11. Telemetry¶
Revision: |
1.7 |
|---|---|
Status: |
Released |
Repository: |
|
Project: |
ELT Telemetry |
Folder: |
trunk/deliverables/phase11 |
Document ID: |
CSL-DOC-20-181458 |
File: |
MAN_ELT_Telemetry.docx |
Owner: |
Jan Pribošek |
Last modification: |
October 15, 2020 |
Created: |
March 8, 2020 |
Prepared by |
Reviewed by |
Approved by |
|---|---|---|
Jan Pribošek (CSL SWE) Sara Pia Marinček (CSL) Domen Soklič (CSL) |
Borut Terpinc (CSL SWE) Domen Soklič (CSL) |
Gregor Čuk (CSL) |
Revision |
Date |
Changed/rev iewed |
Section(s) |
Modificatio n |
|---|---|---|---|---|
0.1 |
09.03.2020 |
smarincek, jpribosek, dsoklic |
All |
Document creation. |
1.0 |
06.05.2020 |
dsoklic/bte rpinc |
All |
Review updates. Released document. |
1.1 |
17.6.2020 |
jpribosek |
All |
Updating manual after receiving support questions. |
1.2 |
7.7.2020 |
jpribosek |
All |
Updating manual according to raised LAT issues. |
1.3 |
30.7.2020 |
jpribosek |
All |
Updating manual according to raised LAT issues. |
1.4 |
27.8.2020 |
jpribosek |
All |
Updating manual according to raised LAT issues. |
1.5 |
3.9.2020 |
jpribosek |
All |
Updating manual according to raised LAT issues. Added additional section for setting up OLDB simulator. |
1.6 |
24.9.2020 |
jpribosek |
All |
Updating manual according to raised LAT issues. |
1.7 |
06.10.2020 |
jpribosek |
All |
Updating manual according to the review comments. |
Confidentiality
This document is classified as a confidential document. As such, it or parts thereof must not be made accessible to anyone not listed in the Audience section, neither in electronic nor in any other form.
Scope
This document is the manual for the Telemetry Service system used by applications in the ELT Core Integration Infrastructure Software.
Audience
This document is aimed at those Cosylab and ESO employees involved with the ELT Core Integration Infrastructure Software project, as well as other Users and Maintainers of the ELT Core Integration Infrastructure Software.
Glossary of Terms
API |
Application Programming Interface |
|---|---|
CII |
Core Integration Infrastructure |
CLI |
Command Line Interface |
DP |
Data Point |
EA |
Engineering Archive |
ES |
ElasticSearch |
JSON |
Javascript object notation |
OLDB |
Online Database |
SVN |
Subversion |
YAML |
YAML Ain’t Markup Language |
ciiconfservicehost |
Configuration Service hostname that should be resolved either by /etc/hosts file or the local DNS server. |
ciiarchivehost |
Engineering Archive hostname that should be resolved either by /etc/hosts file or the local DNS server |
References
Cosylab, ELT CII Configuration user manual, CSL-DOC-19-173189, v1.7
Cosylab, Middleware Abstraction Layer design document, CSL-DOC-17-147260 v 1.6
Elasticsearch website. https://www.elastic.co/
Cosylab, ELT CII – ICD Generation, User’s Manual, CSL-MAN-19-170402, v1.4
Cosylab, CII Service Management Interface, CSL-DOC-18-163377, v1.2
Cosylab, ELT CII Online Database user manual, CSL-DOC-19-176283, v1.3
Cosylab, ELT CII Log user manual, CSL-DOC-20-181435, v1.3
Telemetry examples project: https://svnhq8.hq.eso.org/p8/trunk/CONTROL-SYSTEMS/CentralControlSystem/CII/CODE/telemetry/telemetry-examples/
11.1. Overview¶
This document is a user manual for usage of the Telemetry Service system. It explains how to use the Telemetry Archiver API, how to use the CLI tools, and how to configure the Telemetry Archiver.
All examples in this manual will be also presented in the telemetry-examples module.
11.2. Introduction¶
The purpose of the CII Telemetry Service is archiving the periodic, event-based and ad-hoc data that will be used for calculation of statistics, and the long-term trends and performance of the ELT telescope.
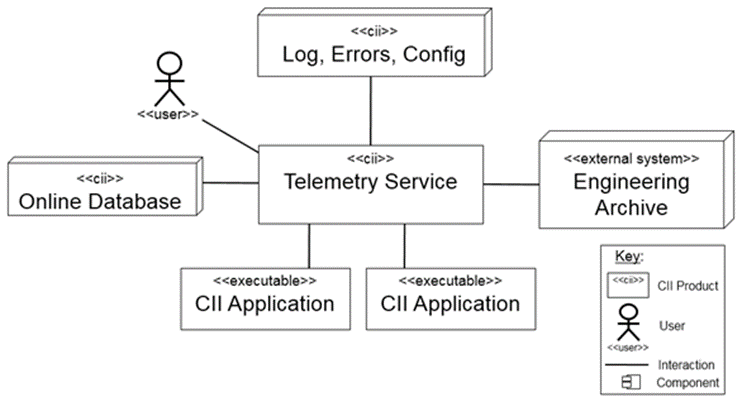
Figure 2‑1: Telemetry Service API interactions
CII Telemetry Service is a central archiving service of the CII infrastructure. It is reliant on the other CII services:
CII Online Database (OLDB) – the main source of data for archiving.
CII Configuration Service (Config) – storing and retrieving data capture configurations.
CII Log Service (Log) – used for storing Telemetry Service logs.
CII Errors Service (Errors) – used for reporting Telemetry Service errors.
The data captured by the CII Telemetry service is stored into the Engineering Archive (EA).
The CII Telemetry Service consists of multiple CII Telemetry Archivers that are responsible for archiving the incoming telemetry data. The Telemetry Archiver is split into two parts:
OLDB Subscription: this part of the archiver subscribes to data point changes that are coming from the online database and archives them accordingly to the specified values in the data capture configurations. It also handles periodic archiving of the data point values according to the data capture configuration.
Telemetry Client API: this part of the archiver handles communication between the service and CII Applications. The Client API is split into two endpoints:
Management endpoint – management of archiver (stop archiver, restart archiver, refresh archiver’s configuration) and archiver statistics (number of data points that are being archived, data archive rate)
Archive API endpoint – API used for storing ad-hoc data, querying, and downloading data from the Engineering Archive.
A high-level overview of a single CII Telemetry Archiver can be seen in Figure 2‑2.
