic, the logging software will buffer logging messages coming at a high rate and send them as one message at a predefined rate. This rate can be configured.
With the log it is possible to specify a user defined log id. The logId is used to classify the log as `Normal' or `Automatic' according to what is summarized in the following table.
Automatic Logs are generated by specific modules and they have the purpose to help debugging and maintenance. For example the database and the message system can be configured to generate logs when specific activities take place.
The LCU Common Software also uses logging to log its activity (automatic logging) using log ids 1-10. Log ids 0 and 11-100 are used and reserved for LCC and CCS. Log ids starting at 101 are available for applications.
The log ids are not used by the logging system as such, but are stored in the log file. They can be used for filtering. For more information see [2], logMonitor.
2.8.3 Functions
The following service functions are provided to the application program to log user defined events and to configure the automatic logging of the LCU Common Software:
� enable/disable the logging of database read/write access to a list of parameters or all the database,
� enable/disable the logging of change of value of a list of analog/digital signals or all analog/digital signals,
� start/stop the sending of buffered log messages; buffered log messages are sent to the requesting process,
2.8.4 Support for Operational Logs
The logging system provides routines to log operational logs in FITS format: each routines supports a given type of operational log (This is described in detail in [9])
Each FITS operational is defined in a `dictionary' and it is identified by a hierarchical keyword:
according to the following definitions:
� Dictionary: defines the dictionary where to check the correctness of the Fits action verb and keywords.
� Category: pre-defined and designated by a 3-letter abbreviation. Examples of `category' are DET (Detector), TEL (Telescope) ADA (Adapter) or INS (Instrument)
� Subsystem: identifies a component in a category and can consist of zero or at maximum 2 words. Several subsystems are separated by ",". Examples of `subsystems' are GRIS (grism), LAMP, CCD (detector Chip) or EXPO (Exposure Description)
� Parameter: identifies the parameter within the subsystem. Examples of keywords for `parameter' are ALT (Altitude)TEMP (Temperature) or WLEN (Wavelength)
A log record have the general format:
The following types of FITS operational logs are supported:
� Action Records. Generates a log describing an action: typical examples are opening and closing operations or moving the telescope.
� Parameter Records. Generate a log recording information on the status of the components of a given system: typical examples are wind speed, guide star RA/DEC or exposure number.
2.8.5 Programming Rules
The logId is used to select between `Normal' and `Automatic' logs according to the following table:
Use mnemonics to identify logIds as follows:
where logAUTO_RANGE defines the range where logs are classified as `Automatic'
The length of the log array is defined by the following constants:
2.8.6 Simulation
2.8.7 Examples
2.8.8 Reference
logCheckStart() [LOGCHK] - check if the reporting of log messages has been requested
logData() [] - log a single piece of information
logDisAnalog() [LOGDAIO]- disable logging of change of value of analog signals
logDisDigital() [LOGDDIO] - disable logging of change of value of digital signals
logDisMsg() [LOGDMSG] - disable the logging of messages
logDisReadDb() [LOGDRDB] - disable logging of database read access
logDisWriteDb() [LOGDWDB] - disable logging of database write access
logEnAnalog() [LOGEAIO] - enable logging of change of value of analog signals
logEnDigital() [LOGEDIO] - enable logging of change of value of digital signals
logEnMsg() [LOGEMSG] - enable the logging of messages
logEnReadDb() [LOGERDB] - enable logging of database read access
logEnWriteDb() [LOGWDB] - enable logging of database write access
logFitsAction() [] - generates a FITS log describing an action
logFitsComment() [] - generates a FITS log with a comment
logFitsEvent() [] - generates a FITS log describing an unforeseen event or a recovery action
logFitsParRecord() [] - generates a FITS log with the current values of a subsystem parameter
Basic routine supporting the logging of parameters for the following
data types: vltINT32, vltDOUBLE, vltLOGICAL or a string.
logFitsSetMask() [] - sets the mask to be used generating FITS logs
logGetEventList() [LOGGLST] - get list of events enabled for logging
no function [LOGSTOP] - stop the reporting of log messages
no function [LOGSTRT] - start the reporting of log messages
2.9 Error System
2.9.1 Purpose
2.9.2 Basic Concepts
� Within an application, errors are generated in a sequence until either the error can be automatically recovered or the main of the application is reached. This set of related errors are grouped together under the same error stack and a sequence number defines the order of the error generation.
