v1.2.6: handles files with same product root and having the same PRO_CATG
- embedded in QC procedures
- before scoreQC
| qc1..<configured table> (read and write) | |
| |
processQC, scoreQC, qc1Ingest |
| none | |
| none |
Common Trending and QC tools:
|
| tqs = Trending and Quality Control System |
| new: | see also: | |||||||||
|
v1.2.6: handles files with same product root and having the same PRO_CATG |
- embedded in QC procedures
|
QC1 parameters are calculated by pipeline recipes and are written as fits keys into product headers. There are frequently also parameters that are not available from headers, e.g. civil date, and parameters that are not calculated by pipeline recipes. These parameters exist as local variables within QC procedures using MIDAS, Python, etc. QC1 parameters are ingested into the QC1 database using qc1Ingest which expects all parameter values as command line arguments. Therefore, QC procedures have to collect these data before calling qc1Ingest.
The tool writeQC fills the gap between header keywords, local script variables, and qc1Ingest. It
The tool is called per AB. It expects pipeline products within the certification area (i.e. in the $DFS_PRODUCT directories) as specified in the AB. The connection between PRO.CATG and database tables and between fits key names and database columns is defined in the configuration file config.writeQC.
Usually all pipeline products with file names starting with the same product root (e.g. r.KMOS.2014-01-01T00:00:00.000_tpl) have different PRO.CATGs. New with v1.2.6: In exceptional cases, there can be product files with the same product root and with the same PRO.CATG. Then, writeQC reads QC1 parameters only from the first file in alphabetical order. E.g. if there are files r.KMOS.2014-01-01T00:00:00.000_tpl_0000.fits, r.KMOS.2014-01-01T00:00:00.000_tpl_0001.fits, and r.KMOS.2014-01-01T00:00:00.000_tpl_0002.fits and all have PRO.CATG=MASTER_DARK then the QC1 parameters for MASTER_DARK would be read from r.KMOS.2014-01-01T00:00:00.000_tpl_0000.fits.
The tool is usually called from the QC script invoked by processQC, and before scoreQC is executed. In the QC script, three lines of code are needed for proper operation. The first line calls writeQC in mode 'PREPARE'. This creates a small script that is executed in the second line. The script depends on the scripting language used for the QC script (either MIDAS, Python, or Unix Shell) and writes the values of header keywords and local variables into a temporary file. This approach is necessary for sharing the values of local variables between the QC script and writeQC while supporting different scripting languages with only one version of writeQC. The third line calls writyQC in mode 'INGEST' which finally uses qc1Ingest for writing the QC1 parameters into the database.
The three lines of code can be written in a way so that they are identical for each QC procedure. All information for reading and writing QC parameters is configured within the configuration file. An optional fourth line can be added for multi-detector instruments calling writeQC in mode 'AVERAGE'.
The following graph illustrates the place of writeQC within the QC processing scheme:
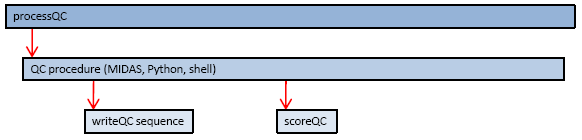
Type writeQC -h for help and writeQC -v for the version number.
The tool is invoked as a UNIX command line. The syntax is:
writeQC -m PREPARE | INGEST | AVERAGE -a <AB> [ -e <EXTENSION> ]
[ -l MIDAS | PYTHON | SHELL ] [ -c <CONFIG_FILE> ]
Calling sequence:
writeQC -m PREPARE -a <AB> [ -e <EXTENSION> ] [ -l MIDAS | PYTHON | SHELL ]
<TMP_DIR>/<AB>_<EXTENSION>/writeQC.<SCRIPT_TYPE>
writeQC -m INGEST -a <AB> [ -e <EXTENSION> ]
where <SCRIPT_TYPE> is either 'prg' for MIDAS, 'py' for Python, or 'sh' for shell scripts. The language used for QC scripts can be specified with option '-l' in mode 'PREPARE' or within the configuration file (see below). The command line option is useful if the QC scripts for an instrument are written in more than one language. If option '-l' is given then the value for 'LANG' in the configuration is not evaluated. Only mode 'PREPARE' needs to know the scripting language.