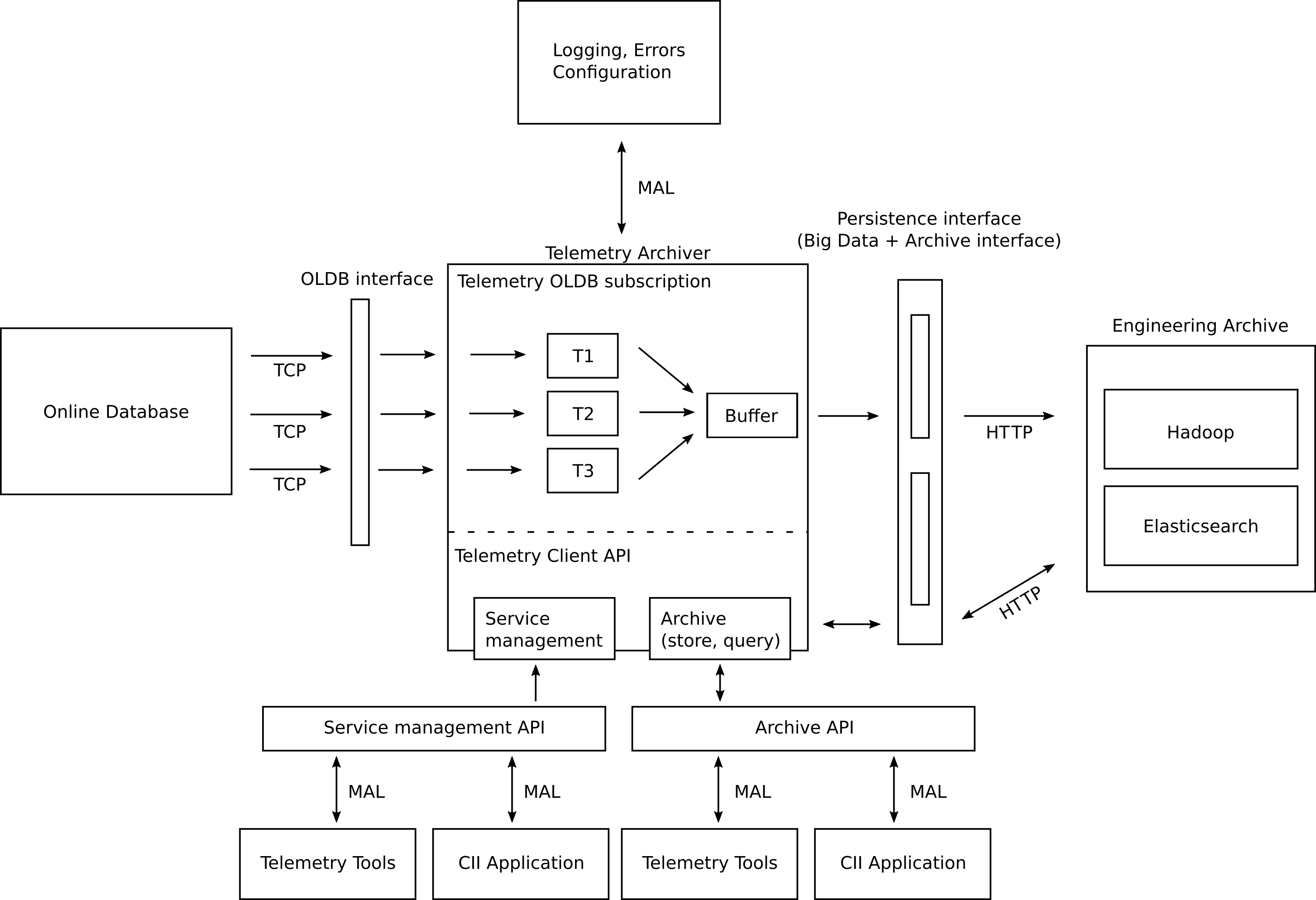
Figure 2‑2: High-level overview of one Telemetry Archiver
The CII Telemetry Archiver accesses the CII Configuration service to retrieve its configuration. This configuration is used when the CII Telemetry Archiver receives data points to determine which should be archived and which should be discarded. When a data point that should be archived is received, it is stored in the Engineering Archive.
The Engineering Archive consists of two parts:
Data Storage, which is used to archive smaller data (up to 2 GB); and
Big Data Storage, which is used to archive large data.
11.2.1. Telemetry OLDB Subscription¶
CII Telemetry Archiver subscribes to OLDB data points via OLDB client and archives the data point values according to the data capture configurations that are stored in configuration service. Each data capture configuration is used to provide archiving options for one data point. It is possible to define multiple data capture rules for the same data point URI on the same CII Telemetry Archiver – e.g. data point could be archived on both value change and quality flag change on the same Telemetry Archiver.
The changes of the data capture configurations are only propagated when the end-user calls the refreshConfiguration method on the Service Management API (see section 5.4). This will reload the specified configuration (or all configurations) without interrupting the ongoing archiving tasks except as required by the modified configuration. The configuration service will not be continuously polled for data capture configuration changes. When the Telemetry Archiver is started (initialized), the data capture configurations are downloaded via CII config client from the location specified in serviceRange. The Telemetry OLDB Subscription subscribes to data point changes via OLDB client. Internally the OLDB client maintains a pool of data point subscriptions.
When the Telemetry Archiver starts up, the data point values (CiiOldbDpValue) of the subscribed data points (as defined in data capture configurations) are downloaded from OLDB and stored in memory. Every time the data point value of the subscribed data point changes, they are checked against the data capture configurations to determine if the data point is suitable for archiving.
The subscribed data point will be archived depending on the following cases:
Value change: if the data point value changed and if the difference between the old and new data point value has changed for more than the specified delta value and if duration since the last archive is bigger than the minimum interval duration (set in data capture configuration) the data point will be archived.
Metadata change: if the data capture configuration is capturing based on the metadata change, the data point value will be archived whenever the metadata has changed
Quality change: if the data capture configuration is capturing based on the quality change and the data point quality flag has changed, the data point value will be archived.
Maximum interval: the purpose of the maximum interval is to archive the data point value in the absence of a data point value change event. If the maximum interval is set, a periodic task will be submitted to Telemetry Archiver’s scheduled executor that will try to archive the last data point value according to the specified period. Timestamp since the last archive event for the given data capture configuration will be stored in the memory of the archiving worker.
Minimum interval: the purpose of the minimum interval is to not archive too many data point value changes in a short timeframe. If the minimum interval is set and the duration between now and time, since the last value was archived, is bigger than the minimum interval duration, the data point value will be archived
It is possible to combine the above rules to make more fine-grained archiving behavior. For example, one can create two data capture configurations:
Data capture configuration with value archiving behavior and maximum time interval set to 10 seconds.
Data capture configuration with quality archiving behavior.
In such a case, the data point will be archived whenever the quality flag of the data point has changed or whenever the value has changed or every 10 seconds if the value was not archived in the last 10 seconds.
If the data point is valid for archiving according to the rules described above, the archiving worker thread will transform a data point configuration into a data packet described and insert it into the archiving buffer. This operation preserves the data of the data point (such as quality flags and source timestamps). If no data point source timestamp exists, a current wall clock time is set with microsecond resolution. If no quality flag is associated with the data point data, an Unknown quality flag is assigned.
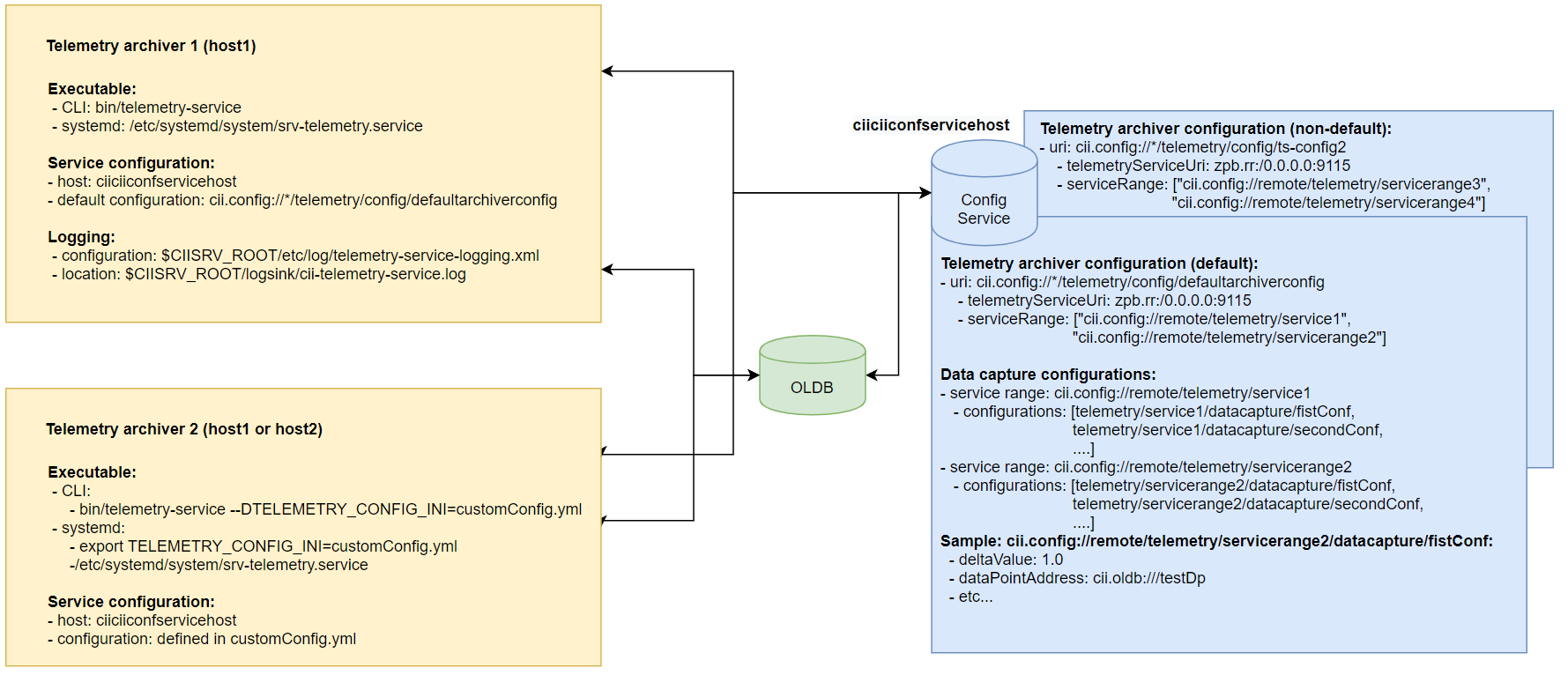
Figure 2‑3: Communication and configuration of Telemetry Archivers
11.2.1.1. Data Packet¶
The Data Packet is a data transfer object used for transferring data point values and ad-hoc data between Telemetry Archiver and its clients. The Telemetry Archiver clients could be written in one of the three supported languages (Java, C++, Python). For this reason, the data packet is generated with the MAL ICD [4]. The Data Packet contains the following fields:
Table 2‑1: Data packet fields description
Field |
Type |
Description |
Example |
|---|---|---|---|
Timestamp (automatically assigned) |
Double |
Representing the point in time when the data packet was archived (in UNIX time) |
1571914537.0 |
Data (required) |
String |
Data is stored as a valid JSON string |
{“temperature”: 30, “comment”: “ELT motor temperature”} |
Big Data File Reference (optional) |
String |
A reference / location of the big data file in the large storage service. The client has to store a large file into the large storage service before archiving the data packet |
11.2.2. Telemetry Client API¶
Telemetry Client API provides an interface for easier interaction with the archiving system. The API could be used by the command line tools and other CII Applications. Telemetry Client API consists of three parts:
Archive API – API used for storing, querying, and retrieving data from the Engineering Archive.