� The error generated in a routine is reported back to the calling routine, which either succeeds to recover it or it logs the reported error and generates another one for the next level up.
2.9.3 Error Structure
2. StackId This a unique counter shared by all processes in the same environment, while the pair Environment Name + StackId is unique in the system.
7. Run Time Parameters String containing an explanation of the error. The string can be composed of up to 10 parameters separated by commas. The static part of an error message (see 2.9.7) will be filled up with these parameters. An error parameter containing commas can be surrounded by double quotes to avoid the commas to be interpreted as a parameter separator.
8. A stack containing all the sequence of errors generated by the lower levels. This includes errors coming from another process and sent back to the sender of the command through the message system.
Every layer of software receiving an error from a lower layer is allowed to modify the error structure to produce an error context having a meaning for the next higher layer. Each time a new error
is `added' to the ccsERROR structure, the previous is stored in the stack and the `error sequence
Therefore to handle the generation of errors by a sequence of nested routines or processes, the chain
of errors is linked by the parameters Sequence Number and stackId to form a `virtual' structure
2.9.4 Stack Manipulation
The error generated in a routine is reported back to the calling routine.
Each ccsERROR structure has its own error stack and error are not logged until the application closes the stack or special conditions occur, such as:
� When the environment variable errDEBUG is defined -.e.g.- setenv errDEBUG on - errors are immediately logged. This mode has been introduced to help debug the programs and see the logs associated to errors which are eventually recovered.
� When the number of logs exceeds maximum size of the error stack (errSTACK_SIZE). In this case all errors in the stack are logged and the stack emptied: further errors are stored in the stack with increasing sequence number.
Errors are generated in a cascade sequence until either the error is automatically recovered or the 'main' of the application is reached.
� Error Cannot Be Recovered
When the execution of a task involves processes running in a LCU -i.e.- send a command to the LCU - the mechanism of error reporting works as follows:
3. Errors generated by Proc2 are delivered to the local log server (lccServer) which sends them to the logManager of the WS reporting node
4. Proc2 sends back to Proc1 an error reply. This reply tells Proc1 that errors in Proc2 have occurred and are logged on WS2, with a given stackId (23).
5. When Proc1 receives the error reply, the local error structure is automatically set within the message system subroutines to the values specified in the error reply in order to identify the error stack.
� Recover the error and consequently close the stack (errCloseStack()): last error condition is be logged, and the error context is cleared.
From the application point of view the handling of errors is based on the following:
� Errors belonging to the same stack are logged on the same node (WS), regardless where the first error log was generated (WS or LCU)
2.9.5 Error Log Filtering
To reduce the load on the LAN it is possible to limit the number of error logs in case a process continuously would log the same error repetitively with high rate. To achieve this the error system can discard error logs with the same error number from a process, if they occur more that a certain number of times during a specific time interval.
There are two lcc boot parameters (set in the file lcc.boot) to configure this filter, lccLogDiscardDN to set the maximum number of error logs during the time interval set by lccLogDiscardDT. See also section 7.3.3.3.
2.9.6 Error Mnemonics
The mnemonic is derived from the text by taking the most significant words and concatenate them through `_'.
2.9.7 Error Definition File
Each VLT software module must provide an ASCII file containing the definition of all the module's errors.
The error system makes use of the software module name to find the error definition file name by adding "_ERRORS" to the module name.
Error definition files are stored into one of the following directories: $INTROOT/ERRORS or $VLTROOT/ERRORS.
Help files are grouped under one of the following directories: $INTROOT/ERRORS/HELP or $VLTROOT/ERRORS/HELP. Every software module/system previously defined in the central table groups its help files in a subdirectory having the same name as the module name. The file is ASCII text, lines must not be longer than 80 characters.
Error definition file: ASCII formatted, one entry on three consecutive lines per error message. Entries are ordered by increasing error number.
� error number: 1 -> 30000.They shall be grouped in families of related errors with a gap between error codes belonging to different families in order to add errors later on.
� error message: string including holes marked by "%s" format specifiers. It always starts with the mnemonic of the error followed by a text specifying the error condition. The error format looks like a printf format containing conversion specifications to be applied to the arguments which describe the current error context. Only %s format specifiers and a maximum of 10 format specifiers are allowed.