The <EXTENSION> must be specified in case of MEFs. For SEFs, the '-e' option can be omitted (which is equivalent to '-e 0').
For multi-detector instruments, writeQC also supports average and rms calculation of QC parameters. The above sequence can optionally be followed by:
writeQC -m AVERAGE -a <AB> .
This requires that the QC1 parameters for all detectors have been ingested before. They are read again from the database and identified via MJD-OBS as given in the AB (with a precision of 1E-5). This supports true MEF cases like CRIRES or VIRCAM and multi-detector instruments with SEFs (like VIMOS). For each QC parameter, the average of the values for all detectors and the rms is calculated. Two additional entries are inserted into the database where the detector name is replaced by 'AVG' and 'RMS', respectively. The names of the parameters for averaging and the keys denoting the detector are configured in config.writeQC.
Shell. Example for UNIX shell usage (4 extensions MEFs, additional averaging plus scoreQC):
for EXT in 1 2 3 4
do
writeQC -m PREPARE -a $AB -e $EXT
${TMP_DIR}/${AB}_${EXT}/writeQC.sh
writeQC -m INGEST -a $AB -e $EXT
done
writeQC -m AVERAGE -a $AB
scoreQC -a $AB
Note: all local shell variables that contain QC1 parameter values must have been exported (e.g. 'export CIVIL_DATE=2007-07-01' in Bash).
MIDAS. Example for MIDAS (single extension files, no averaging):
$writeQC -m PREPARE -a {AB_NAME}
@@ {TMP_DIR}/{AB_NAME}_0/writeQC.prg
$writeQC -m INGEST -a {AB_NAME}
$scoreQC -a {AB_NAME}
Python. Example Python calls for MEF products (16 extensions):
for ext in range(17, 1):
os.system('writeQC -m PREPARE -a ' + ab_name + ' -e ' + str(ext))
execfile(tmp_dir + '/' + ab_name + '_' + str(ext) + '/writeQC.py')
os.system('writeQC -m INGEST -a ' + ab_name + ' -e ' + str(ext))
os.system('writeQC -m AVERAGE -a ' + ab_name)
os.system('scoreQC -a ' + ab_name)
Operational hints. Automatic ingestion into the QC1 database can be switched off (see configuration). This is useful for testing the tool and it is highly recommended to use this feature for configuring writeQC. All temporary files can be found in the directory <TMP_DIR>/<AB_NAME>_<EXT>; the qc1Ingest calls are within the files <TABLE_NAME>.sh.
It is possible to run writeQC in parallel for different ABs. It is also possible to work on separate extensions of MEFs in parallel.
The tool configuration file (config.writeQC) defines the relation between PRO.CATG and database tables and between fits key names and database columns. The option -c <CONFIG_FILE> allows to use a different configuration file (which must also be in DFO_CONFIG_DIR). This is useful if QC1 scripts are written in different scripting languages; the syntax for value formatting (see table) can then be adapted.