Service Management API – API used for managing Telemetry Archiver and providing important statistics about the Telemetry Archiver internals.
Telemetry Tools – CLI tools that make interaction with the Telemetry Archiver easier.
In order to provide an API to CII Applications that are written in different languages, a MAL ZPB service is used internally for handling the client requests. Client API service exposes two ICD interfaces:
- Archive API interface, the service is exposed on:zpb.rr://server:9115/telemetry/service/archive
- Service Management interface, the service is exposed on:zpb.rr://server:9115/telemetry/service/management
11.2.2.1. Archive API¶
Archive API shall be used by CLI tools and other CII Applications that need to interact with the Engineering Archive. Internally an Archive API is communicating with the archiving system through the Persistence Interface using the Telemetry Persistence Implementation.
Archive API will receive ad-hoc data from the clients in the form of data packets which will be stored irrespective of the age of the data into the EA.
Archiving API does not support storing data packets that contain large data blobs directly as that would result in a lot of unnecessary network traffic. The clients that will be using the Archiving API will have to first store the large files into the Large Storage Service and then store the data packet with the location reference of the blob into the Engineering Archive.
To make storing large data files to Large Storage Service easier, a library implementing the Large Storage Service interface is provided. The provided implementation will interact with the Hadoop storage system.
Archiving API handles any valid data package irrespective of the sampling frequency of the data. The actual speed of storing large big data blobs depends on the used hardware.
11.2.2.2. Service Management API¶
The CII Telemetry Archiver is a systemd service and should be started, stopped or restarted via systemd commands:
Start - start the service if it’s not already running
Restart - restart the Telemetry Archiver. All currently ongoing tasks will finish before the service will be restarted.
Stop - shutdown the Telemetry Archiver. All currently ongoing tasks will finish before the service is stopped
The instructions for manipulating the CII Telemetry Archiver with systemd, please check the CII Telemetry Transfer document.
The Service Management Client API exposes a RefreshConfiguration command which refreshes the specified data capture configurations from the configuration service without interrupting the ongoing archiving tasks.
As part of the Service Management API, metrics about the current state of the Telemetry Archiver are exposed via the JMX interface. For more information about the JMX interface see the design document for Service Management Interface [5]. For the Telemetry Archiver, the following metrics are exposed:
General metrics:
Current time.
Telemetry Archiver uptime.
Current Memory consumption.
Current CPU consumption.
The current number of archiving worker threads.
Engineering Archive health (periodic health checks reporting if the archiving system is still online).
Archiving worker threads:
The number of currently subscribed data points.
- The number of current data points that are being periodically
archived.
- The number of dropped data point values (archiving buffer was full
and a data point value was dropped).
Archiving buffer statistics:
Buffer fullness - the percentage of the buffer that is full.
Archiving throughput - number of archived data points in the last hour.
The number of errors that occurred while storing packets into the Engineering Archive in the last hour.
The total number of archived data points for the current day.
11.2.2.3. Telemetry CLI tools¶
The Telemetry CLI tools are separated into 2 modules:
- CLI Manager is a tool that allows a user to send the Telemetry
Archiver a notification to trigger a refresh of its configurations.
- CLI Archiver is a tool enabling users to store, download, and query
data packets from and to the Engineering Archive. The tool provides the user with three different commands: store, download, and query.
11.3. Prerequisites¶
This section describes the prerequisites for using the Telemetry Service, API, and applications. Note that the preparation of the environment (i.e. installation of required modules, configuration, running of services) is not in the scope of this document. Consult your administrator and the Telemetry Service TRD document for information on how to establish the environment for usage of the Telemetry Archiver, API, and applications. Before using the CII Telemetry make sure that telemetry configuration is initialized with telemetry-initEs command.
11.3.1. Services¶
11.3.1.1. Engineering Archive¶
The Engineering Archive (EA) stores the data that the Telemetry Archiver receives and decides to archive. The Engineering Archive is, in fact, a set of services. The EA has been initially designed to use Persistence interface to access Elasticsearch and Hadoop, but can be modified to use other forms of storage.
11.3.1.2. Configuration Service¶
The CII Telemetry Service uses CII Configuration Service to store its configuration. The Configuration service must be accessible for the Telemetry Archiver to successfully initialize.
11.3.1.3. OLDB Service¶
The Online Database service is the main source of data that provides data point updates which are checked against the capturing rules defined by the Telemetry Archiver (TA) and later archived in the archiving system. For testing purposes, the OLDB service could be replaced with the OLDB simulator that generates the data point value updates based on the capturing rules.
11.4. Data Capture Configuration¶
11.4.1. Create Data Capture Configuration¶
Before the Telemetry Archiver can archive data packets, it must be configured. The data capture configuration can be done using the Configuration GUI.
The following steps are necessary for configuration:
In the GUI click on Options and tick the Write enabled checkbox.
In the Target Config tab click on the Add button.
- The dialog shown in Figure 4‑1 will open. In this dialog the new configuration can be specified.
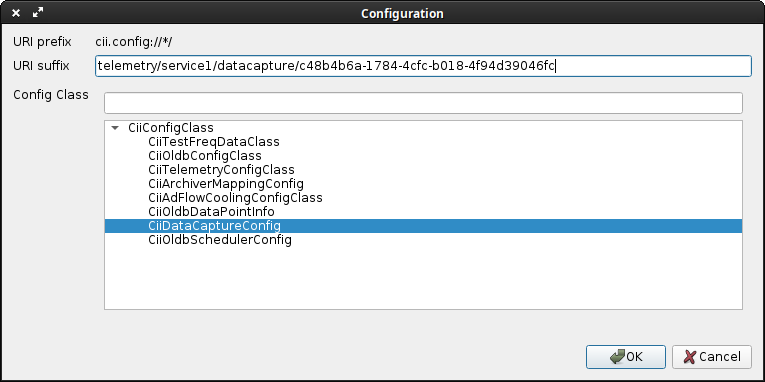
Figure 4‑1: Creation of new configuration
Specify the following:
URI suffix: The suffix needs to follow the following format: <SERVICE_RANGE**>**/datacapture/<UUID>. The first part needs to be the range under which the Telemetry Archiver is running (e.g. telemetry/service1 in the example). The second part needs to be a unique ID. A tool such as uuidgen canbe used to generate this UID.