The run time values for requested position and motor name will be passed as arguments of the error add function and logged in the error stack.
2.9.8 Loading of Error Definition File
For the error system to work on the LCU, the error definition file must be loaded on the LCU. This is done with the function lcubootAutoLoad, see [6]. All modules shall be loaded with this function instead of using the VxWorks ld command. Error files which are not loaded with modules (with lcubootAutoLoad) can be loaded with the function lcubootErrorLoad.
2.9.9 Include Error File
The Include Error File contains all the '#define' statements for all mnemonics to be included into source files and the module name.
The name of such a file is moduleErrors.h, (e.g.: lccErrors.h) and it is generated automatically from the error definition file using the utility errEditor.
2.9.10 errEditor Utility
errEditor is an interactive utility which allows to create and modify the error definition file of a module [2]. This utility shall be used to create error files compatible with the CCS error system.
The utility generates three ASCII files:
2.9.11 Functions
A service functions is provided to the application program to log the previous error and to modify the error structure according to the current error condition. If the stack does not exist yet, a new stack is created, otherwise the previous error is logged.
It is the responsibility of the application programmer to transmit the global structure and the error parameters from one level to the next higher one, either as a return parameter in the subroutine call, or via the message system if the error resulted from the execution of a command.
� reset an error stack.This function initializes the current error structure and must be used at the beginning of each application and whenever an error condition has been recovered.
2.9.12 Simulation
2.9.13 Use of Error System
LCU application routines shall follow certain rules for returning errors. An application routine shall have the following interface:
ccsCOMPL_STAT indicates if the function was successful or if it failed. The actual error is returned in the error structure error.
A function shall be called with an empty error structure. A command will also always be received with an empty error structure. A utility program has to reset its error structure with the function errResetStack before using it.
The error structure is filled when calling the function errAdd. The first call to errAdd with an empty error structure fills the error structure with the error and a new error stack is created, but nothing is logged. When errAdd is called again with a non-empty error structure, the error in the error structure is logged and the error structure is filled with the new error.
The function errAdd also allows to specify run time parameters. The log message sent from the LCU contains the error structure and the runtime parameters. When the workstation log manager receives the LCU log messages it picks up the correct error definition file from the module name found in the error log. The error definition file must have the name <module>_ERRORS. The log manager on the workstation retrieves the log text from the error definition file and fills in the run time parameters into the text. Then the text is written into the log file.
The run time parameters have to be converted to ASCII format before they are sent to the workstation. The format parameter of errAdd is used for this conversion. The format specifiers of the error definition file shall only be of type "%s" as the parameters are sent in ASCII format.
2.9.14 Examples
The LCC routine funct1 make a call to another LCC routine and generated errors are handled by routine errAdd which logs the previous error and sets the error structure to the current LCC error.
2.9.15 Macros
Several C macros are provided in err.h to allow for a simpler error reporting code. Their definition is given below. All these macros have at most one variable parameter arg. If the variable parameters of the error to be reported have more than one argument then errAdd must be used.
Note that each application must have set its module ID (lccMODULE_ID) before using one of these macros
2.9.16 Reference
errAdd() [] - add new error into error stack
errCloseStack() [] - log last error in error stack and close stack
errCopy() []- copy the content of an error structure into another one
errDriverAdd() [] - log error generated by a driver and add new error into error
errInStack() [] - checks if the error stack contains a given error
errIsReason() [] - search for a specific error in the error stack
errMergeStack() [] - merge two error stacks
errPrint() [] - print the error structure on the console
errResetStack() [] - initialise an error structure
errSetStack() [] - initialise an error structure with a given error context
errSysAdd() [] - log error generated by VxWorks system call and add new error into error stack
no function [ERRFRST] - get the errors during boot
no function [ERRSTOP] - stop the logging of errors
no function [ERRSTRT] - start the logging of errors
2.10 Message System
2.10.1 Purpose
Communication of other data, such as astronomical data acquisition (CCD images) is not part of the message system. If permitted by system performance, there is the possibility to fulfil those needs by extending the use of the message system to them later.
The message system provides program-to-program communications at application level by exchanging data grouped in structured byte streams called MESSAGES. Programs can be both on the same and on different CPUs.