| Section 1: general parameters Section 1.1: tool configuration SIMULATION=YES is recommended for testing. All temporary files are written into the directory <TMP_DIR>/<AB>_<EXT> and can be verified. The qc1Ingest calls are in <QC1_TABLE>.sh. |
||
| SIMULATION | YES | NO | KEEP_TEMP | YES: temporary ingest scripts are
created but not executed NO: QC1 parameters are automatically ingested, tmp dir deleted KEEP_TEMP: QC1 parameters are ingested, tmp dir is not deleted Default: YES |
| LANG | PYTHON | MIDAS | SHELL | Language used for QC scripts. Can also be specified using option '-l'. |
| NUM_DET | 4 | For MODE=AVERAGE only: number of detectors |
| MJD_SNAP | 0.00001 | For MODE=AVERAGE only: to identify entries from all detectors via MJD_OBS +/- MJD_SNAP; useful in VIMOS case, otherwise recommended to set to 0.00001 (default) |
|
Section 1.2: match between PRO.CATGs and QC1 database tables |
||
| QC1_TABLE | crires_dark | name of QC1 database table |
| GROUP_KEY_SET | DET | name of group (can be NONE) |
| PRO_CATG | CALPRO_DARK | PRO.CATG of pipeline product containing general and group QC1 parameters |
| Section 2: GENERAL keywords The QC1 database table definitions distinguish between general, QC1, and instrument keywords. A similar distinction also exists for writeQC. GENERAL keys are common to all database tables. These are typically keys like pipefile, arcfile, civil_date but it is possible to define any key here (if common to all tables). All GENERAL keys are always read and ingested. |
||
| FITS_KEY/VAR_NAME | PIPEFILE | name of fits key in header or name of variable in QC script |
| SOURCE | PRODUCT | LOCAL | Source for reading keyword value. Either PRODUCT if parameter value is found in header key (of product file having PRO.CATG defined in 1.2) or LOCAL if parameter value is stored in local script variable. |
| EXT | 0, 1, ... | A | B, L, U | Extension where key is stored; 0: primary header 1, 2, ...: key is present in one extension only A: All, MEF case; key is present with identical name in each extension B, L, U: UVES special |
| FORMAT | %s, %5.2f, %i, etc. (Python, Shell) C, I1, F5.2 (MIDAS) |
String used to format parameter values.
For LANG=PYTHON or SHELL use C syntax. For LANG=MIDAS use Fortran-like syntax; 'C' is used for unformatted character strings. |
| QC1_COLUMN | -pipefile | name of column in QC1 database (including leading '-') |
| AVG_YN | Y | N | D | For MODE=AVERAGE only. Y: calculate average and rms for this parameter N: do not calculate average and rms D: detector parameter, will be replaced by 'AVG' or 'RMS', respectively; must be defined as varchar in database |
|
Section 3: GRP_KEY group keywords |
||
| GROUP_KEY_SET | DET |
name of group (as defined in 1.2) |
| FITS_KEY/VAR_NAME | DET.DIT | name of fits key or name of variable in QC script |
| SOURCE | PRODUCT | LOCAL | source for reading keyword value. Either PRODUCT or LOCAL. |
| EXT | 0, 1, ... | A | B, L, U | extension where key is stored |
| FORMAT | %s, %5.2f, %i, C, I1, F5.2, etc. |
format string |
| QC1_COLUMN | -dit | name of column in QC1 database |
| AVG_YN | Y | N | D | For MODE=AVERAGE only. |
| Section 4: SPEC_KEY specific keywords These are the QC1 parameters. Since one table may be fed from more than one product file, the PRO.CATG of the product file has to be specified (or PRO_CATG=LOCAL if key value comes from script variable). |
||
| TABLE_NAME | crires_dark | name of table in QC1 database |
| FITS_KEY/VAR_NAME | QC.DARKMED | name of fits key or name of variable in QC script |
| PRO_CATG | CALPRO_DARK | source for reading keyword value. Give PRO.CATG of product file or specify LOCAL. |
| EXT | 0, 1, ... | A | B, L, U | extension where key is stored |
| FORMAT | %s, %5.2f, %i, C, I1, F5.2, etc. |
format string |
| QC1_COLUMN | -darkmed | name of column in QC1 database |
| AVG_YN | Y | N | D | For MODE=AVERAGE only. |
Keyword names. The keyword names given in the configuration file must not contain blanks. A dot '.' is interpreted as a placeholder (i.e. the UNIX grep command is used internally). This feature is useful if keyword names vary as is the case e.g. for some VIMOS names which depend on the quadrant.
Formatting parameter values. It is possible to format the values of (numerical) header keywords and script variables before writing to the QC1 database. This is done with
The syntax of the format strings in Sects. 2 to 4 depends on the scripting language specified in Sect. 1.1 and must be compatible with these commands or operators. In case of MIDAS, a 'C' has been added to the list of allowed formats which is denoting an unformatted character string.
If formatting is not wanted for a parameter coming from a fits header then '%s' or 'C' can be chosen. This also functions for numerical header keys which are then interpreted as character strings and written into the database with exactly the same precision as in the header. This can often be a good choice.
It is recommended to use a numerical format string for floating point variables in QC procedures.
| Last update: April 26, 2021 by bwolff |