Config Class: Select CiiDataCaptureConfig.
Click Ok. The data capture configuration should now be stored on the configuration service.
Edit the created data capture configuration fields by following the steps in the next section 4.2.
11.4.2. Edit Data Capture Configuration¶
Select the data capture configuration in the tree menu in the Target Config tab.
- Fill in the configuration parameters. The example in Figure 4‑2 shows a capture configuration that is storing value changes. The individual fields are listed and documented in Table 9.4.
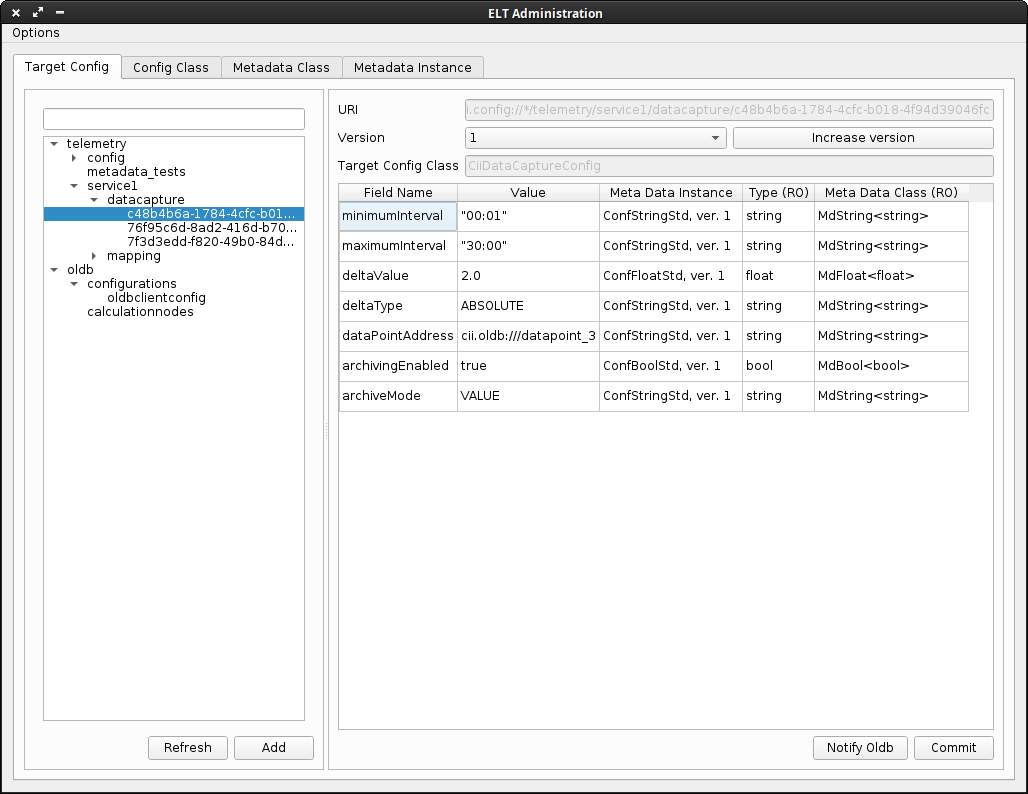
Figure 4‑2: Configuring a data capture configuration
Click on the Commit button.
Before the Telemetry Archiver can use the new configuration, Telemetry Archiver must be notified/refreshed about the updated configuration. For that, one can use the CLI tool described in section 6.1. The ID that the CLI tool expects for refreshing configuration is the URI of the configuration that is selected in the tree view on the left side of the GUI.
11.5. Telemetry Archiver API Usage¶
This section provides examples on how to use the Archive API and Service management API in an application. The Archive API provides users with the functionality to store, query, and download data as well as write, read, and delete big data that is saved in the Engineering Archive. The Service management API provides users with the functionality to refresh configurations.
All examples assume that CII Telemetry Archiver is running on localhost. This can be changed to the ciiarchivehost accordingly.
11.5.1. Basic Example¶
The following section demonstrates a basic step-by-step example workflow of using the Telemetry API.
The basic example starts by first configuring the data capture. Once the configuration service has processes and saved the new configuration, we refresh the configuration on the Telemetry Archiver. After a short while, the Telemetry Archiver will subscribe to the data point.
At this point, the Telemetry Archiver is archiving data points that match the provided configuration. The basic example continues by connecting to the Archive API and queries it to retrieve the archived data point IDs. The retrieved data point IDs are used to download the data packets. Upon downloading the packets, the data points data is displayed.
The APIs are documented in sections 5.2, 5.3, and 5.4.
Listing 5‑1 shows this basic example in Java (TelemetrySubscriptionExample.java). This can be done in CPP and Python as well.
Listing 5‑1: The basic example in Java
import java.net.URI;
import elt.mal.CiiFactory;
import elt.mal.rr.qos.QoS;
import elt.mal.rr.qos.ReplyTime;
import elt.mal.zpb.ZpbMal;
import elt.telemetry.archive.DataPacket;
import elt.telemetry.archive.TelemetryArchiveApiSync;
public class TelemetrySubscriptionExample {
public static void main(String[] args) throws Exception {
final URI telemetryServiceRange = URI.create("cii.config://*/telemetry/service1");
final URI uniqueCaptureLocation = URI
.create(String.format("%s/%s", telemetryServiceRange, UUID.randomUUID().toString()));
final URI oldbDatapointUri = URI.create("cii.oldb:///datapoint_1");
final URI telemetryManagementEndpoint = URI
.create("zpb.rr://localhost:9115/telemetry/service/management");
final URI telemetryArchiveEndpoint = URI
.create("zpb.rr://localhost:9115/telemetry/service/archive");
// start of the actual program
CiiConfigClient configClient = CiiConfigClient.getInstance();
configClient.setWriteEnabled(true);
DataCaptureConfiguration captureConfig = createCaptureConfig(oldbDatapointUri);
configClient.saveTargetConfig(uniqueCaptureLocation, captureConfig);
// wait for the configuration service to process and save request
Thread.sleep(2_000);
// refresh specific data capture configuration
refreshConfiguration(Arrays.asList(uniqueCaptureLocation.toString()),
telemetryManagementEndpoint);
// wait for the telemetry archiver to subscribe to data point (if it's not already)
Thread.sleep(2_000);
// query the stored data point from the archive
TelemetryArchiveApiSync archiveApi = connectToArchiveApi(telemetryArchiveEndpoint);
List<String> ids = archiveApi.queryData("data.uri:*datapoint_1*");
assert ids.size() > 0 : "At least one data point should be present";
// download queried ids
List<DataPacket> packets = archiveApi.downloadData(ids);
for (DataPacket packet : packets) {
// process packets
System.out.println(packet.getData());
}
// close resources
configClient.close();
archiveApi.close();
System.exit(0);
}
}
public static void refreshConfiguration(List<String> refreshIds, URI managementEndpoint) {
CiiFactory factory = null;
TelemetryServiceManagementSync client = null;
try {
factory = CiiFactory.getInstance();
factory.registerMal("zpb", new ZpbMal());
client = factory.getClient(managementEndpoint,
new QoS[]{new ReplyTime(10, TimeUnit.SECONDS)}, new Properties(),
TelemetryServiceManagementSync.class);
if (refreshIds.isEmpty()) {
client.refreshAllConfigurations();
} else {
client.refreshConfigurations(refreshIds);
}
} catch (CiiSerializableException e) {
String msg = String.format("Failed to refresh configurations %s", e.getCiiMessage());
System.out.println(msg);
} catch (Exception e) {
System.out.println("Failed to refresh configuration: " + e);
} finally {
if (client != null) {
client.close();
}
if (factory != null) {
factory.close();
}
}
}
public static TelemetryArchiveApiSync connectToArchiveApi(URI telemetryClientEndpoint) throws Exception {
CiiFactory factory = CiiFactory.getInstance();
factory.registerMal("zpb", new ZpbMal());
TelemetryArchiveApiSync client = factory.getClient(telemetryClientEndpoint,
new QoS[]{new ReplyTime(10, TimeUnit.SECONDS)}, new Properties(),
TelemetryArchiveApiSync.class);
CompletableFuture<Void> connectionFuture = client.asyncConnect();
connectionFuture.get(5, TimeUnit.SECONDS);
return client;
}
public static DataCaptureConfiguration createCaptureConfig(URI oldbDatapointUri)
throws CiiConfigDataLimitsException, CiiInvalidTypeException {
DataCaptureConfiguration captureConfig = new DataCaptureConfiguration(
"dataCaptureConfigTest", // name
"", // id is automatically set on store
oldbDatapointUri.toString(), // to which data point we want to subscribe to
1.0f, // delta value change
"ABSOLUTE", // delta type set to absolute changes
"VALUE", // archive mode set to value changes
"00:01", // minimum interval (at most once per second)
"10:00", // maximum interval (at least once every 10 minutes)
true // archiving enabled
);
return captureConfig;
}
11.5.2. Archive API: storing, querying and downloading data¶
A short description of the part of the Archive API used for storing, querying and downloading data can be found in A.1.