2.10.2 Types of Message
2.10.2.1 User Messages
These are divided into two categories: COMMANDS and REPLIES. A command expresses a request from a program to another program to perform something. The destination has to provide information on the execution of the requested action by sending back repl(y/ies). Replies are always related to a previous command. To each command there is at least one reply. Commands and replies can have parameters.
In case of ASCII format, the parameters must be separated by comma (",") in the message body. The formats accepted by LCC are defined in 6.2.1.
Commands and replies have a logical nature, and do not refer to any specific physical address of an equipment.
The design of the commands and replies for each application is part of the development of the application. The same command definition syntax is used system-wide.
In addition to normal commands, every application shall support the handling of the special commands:
� BREAK: soft stop of the current action. It shall stop the current action but the application shall be prepared to receive new commands
� KILL: clean termination of the application. The application shall stop all on-going actions and release all resources used before terminating.
These are sent in the same way as any other command. The message system provides a mechanism using signals ensuring that these special commands can be processed immediately by the destination application, even if there are pending commands.
Each user application shall define handler routines for the treatment of KILL and BREAK commands. The appropriate actions to be performed on a BREAK or KILL command must be performed in the handler routines or the handler routine must inform the application to perform these actions. The actions to be performed must be defined for each application.
2.10.2.2 Internal Messages
For internal purposes, the message system uses a special kind of message not accessible to user applications.
An example of such internal messages is the acknowledgement message used to confirm that a command has been delivered to the message queue of the destination process, when the destination is running in a machine other than the sender.
2.10.3 Protocol
A generalised protocol is defined for the program-to-program communication level, both between workstations and LCUs. Each application shall follow it.
Communications are always initiated with a command sent from an originating application to a destination application.
The send operation performs standard checks on the message (not on its content) and attempts to queue the message at the destination side. The send process is blocked until an acknowledgement is received or a time-out has elapsed to certify that the message has been correctly delivered to the destination or that the transmission has failed. The acknowledgement and the timeout are generated by the internal transport layers.
msgRecvMsg function removes from the queue the first message according to the current filtering option. Both commands and replies are received in this way. If the message is a reply, it is passed to the application. If the message is a command, it is checked against the current booking situation:
� if the check is negative: a reply reporting the error is automatically sent back to the originating application. This reply terminates the command logically. Nothing is returned to the destination application and the message space is available to accept the next commands.
� if the command is accepted: the incoming command is passed to the destination application that processes it.
The destination application shall processes the request expressed by the command and produces as many replies as needed (at least one immediately to certify acceptance). If the execution of the command requires several replies, the last one shall be clearly indicated.
2.10.3.1 Registration Functions
Before sending or receiving messages, processes must register into the message system using the ccsInit function. ccsInit must be called BEFORE calling any other LCC function. This function allows the process to specify the handlers to be used for the BREAK and KILL signals. ccsInit must be called only once by a process.
ccsExit function should be called by processes upon clean termination to de-register from the message system.
2.10.3.2 Communication Functions
� put the message into the queue of the destination application; if the destination application is on another machine, an internal acknowledgement message is expected within 10 sec to confirm that the command has been delivered,
� destination: process name and environment location of the destination application; the destination process must be already scheduled in order to be able to receive messages,
� user identifier: to allow the later selection of the repl(y/ies) to this command in case of issue of multiple, otherwise identical, commands at different times,
� wait for the first message according to specified filter option and time out. The filtering mechanism uses the information present in the identification part of the message without extracting the message from the queue. In case of requeued messages, only the information on the most external identification part is available for filtering.
When a message matching the filter is available, it is removed from the queue and:
� if the message is a command, a booking check is performed. If the check is not successfully passed, a reply containing an error is generated and sent back to the sender. According to the specified timeout, msgRecvMsg continues to wait for the next message.
� return the message matching the filter and the booking conditions as soon as it is present on the queue or report no message if the timeout condition is reached.
Applications waiting for a reply should use a finite waiting time. Applications waiting for a command can use the infinite wait.
Same behaviour as msgSendCommand but using some elements from the received command to generate a reply according to user-provided parameters. There is no internal acknowledgement message for a reply.
The process producing the reply is responsible for marking the last reply in case of multiple replies. If only one is sent, it is marked as the last one.
msgRequeueMsg is used by applications to put back a received message into the queue when it decides to delay the treatment of the message.