11.5.2.1. Imports/includes¶
Usage of the Telemetry Archive API requires the following imports to establish a MAL connection: CiiFactory, QoS, ReplyTime, and ZpbMal. The TelemetryArchiveApiSync interface defines the Telemetry Archive API methods.
An example of an application that uses the Telemetry Archive API can be found in the main method of the TelemetryArchiveAPIExample.java file in the telemetry-examples project (see [8]). Similar examples can be found in cpp/archive_api and python/archive_api folders.
For a list of necessary libraries in order to connect to the API make sure to check the wscript files in cpp, java and python folders of the telemetry-examples project.
11.5.2.1.1. Java¶
import java.net.URI;
import elt.mal.CiiFactory;
import elt.mal.rr.qos.QoS;
import elt.mal.rr.qos.ReplyTime;
import elt.mal.zpb.ZpbMal;
import elt.telemetry.archive.DataPacket;
import elt.telemetry.archive.TelemetryArchiveApiSync;
import com.fasterxml.jackson.databind.ObjectMapper;
11.5.2.1.2. CPP¶
#include <mal/Cii.hpp>
#include <mal/utility/LoadMal.hpp>
#include <mal/rr/qos/ReplyTime.hpp>
#include <CiiTelemetryArchiveApi.hpp>
11.5.2.1.3. Python¶
import elt.pymal as mal
from ModCiiTelemetryArchiveApi.Elt.Telemetry.Archive import DataPacket
from ModCiiTelemetryArchiveApi.Elt.Telemetry.Archive.TelemetryArchiveApi import TelemetryArchiveApiSync
11.5.2.2. Connection to Telemetry Archiver using MAL¶
To establish a MAL connection between our application and the Archive API endpoint, we first get an instance of CiiFactory, register a MAL connection on it and get a TelemetryArchiveApiSync client that connects to the URI zpb.rr://localhost:9115/telemetry/service/archive. We then wait until the connection is established.
Listing 5‑2, Listing 5‑3 and Listing 5‑4 demonstrate how to establish a MAL connection between an application and the Archive API endpoint.
11.5.2.2.1. Connection in Java¶
Listing 5‑2: Example of connection to the Telemetry Archiver using Java
CiiFactory factory = CiiFactory.getInstance();
Mal mal = new ZpbMal();
factory.registerMal("zpb", mal);
final URI endpointUri = URI.create("zpb.rr:// localhost:9115/telemetry/service/archive");
TelemetryArchiveApiSync client = factory.getClient(endpointUri,
new QoS[]{new ReplyTime(10, TimeUnit.SECONDS)}, new Properties(),
TelemetryArchiveApiSync.class);
CompletableFuture<Void> connectionFuture = client.asyncConnect();
connectionFuture.get(10, TimeUnit.SECONDS);
11.5.2.2.2. Connection in CPP¶
Listing 5‑3: Example of connection to the Telemetry Archiver using CPP
int status = 0;
const elt::mal::Uri archiveApiEndpoint("zpb.rr://localhost:9115/telemetry/service/archive");
// Register MAL and obtain client for archive API
auto malInstance = elt::mal::loadMal("zpb", {});
auto &factory = elt::mal::CiiFactory::getInstance();
factory.registerMal("zpb", malInstance);
auto client = factory.getClient<elt::telemetry::archive::TelemetryArchiveApiSync>
(archiveApiEndpoint,
{std::make_shared<elt::mal::rr::qos::ReplyTime>(std::chrono::seconds(10))}, {});
if (client == nullptr) {
std::cerr << "Could not obtain client for: " << archiveApiEndpoint.string() << std::endl;
status = 1;
} else {
auto connectionFuture = client->asyncConnect();
auto futureStatus = connectionFuture.wait_for(boost::chrono::seconds(10));
if (futureStatus != boost::future_status::ready) {
std::cerr << "Connection timeout to " << archiveApiEndpoint.string() << std::endl;
status = 2;
}
}
11.5.2.2.3. Connection in Python¶
Listing 5‑4: Example of connection to the Telemetry Archiver using Python
archive_api_endpoint = mal.Uri('zpb.rr://localhost:9115/telemetry/service/archive')
# Initialize Mal
factory = mal.CiiFactory.getInstance()
mal_instance = mal.loadMal('zpb', {})
if mal_instance is None:
raise RuntimeError('Could not load zpb mal')
factory.registerMal('zpb', mal_instance)
qos = [mal.rr.qos.ReplyTime(datetime.timedelta(seconds=10))]
# Obtain client and connect to Telemety service
client = factory.getClient(archive_api_endpoint, TelemetryArchiveApiSync,
qos, {})
connection_future = client.asyncConnect()
if connection_future.wait_for(datetime.timedelta(seconds=10)) == mal.FutureStatus.TIMEOUT:
raise RuntimeError('Could not to connect to %s, timeout' % (archive_api_endpoint.string(),))
_ = connection_future.get()
11.5.2.3. Storing a data packet¶
The data packet should contain the following fields:
archived: timestamp when the data packet was archived
bigDataLocation: reference to the big data file stored in Hadoop. This is an optional field.
data field that contains:
timestamp: data point timestamp in microsecond resolution
uri: data point URI
value: data point value
quality: data point quality flag
metadataReference: data point metadata reference
When storing a data packet via the Archive API, the data point URI could be an arbitrary string and the URI protocol does not have to start with cii.oldb.
Here is an example of how the subscribed data point value update will be serialized in ElasticSearch (fields prefixed with _ are autogenerated ElasticSearch internal fields and are not fetched when retrieving data):
Listing 5‑5: Archived metadata
{"_id" : "5HEb9m8Ba7LLWT1elmN_","_source" : {"archived" : 1580382019114000,"data" : {"@type" : "MdOldbNumber","value" : 2.0,"comment" : "","checked" : false,"metadataInstanceVersion" : 1,"@name" : "telemetry_meta1","@genType" : "SINGLE","metadataInstance" : "telemetry_meta1"}}}Listing 5‑6: Archived data point value
{"_id" : "5XEb9m8Ba7LLWT1emGP8","_source" : {"archived" : 1580382019737000,"data" : {"uri" : "cii.oldb:///datapoint_1","metadataReference" : "5HEb9m8Ba7LLWT1elmN_","quality" : "OK","value" : 0.5,"timestamp" : 1580382018598000}"bigDataLocation" : "4a9a3810-1efb-4d39-b8fb-751f09c91ea8"}}
11.5.2.3.1. Java client¶
To store data, we first create a DataPacket object containing metadata. In the provided example, the static method TelemetryArchiveAPIExample.createTestMetadata serves this purpose. It first creates the data packet class and then sets its fields: a timestamp is applied, the location of the data in the big data database of the Engineering Archive is specified and the data is added in JSON format.
The following sample code is an excerpt from the code file named TelemetryArchiveAPIExample.java, stored in the java/sample-app folder.
Listing 5‑7: Example of data packet metadata creation in Java
public static DataPacket createTestMetadata(Mal mal) {
DataPacket dataPacket = mal.createDataEntity(DataPacket.class);
dataPacket.setArchived(Instant.now().toEpochMilli());
dataPacket.setBigDataLocation("");
Map<String, Object> map = new HashMap<>();
map.put("@type", "MyOldbNumber");
map.put("value", 2.0);
map.put("comment", "");
map.put("checked", false);
map.put("metadataInstanceVersion", 1);
map.put("@name", "telemetry_meta1");
map.put("@genType", "SINGLE");
map.put("metadataInstance", "telemetry_meta1");
JSONObject json = new JSONObject(map);
dataPacket.setData(json.toString());
return dataPacket;
}
To store the created data packet, we call the storeData method of the TelemetryArchiveApi interface. It returns a string specifying the assigned ID of the data packet containing metadata.
Listing 5‑8: Example of storing of metadata data packet in Java
DataPacket metadata = TelemetryArchiveAPIExample.createTestMetadata(mal);
String metadataReference = client.storeData(metadata);
We proceed by creating another DataPacket object representing the data point value by passing the ID of the data packet containing the corresponding metadata (metadataReference) to the static method TelemetryArchiveAPIExample.createTestDataPointValue.
Listing 5‑9: Example of creating a data packet in Java
public static DataPacket createTestDataPointValue(Mal mal, String metadataReference) {
DataPacket dataPacket = mal.createDataEntity(DataPacket.class);
dataPacket.setArchived(Instant.now().toEpochMilli());
dataPacket.setBigDataLocation("bigDataLocation");
Map<String, Object> map = new HashMap<>();
map.put("uri", "cii.client:///datapoint_1");
map.put("metadataReference", metadataReference);
map.put("quality", "OK");
map.put("value", 0.5);
map.put("timestamp", Instant.now().toEpochMilli() - 10_000);
JSONObject json = new JSONObject(map);
dataPacket.setData(json.toString());
return dataPacket;
}
To store the created data packet, we call the storeData method of the TelemetryArchiveApi interface. It returns a string specifying the assigned ID of the data packet in the Engineering Archive.
Listing 5‑10: Example of storing of data packet in Java
DataPacket dataPointValue =
TelemetryArchiveAPIExample.createTestDataPointValue(mal, metadataReference);
String id = client.storeData(dataPointValue);
11.5.2.3.2. CPP client¶
The following listings contain a sample CPP client that stores a datapacket. The sample code is an excerpt from the code file named app.cpp stored in the cpp/archive-api folder. The code follows the same flow as the Java code.
First, a metadata DataPacket is created.
Listing 5‑11: Example of data packet metadata creation in CPP
std::shared_ptr<elt::telemetry::archive::DataPacket> createTestMetadata(
std::unique_ptr<elt::telemetry::archive::TelemetryArchiveApiSync> &client) {
auto malInstance = client->getMal();
auto dataPacket = malInstance->createDataEntity<elt::telemetry::archive::DataPacket>();
auto timestamp = timestampMillis();
dataPacket->setArchived(timestamp);
dataPacket->setBigDataLocation("");
boost::property_tree::ptree tree;
tree.put("@type", "MyOldbNumber");
tree.put("value", 2.0);
tree.put("comment", "");
tree.put("checked", false);
tree.put("metadataInstanceVersion", 1);
tree.put("@name", "telemetry_meta1");
tree.put("@genType", "SINGLE");
tree.put("metadataInstance", "telemetry_meta1");
std::stringstream data;
boost::property_tree::json_parser::write_json(data, tree);
dataPacket->setData(data.str());
return dataPacket;
}
To store the data packet, we call the storeData method of the client.
Listing 5‑12: Example of storing of metadata data packet in CPP
auto metadata = createTestMetadata(client);
auto metadataReference = client->storeData(metadata);
We proceed by creating another DataPacket object representing the data point value.
Listing 5‑13: Example of creating a data packet in CPP
std::shared_ptr<elt::telemetry::archive::DataPacket> createTestDatapointValue(
std::unique_ptr<elt::telemetry::archive::TelemetryArchiveApiSync> &client,
const std::string &metadataReference) {
auto malInstance = client->getMal();
auto dataPacket = malInstance->createDataEntity<elt::telemetry::archive::DataPacket>();
auto timestamp = timestampMillis();
dataPacket->setArchived(timestamp);
dataPacket->setBigDataLocation("bigDataLocation");
boost::property_tree::ptree tree;
tree.put("uri", "cii.client:///datapoint_1");
tree.put("metadataReference", metadataReference);
tree.put("quality", "OK");
tree.put("value", 9.5);
tree.put("timestamp", timestamp - 10000.0);
std::stringstream data;
boost::property_tree::json_parser::write_json(data, tree);
dataPacket->setData(data.str());
return dataPacket;
}
To store the data packet, we call the storeData method of the client.
Listing 5‑14: Example of storing of the data packet in CPP
auto datapoint = createTestDatapointValue(client, metadataRef);
auto dataReference = client->storeData(datapoint);
11.5.2.3.3. Python client¶
The following listings contain a sample Python client that stores a data packet. The sample code is an excerpt from the code file named cii-telemetry-examples-archive-py.py stored in the python/archive_api folder. The code follows the same flow as the Java code.
First, a metadata DataPacket is created.
Listing 5‑15: Example of data packet metadata creation in Python
def create_test_metadata(client):
mal_instance = client.getMal()
data_packet = mal_instance.createDataEntity(DataPacket)
data_packet.setArchived(datetime.datetime.now().timestamp() * 1000.0)
data_packet.setBigDataLocation('')
data = {'@type': 'MyOldbNumber',
'value': 2.0,
'comment': '',
'checked': False,
'metadataInstanceVersion': 1,
'@name': 'telemetry_meta1',
'@genType': 'SINGLE',
'metadataInstance': 'telemetry_meta1'}
data_packet.setData(json.dumps(data))
return data_packet
To store the data packet, we call the storeData method of the client.
Listing 5‑16: Example of storing of metadata data packet in Python
metadata = create_test_metadata(client)
metadata_reference = client.storeData(metadata)
We proceed by creating another DataPacket object representing the data point value.
Listing 5‑17: Example of creating a data packet in Python
def create_test_datapoint_value(client, metadata_reference):
mal_instance = client.getMal()
# timestamp must be in millis
timestamp = datetime.datetime.now().timestamp() * 1000.0
data_packet = mal_instance.createDataEntity(DataPacket)
data_packet.setArchived(timestamp)
data_packet.setBigDataLocation('bigDataLocation')
data = {'uri': 'cii.client:///datapoint_1',
'metadataReference': metadata_reference, # WATCH OUT
'quality': 'OK',
'value': 0.5,
'timestamp': timestamp - 10000.0}
data_packet.setData(json.dumps(data))
return data_packet
To store the data packet, we call the storeData method of the client.
Listing 5‑18: Example of storing of data packet in Python
datapoint_value = create_test_datapoint_value(client, metadata_reference)
packet_id = client.storeData(datapoint_value)
11.5.2.4. Storing a list of data packets¶
To store a list of data packets, we first create a list of DataPacket objects representing data point values. Then we call the storeDataList method of the TelemetryArchiveApi interface. It returns a list of strings specifying the assigned IDs of the data packets in the Engineering Archive.
Listing 5‑19, Listing 5‑20 and Listing 5‑21 contain a simple client that stores a list of data packets in the Java, CPP and Python programming languages respectively.