The requeued message is embedded into a new message. The new message gets the requeueing process as sender and this leads to loss of filtering capabilities involving the original sender of the message. The extra information added to build this new message is stripped off at the next reception.
It is recommended that requeue and filtering should not be used at the same time. Requeueing is normally used when an application receives any kind of command/reply, and decides to delay the treatment of some received message. Filtering is the normal mode to be used when one is expecting a specific message, usually a reply from a given application to a command previously sent. The requeue operation temporarily hides the real originating process name and location. This makes filtering on the real originating process impossible on requeued messages.
2.10.3.3 Auxiliary Functions
� check if a process is registered: msgCheckProcess can be used to verify that a given process is registered in the Message System,
� scheduling of a process on another environment, allowing an application to start any process on any computer (WS or LCU),
2.10.4 Examples
2.10.5 Reference
ccsExit() [] - deregister a process from the message system
ccsGetMyProcId() [] - get information about self process
ccsInit() [] - register a process into the message system environment
msgCheckProcess() [MSGCHCK] - check that a process is registered
msgGetProcesses() [MSGGPL] - get the list of all registered processes
msgGetProcIdByName() [] - get the process id of a process
msgHandleBreak() [] - default handler for BREAK signal
msgHandleKill() [] - default handler for KILL signal
msgParseMsg() [] - parse message
msgPing() [] - check that a process is alive
msgRecvMsg() [] - receive message
msgReplyWithId() [] - send reply message with given source process id
msgRequeueMsg() [] - requeue message
msgScheduleProcess() [] - schedule process on given environment
msgSendAnyMessage() [] - send a user formatted message
msgSendCommand() [] - send command message
msgSendReply() [] - send reply message
msgSetFilter() [] - set-up a receive filter
ccs.h - constants, types and function prototypes common with CCS
msg.h - constants, types and function prototypes of Message System
2.11 Command Interpreter
2.11.1 Purpose
2.11.2 Basic Concepts
The command interpreter schedules other processes selected by the command. It will be scheduled with those parameters received with the command and additionally the requester's name and node and the command.
The command interpreter does not wait for a scheduled process to finish its execution. Instead it is ready to receive and handle any new command immediately.
It is the responsibility of the scheduled process to send back a reply to the requester or an error message in case of error. The reply or error has, however, to be returned via the Command Interpreter to insure that the originating process also receives the reply from the destination of the command. A reply or an error reply is automatically sent by the Command Interpreter after the scheduled function returns. When several replies must be sent, the source process id of the reply must match the process id of the Command Interpreter. A specific function, msgReplyWithId, is provided by the Message System for that purpose (see also the examples in section 2.11.5).
The scheduled process shall also check that all conditions necessary for executing the command are fulfilled and if not, send back an error message and not execute the command.
Instead of scheduling a process it is also possible to run it as a subroutine. This makes the interface simpler and faster but at the expense that the command interpreter can't handle any new command until the subroutine has terminated.
The command interpreter uses two tables to handle the commands received. The first table, the Command Definition table (CDT), defines the syntax of each command handled by the command interpreter. The second table, the Command Interpreter table (CIT) specifies how the command must be executed, i.e. as a function call or as a process. It is possible to specify VxWorks run-time options for the process to schedule on the command. These options can be task name, priority, stack size, if the process shall use floating point processor, etc. Options not set will have a default value.
The CIT may also define LCU states for which commands are not accepted (an error reply is sent directly by the Command Interpreter). Other flags allow to specify that no parameters check or translation should be done (RAW) or that the Process Id of the emitter of the command should be used instead of the one of the Command Interpreter during the execution of the command (SETID). The SETID option is used by LCC and should not be used by normal applications.
If the parameters of a command are in ASCII format, the command interpreter will parse the command and its parameters, and it will perform a range check of the parameters, as specified in the Command Definition table. Finally the parameters will be converted into formatted binary format (see 2.11.5).
Normally each application on the LCU will be an instance of the Command Interpreter. An instance of the command interpreter will always be created at start-up of the LCU to handle the LCU Common Software commands.
The tables are normally loaded at start-up of an instance of the command interpreter, but there is also be the possibility to reload them after modification.
2.11.3 Command Definition Table
For each process, an ASCII file, the Command Definition Table, describes the list of accepted commands. Command names and synonyms must be unique within a module.