11.5.2.4.1. Java client¶
Listing 5‑19: Example of storing a list of data packets in Java
List<DataPacket> dataPackets = new ArrayList<>();
metadata = TelemetryArchiveAPIExample.createTestMetadata(mal);
metadataReference = client.storeData(metadata);
for (int i = 0; i < 2; i++) {
dataPointValue = TelemetryArchiveAPIExample.createTestDataPointValue(metadataReference);
dataPackets.add(dataPointValue);
}
List<String> ids = client.storeDataList(dataPackets);
11.5.2.4.2. CPP client¶
Listing 5‑20: Example of storing a list of data packets in CPP
std::vector<std::shared_ptr<elt::telemetry::archive::DataPacket>> dataPackets;
auto metadataInstance = createTestMetadata(client);
auto metadataRef = client->storeData(metadataInstance);
for (std::size_t i = 0; i < 2; i++) {
auto datapoint = createTestDatapointValue(client, metadataRef);
dataPackets.push_back(datapoint);
}
auto ids = client->storeDataList(dataPackets);
11.5.2.4.3. Python Client¶
Listing 5‑21: Example of storing a list of data packets in Python
data_packets = []
metadata = create_test_metadata(client)
metadata_reference = client.storeData(metadata)
for i in range(2):
datapoint_value = create_test_datapoint_value(client, metadata_reference)
data_packets.append(datapoint_value)
ids = client.storeDataList(data_packets)
11.5.2.5. Querying data packets¶
To query data packets in the Engineering Archive we call the queryData method of the TelemetryArchiveApi interface. It takes a string representing an ES Query DSL [3] query and returns a list of strings specifying the assigned IDs of the data packets in the Engineering Archive. In the provided example, we query all data packets that have the data.metadataReference field set to the ID of the data packet containing metadata that was stored last. When querying the EA using the ES Query DSL, the current limitation is that it currently does not support sorting the results.
Note: When the Elasticsearch is used as the Engineering Archive, some time needs to elapse between storing the data and querying it. This time can be up to 1 second depending on the settings of the Elasticsearch.
Listing 5‑22, Listing 5‑23 and Listing 5‑24 contain a sample Java client that queries the Archive API for a data packet.
11.5.2.5.1. Java client¶
Listing 5‑22: Example of querying data packets in Java
List<String> queriedIDs = client.queryData("data.metadataReference:" + metadataReference);
11.5.2.5.2. CPP client¶
Listing 5‑23: Example of querying data packets in CPP
std::stringstream query;
query << "data.metadataReference:" << metadataReference;
auto queriedIds = client->queryData(query.str());
11.5.2.5.3. Python client¶
Listing 5‑24: Example of querying data packets in Python
queried_ids = client.queryData("data.metadataReference:%s" % (metadata_reference,))
If the search query contains Elasticsearch reserved characters such as + - = && || > < ! ( ) { } [ ] ^ ” ~ * ? : \ /., they have to be escaped e.g: . Additional resources on Elasticsearch queries: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
11.5.2.5.4. Additional Query Examples¶
Querrying data for a specific data point in a specified time interval (please note the quotes around the data point URI). When querying for subscribed URIs the URI protocol should be set to cii.oldb. When querying for data stored via Archiver API, the client might have used a different protocol:
data.uri:”cii.oldb:///trk/ctrl/my_data_point” AND data.timestamp:(>= 1593786692807000 AND <= 1593786892807000)
Searching for data point with an exact data point value
data.uri:”cii.oldb:///trk/ctrl/my_data_point” AND data.value:0.0
Searching for all data points with a quality flag set to BAD in specified time interval
data.quality:”BAD” AND data.timestamp:(>= 1593786692807000 AND <= 1593786892807000)
Searching for all data points with a quality flag set to BAD or OK and data point value >= 1.0
(data.quality:”BAD” OR data.quality:”OK”) AND data.value:>=1.0
Searching for all data points uris that start with a specific path:
data.uri:”cii.oldb:///trk/ctrl/*”
The limitation in this case is that one cannot use wildcard in the middle of the path (such as: cii.oldb:///trk/c* as Elasticsearch splits the term into subpaths by splitting on the ‘/’ character).
11.5.2.6. Downloading data packets¶
To download data packets from the Engineering Archive we call the downloadData method of the TelemetryArchiveApi interface. It takes a list of strings representing the IDs of the data packets and returns a list of DataPacket objects. In the provided example, we download the data packets specified by the IDs that we acquired above.
There exists a separate API intended for downloading big data. The examples for big data can be found in section 5.3.
11.5.2.6.1. Java client¶
The following sample code demonstrates how to download data packets. The code is an excerpt from the code file named TelemetryArchiveAPIExample.java stored in the java/sample-app folder.
Listing 5‑25: Example of downloading data packets in Java
List<DataPacket> downloadedDataPackets = client.downloadData(queriedIDs);
downloadedDataPackets.forEach(TelemetryArchiveAPIExample::displayDataPacket);
The static method TelemetryArchiveAPIExample.displayDataPackets takes care of printing the downloaded data packets to the standard output.
Listing 5‑26: Example of displaying data packet data in Java
public static void displayDataPacket(DataPacket dataPacket) {
Map<String, Object> map = new HashMap<>();
map.put("archived", dataPacket.getArchived());
map.put("bigDataLocation", dataPacket.getBigDataLocation());
map.put("data", dataPacket.getData());
JSONObject json = new JSONObject(map);
System.out.println("\t" + json);
}
11.5.2.6.2. CPP client¶
In a similar manner to the example using Java, the packets can be downloaded in CPP as follows:
Listing 5‑27: Example of downloading data packets in CPP
auto downloadedDataPackets = client->downloadData(queriedIds);
for (auto &packet : downloadedDataPackets) {
displayDataPacket(packet);
}
The data packets can be displayed using the following function:
Listing 5‑28: Example of displaying data packet data in CPP
void displayDataPacket(std::shared_ptr<elt::telemetry::archive::DataPacket> &dataPacket) {
std::cout << "... downloaded data packet: " << std::endl;
std::cout << " archived: " << dataPacket->getArchived() << std::endl;
std::cout << " bigDataLocation: " << dataPacket->getBigDataLocation() << std::endl;
std::cout << " data: " << dataPacket->getData() << std::endl;
}
11.5.2.6.3. Python client¶
In a similar manner to the example using Java, the packets can be downloaded in Python as follows:
Listing 5‑29: Example of downloading data packets in Python
downloaded_data_packets = client.downloadData(queried_ids)
_ = [display_data_packet(data_packet) for data_packet in downloaded_data_packets]
The data packets can be displayed using the following function:
Listing 5‑30: Example of displaying data packet data in Python
def display_data_packet(data_packet):
print(' '*10, 'Data packet:')
print(' '*15, 'archived: ', data_packet.getArchived())
print(' '*15, 'bigDataLocation: ', data_packet.getBigDataLocation())
print(' '*15, 'data: ', data_packet.getData())
print()
11.5.2.7. Data packet deserialization¶
The following examples are presenting one way of deserializing data packet data field that contains the serialized OLDB data point.
11.5.2.7.1. Deserializing in Java¶
First, we have to define the deserialization structure (getters and setters are omitted for clarity):
static class ExampleDataPoint {
private URI uri;
private String metadataReference;
private String quality;
private double value;
private double timestamp;
}
Once we have the structure defined, we can deserialize the data packet:
Listing 5‑31: Example of deserializing data packet containing data point in Java
ObjectMapper mapper = new ObjectMapper();double archived = packet.getArchived();String bigDataLocation = packet.getBigDataLocation();
ExampleDataPoint dataPoint = mapper.readValue(packet.getData(), ExampleDataPoint.class)
11.5.2.7.2. Deserializing in CPP¶
First, we have to define the deserialization structure:
// structure that was stored in the data field
struct ExampleDataPoint {
std::string uri;
std::string metadataReference;
std::string quality;
double value;
double timestamp;
// Serialize itself to json string
std::string serialize() const {
boost::property_tree::ptree tree;
tree.put("uri", uri);
tree.put("metadataReference", metadataReference);
tree.put("quality", quality);
tree.put("value", value);
tree.put("timestamp", timestamp);
std::stringstream data;
boost::property_tree::json_parser::write_json(data, tree);
return data.str();
}
// Method to construct ExampleDataPoint from json string
static ExampleDataPoint deserialize(const std::string &json) {
boost::property_tree::ptree tree;
// Parse json and store its contents in the property tree
std::istringstream stream(json);
boost::property_tree::json_parser::read_json(stream, tree);
// Move the values from the tree into new ExampleDataPoint instance
ExampleDataPoint newInstance;
newInstance.uri = tree.get<std::string>("uri");
newInstance.metadataReference = tree.get<std::string>("metadataReference");
newInstance.quality = tree.get<std::string>("quality");
newInstance.value = tree.get("value", 0.0);
newInstance.timestamp = tree.get("timestamp", 0.0);
return newInstance;
}
}
Once we have the deserialization structure defined, we can deserialize the data field:
Listing 5‑32: Example of deserializing data packet containing data point in CPP
// deserialize the downloaded data packet
auto archived = packet->getArchived();
auto bigDataLocation = packet->getBigDataLocation();
ExampleDataPoint dataPoint = ExampleDataPoint::deserialize(packet->getData());
11.5.2.7.3. Deserializing in Python¶
Listing 5‑33: Example of deserializing data packet containing data point in Python
archived = data_packet.getArchived()
bigDataLocation = data_packet.getBigDataLocation()
data = json.loads(data_packet.getData())
for key, value in data.items():
print(key, '=', value)
11.5.2.8. Closing the MAL connection¶
Once we are finished storing, querying, and downloading data packets, we should close the MAL and CII Config client connection by calling the close method.