Command definition tables are stored into one of the following directories: $INTROOT/CDT or $VLTROOT/CDT. The name of the file is composed of the process name followed by the `.cdt' suffix, e.g. lccServer.cdt.
One entry per command, attributes are given after the KEYWORDS. Keywords are typed in upper case and are followed by "=". Spaces are allowed before and after the "=" character. Keywords marked with * are optional, other keywords are mandatory. Keywords must be given in the order defined below.
(d) COMMAND=command name (7 chars max). Command names are not case sensitive and are always processed as ASCII upper case only (allowed character set: A-Z and 0-9, first character must be a letter).
(e) SYNONYMS=A list of accepted synonyms, any number of chars, separated by commas. They are only used when commands are typed from a User Interface and they are replaced by the equivalent command when the message is sent. This list is optional. It is there just in case the 8 chars allowed for the command are not enough to give meaningful names in all circumstances.
(f) FORMAT=How parameters are formatted: "A" for ASCII, "C" for structured (formatted) binary, "B" for unformatted binary.
With ASCII format all parameters shall be sent as strings in the message body.
With structured binary format the parameters shall be sent in binary format of the type defined by the keyword PAR_TYPE.
With unformatted binary format the parameters can be sent in any format. No syntax checking will be done.
The receiving process must be able to handle the format of the message body.
(g) PARAMETERS*=A list of parameters: Parameters are position dependent. This list determines the sequence. The keyword "PARAMETERS=" just introduces the list. The list contains the following entries:
i. PAR_NAME=parameter name. Start a new parameter description. The parameter name shall be short, but a maximum length of 256 characters is allowed. Allowed character set: a-z, A-Z, 0-9, underscore and decimal point. The first character must be a letter (a-z, A-Z).
ii. PAR_UNIT*=parameter unit.(Official SI units and allowed multiples)
Defines the unit of the parameter in the message body. A user interface or any other process accepting other units shall convert to the unit specified here before sending the command. PAR_UNIT is not applicable for parameters of type LOGICAL.
iii. PAR_TYPE=parameter type: STRING, INTEGER, REAL or LOGICAL
INTEGER is 32 bits, REAL is 64 bits (double), LOGICAL is ccsTRUE or ccsFALSE (vltLOGICAL)
v. PAR_OPTIONAL*=YES,NO. The flag indicates if the parameter is optional. If the flag is set and a default value is defined, the default value is sent in the message buffer if the parameter is not given in the input. If the flag is set and no default value is defined, no value is sent if the parameter is not given in the input. The left-out parameter will be left empty in the message body of the command e.g. for a command with three parameters and the second parameter optional the message body will be par1,,par3, while if parameter 3 is optional the message body will be par1,par2 (note that par1,par2, is also valid).
vi. PAR_DEF_VAL*=default value if the parameter can be defaulted. Any parameter can have a default value. If no value is given for the parameter in the input, the default value, if it is defined, shall be put in the message body. The value must match the parameter type.
Parameters of type LOGICAL can only have the default value FALSE, corresponding to ccsFALSE. TRUE, corresponding to ccsTRUE is not accepted. The default value for LOGICAL is valid also when not specified.
vii. PAR_REPETITION_FACTOR*=number. Keyword indicating that the parameter is repeated a fixed number of times. The parameter must be repeated exactly the number of times specified. If the parameter is given in the input less number of times, the missing repetitions are replaced by the default value. A parameter with fixed repetition rate cannot be optional. Repeated parameters are separated by spaces in the message body.
Example: a command has three parameters and the second parameter is repeated twice. The message body will contain par1,par2 par2,par3.
PAR_REPETITION_FACTOR is not applicable to parameters of type LOGICAL.
Parameter with PAR_REPETITION_FACTOR can be optional.
viii. PAR_MAX_REPETITION*=number. Keyword indicating that the parameter can be repeated a variable number of times. The value gives the maximum number of repetitions, but it can also be repeated less times than this value. The keyword is not allowed if the keyword PAR_REPETITION_FACTOR is defined for the command. Repeated parameters are separated by spaces in the message body. A parameter with this keyword defined will only be sent the number of times given in the input and cannot be defaulted.
Example: a command has three parameters and the third parameter can be repeated up to 10 times. If four values are given for the third parameter, the message body will contain par1,par2,par3 par3 par3 par3, or, if two values are given, par1,par2,par3 par3.
(h) REPLY_FORMAT=How the reply is formatted: "A" for ASCII, "C" for structured (formatted) binary, "B" for unformatted binary.
(i) REPLY_PARAMETERS*=A list of reply parameters: Parameters are position dependent. This list determines the sequence. The keyword "REPLY_PARAMETERS=" just introduces the list.
The reply parameters specification is optional. The rule is that parameters of the reply shall normally be specified. Most replies have a defined format. The definition may be left out for cases where it is not possible to describe the reply.
The list contains the following entries:
iv. PAR_DEF_VAL*=value or database reference. Default value used only in simulation mode that cannot be used by applications. The value defined will be returned by the CCS simulator. The default value can be given as a value or as a database reference. The database reference shall be given as a database symbolic address between brackets starting with the character ":" for an absolute address or with specification of the environment as @env:absolute address or with the view specifier <relative> or <alias>, e.g. [<alias>filters.redFilter]. When a value is given, it must match the parameter type.
v. PAR_REPETITION_FACTOR*=number. Keyword indicating that the parameter is repeated a fixed number of times. The parameter must be repeated exactly the number of times specified.
(j) REPLY_LENGTH*=number. Parameter for unformatted binary replies, defining the length of the default reply.
(k) DISPLAY_FORMAT*=format string. A formatted string enclosed between double quotes containing an ASCII string to be displayed when the last reply is received. The string can contain C-type printf formatting, where to plug in the parameters of the reply. The reply received must contain the parameters of the format specified in the string. The format string must correspond to the parameters described in the REPLY_PARAMETERS section, with the parameters in the same order.
Example: a reply of type formatted binary containing two values, one integer and one real, could have the following display format: "Temperature at sensor %i is %f degrees C".
It is also possible to include command definition tables in a command definition table with the #include statement. The following rules applies:
� the group key-words, PUBLIC_COMMAND, MANTENANCE_COMMAND, TEST_COMMANDS, must only occur once in the concatenated CDT file
Command formats are defined in section 6.2.1.
2.11.4 Functions
Service functions are provided to create an instance of a command interpreter and to ask a command interpreter to load new Command Definition and Command Interpreter tables.
The command interpreter also provides a test and debugging function that allows to specify the error number returned by the next command received. When this function is called, the next command received is not executed but a reply is sent immediately with the specified error number.
2.11.5 Interface Functions
Functions used as the entry point for the execution of commands (as specified in the Command Interpreter Table) MUST have the following interface, whether they are spawned as a task or executed as a function.
� parameters <IN>: Buffer with parameters either in formatted or unformatted binary format
(see [6.2.1]). For commands with optional parameters (PAR_OPTIONAL=
YES) or parameters with a variable number of values
(PAR_MAX_REPETITION=x), the buffer begins with an array of vltINT8
giving the number of values for each parameter. For other commands, the
buffer starts with the first parameter.
� msg <IN> : Message containing the command (will be freed by the Command
Interpreter after the reply has been sent).
� replyBuffer <OUT> : Pointer to buffer containing the reply: the buffer can be either dynamically
allocated by the interface function or the buffer of the message containing
the command (msg) can be reused. The size of this buffer is
msgBODYMAXLEN. Dynamically allocated buffers will be
freed by the Command Interpreter after the reply has been sent,
In this second example, the second parameter is a list of names defined with PAR_MAX_REPETITION=5. The parameters buffer begins with an array of vltINT8 indicating the number of values of each parameter (See the arrangement of the parameters in logEnAnalog in section 6.2).
In this third example, several intermediate replies are sent by the interface function and the last reply is sent by the Command Interpreter. The interface functions call a function that returns a list of parameters and send one reply for each parameter of the list. The last reply (sent by the command interpreter) is empty.
The object file containing the functions must be loaded on the VxWorks target before the command tables are loaded by a Command Interpreter.
2.11.6 Use of Command Interpreter
The purpose of the Command Interpreter (CI) is to simplify the development of LCU applications. CI relieves the application from:
� converting ASCII parameters to binary values. The parameter conversion is restricted to the types: INTEGER (Int32), REAL (Double), LOGICAL (vltLOGICAL) and character string.
From CI it is possible to call a routine or to spawn a task to perform the action connected to a command. It is recommended to use the function call for very short actions e.g updating or reading parameters, while longer actions shall be spawned. When returning from the function/task the CI returns the reply to the initiator of the command. Any intermediate replies (before the action has finished) has to be sent from the called/spawned routine itself.
If the routine connected to the command needs to communicate with other tasks via the message system, it must connect to the message system with the LCC function ccsInit, send messages with the message system and before terminating call ccsExit. Such a routine MUST be spawned as a process; it cannot be executed as a subroutine.
When a Command Interpreter is started (with cmdInit), a user specific argument can be specified. This argument can be retrieved later on during the processing of a command by the associated function (even if it is executed as a task), using cmdGetArgument.
Command Interpreters terminates cleanly if the command EXIT is received, after the command has been processed by the associated function or task. A Command Interpreter can also be terminated explicitly from a user defined BREAK or KILL handler, or from a function (not from a task), with function cmdTerminate.
Applications shall use the CI as its interface to the external world. It is recommended to have one CI for each software device (for definition of software device see section 2.2.3). Each function of the software device shall have a command interface and in parallel also a procedural interface.
With this it is possible for other applications within the same LCU to use either the command interface (via the message system) or directly the procedural interface. The command interface shall normally be used, because it gives a more general interface which is simpler to port to other systems. The procedural interface shall be used if performance is important and additional overhead must be avoided.
The number of CIs on an LCU is not limited. If required by the application it is also possible to implement an hierarchy of CIs. The following picture illustrates the use of CI.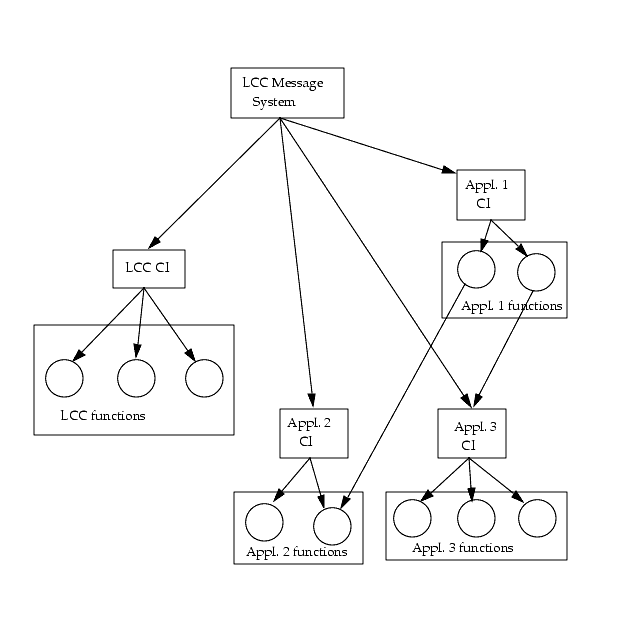
The picture shows an LCU with LCU Common Software (LCC) with its CI and functions, three applications with each application having its own CI. The arrows indicates the calling structure and the circles are functions of LCC and the applications. The picture also shows an hierarchy of applications where application 1 calls application 2 and 3. Application 2 is called through a procedural call, while application 3 is called via the message system.
2.11.7 Reference
cmdInit() [] - create a new instance of the command interpreter
cmdGetArgument() [] - get value of user argument given to cmdInit
no function [CMDSERR] - set error number to be returned with next command
no function [CMDLOAD] - reload new Command Definition and Command Interpreter tables
cmdTerminate() [] - terminate a command interpreter
2.12 Interface
2.12.1 Procedural Interface
The procedures provided by the LCU Common Software are accessible as C functions on the LCUs (VxWorks). They are loaded as a single object (lcc) at boot time.
No specific compilation flags is required to compile application software including LCC header files.
If a procedure is called via a task that registers the message system, a stack size of minimum 30 KB is required.
2.12.2 Command Interface
Commands can be sent to these processes from the Engineering User Interface, described in the next chapter, or using the procedural interface of the Message System, as shown in the examples below.
1RTAP is the Real Time Application Platform from Hewlett Packard, a real time database and programming environment. The LCU local database is compatible with RTAP and the Point Configuration Files have the same format. Although RTAP is not supposed to be used for the development of LCU software, compatibility at the database level is implemented, and that is the reason why RTAP is referred to here.
|
Quadralay Corporation http://www.webworks.com Voice: (512) 719-3399 Fax: (512) 719-3606 sales@webworks.com |