11.5.2.8.1. Closing the connection in Java¶
The close method needs to be called on both on the TelemetryArchiveAPISync object client as well as the CiiFactory object factory.
client.close();
factory.close();
Additionally, both objects are also auto-closeable, so they can be used in try-with-resources statements if that is practical for your application.
11.5.2.8.2. Closing the connection in CPP¶
In CPP the connections can be closed as follows:
client->close();
11.5.2.8.3. Closing the connection in Python¶
In Python the connections can be closed as follows:
client.close()
11.5.3. Archive API: Big Data Storage¶
Normally the Engineering Archive is agnostic of the underlying databases used for storage. However, to have higher performance, the Hadoop storage must be accessed directly when working with big data. The provided example uses an agnostic Big Data interface, but a specific implementation of that interface for Hadoop.
An example of an application that uses Big Data Storage library can be found in the telemetry-examples project. The examples project shows the usage of the Big Data Storage in the:
HadoopStorageExample.java file in the java/sample-app directory for Java,
app.cpp file in the cpp/storage directory for CPP, and the
cii-telemetry-examples-storage-py.py file in the python/storage directory for Python.
The examples can also be found in Appendix D.
A short description of the part of the Archive API used for writing, reading and deleting big data can be found in Appendix A.2.
11.5.3.1. Imports/Includes¶
Usage of the HadoopStorage library requires importing the Hadoop Storage class that implements the methods of the BigDataStorage interface.
11.5.3.1.1. Java¶
import java.net.URI;
import elt.storage.HadoopStorage;
import elt.storage.BigDataStorage;
11.5.3.1.2. CPP¶
#include <ciiHadoopStorage.hpp>
#include <ciiException.hpp>
11.5.3.1.3. Python¶
import elt.storage
11.5.3.2. Creating the client instance¶
First, we need to create an instance of the Hadoop Storage class by providing the URI of the Hadoop database of the Engineering Archive.
11.5.3.2.1. Java example¶
The following listing shows how to create an instance of the Big Data Storage in Java. The sample code is an excerpt from the code file named TelemetryArchiveAPIExample.java stored in the java/sample-app folder.
Listing 5‑34: Example of Big Data Storage client creation in Java
final BigDataStorage hadoopStorage =
new HadoopStorage(new URI("http://ciihdfshost:9870"), "/esoLs");
// contains path to the archive
final URI uri = new URI("cii.config://*/archive");
11.5.3.2.2. CPP example¶
The following listing shows how to create an instance of the Big Data Storage in CPP. The sample code is an excerpt from the code file named app.cpp stored in the cpp/storage folder. The code follows the same flow as the Java code.
Listing 5‑35: Example of Big Data Storage client creation in CPP
const elt::mal::Uri hadoopLocation("http://ciihdfshost:9870");
const std::string hadoopEndpoint("/esoSample");
elt::storage::CiiHadoopStorage storage(hadoopLocation, hadoopEndpoint);
11.5.3.2.3. Python example¶
The following listing shows how to create an instance of the Big Data Storage in Python. The sample code is an excerpt from the code file named cii-telemetry-examples-storage-py.py stored in the python/storage folder. The code follows the same flow as the Java code.
Listing 5‑36: Example of Big Data Storage client creation in Python
hadoop_location = 'http://ciihdfshost:9870'
hadoop_endpoint = 'esoSample'
storage = elt.storage.CiiHadoopStorage(hadoop_location, hadoop_endpoint)
11.5.3.3. Writing data¶
To write data to the big data database of the Engineering Archive we call the write method of the HadoopStorage class. It takes the big data archive URI and the data as parameters. Once the big data file is stored, the write method returns the automatically generated UUID file name.
If one would like to store the big data file reference into the Engineering Archive, one has to create the data packet (see section 5.2.3), set created big data file reference into the bigDataLocation data packet field and store the data packet into the Engineering Archive as described in section 5.2.3.
11.5.3.3.1. Java example¶
The following listing shows how to write data into the Big Data Storage in Java. The sample code is an excerpt from the code file named TelemetryArchiveAPIExample.java stored in the java/sample-app folder.
Listing 5‑37: Example of writing data to the Big Data Storage in Java
byte[] data = "data".getBytes();
String filename = hadoopStorage.write(uri, data);
11.5.3.3.2. CPP example¶
The following listing shows how to write data into the Big Data Storage in CPP. The sample code is an excerpt from the code file named app.cpp stored in the cpp/storage folder. The code follows the same flow as the Java code.
Listing 5‑38: Example of writing data to the Big Data Storage in CPP
const std::string remoteDirectory = "archive";
const std::string remoteFilename = "file.bin";
const std::string contentToStore(generateContent());
std::stringstream stream(contentToStore);
storage.write(remoteDirectory, remoteFilename, stream);
11.5.3.3.3. Python example¶
The following listing shows how to write data into the Big Data Storage in Python. The sample code is an excerpt from the code file named cii-telemetry-examples-storage-py.py stored in the python/storage folder. The code follows the same flow as the Java code.
Listing 5‑39: Example of writing data to the Big Data Storage in Python
remote_directory = 'archive'
remote_filename = 'file.bin'
content_to_store = generate_content()
stream = io.BytesIO(content_to_store.encode('utf-8'))
storage.write_from(stream, remote_directory, remote_filename)
11.5.3.4. Finding UUIDs of Archived Big Data Files¶
The big data file could be stored in the big data database either through OLDB-TA subscription mechanism or through the client code (see section 5.3.3). At some point after storing the data in the big data database, one might want to read that file for further analysis. In order to do that a UUID of the big data file must be known.
There are two ways to get the UUID:
When you store the big data file via Big Data Storage library, an UUID of the file is returned which you can use for further actions.
- When you are trying to retrieve a historic big data file (data that was archived some time ago), you have to find it by querying the Engineering Archive. Big data files are usually associated with other data points values/metadata, so you have to form your query according to the data point you are interested in; see section 5.2.5 on how to query the data. From the queried data you have to extract the big data file reference (UUID that you are looking for) and use that UUID for downloading or deleting big data file.Note on extracting: if you are using the Archiving API for querying, the API will return you all the data packets relevant to your query. To get the big data file UUIDs you have to iterate over received data packets and call getBigDataLocation() method.
11.5.3.5. Reading data¶
To read the data from the big data database of the Engineering Archive we call the read method of the HadoopStorage class. It takes the big data archive URI and the UUID file name as parameters, and returns data encoded into a sequence of bytes. In the provided example we read the data that we have previously written. If one would like to find the big data file UUID that was archived in the past, see section 5.3.4 on how to do that.
Listing 5‑40, Listing 5‑41, and Listing 5‑42 show examples of reading data from the Big Data Storage in Java, CPP, and Python respectively.
11.5.3.5.1. Java example¶
Listing 5‑40: Example of reading data from the Big Data Storage in Java
byte[] readDataBytes = hadoopStorage.read(uri, filename);
11.5.3.5.2. CPP example¶
Listing 5‑41: Example of reading data from the Big Data Storage in CPP
std::ostringstream ostream;
storage.read(remoteDirectory, remoteFilename, ostream);
11.5.3.5.3. Python example¶
Listing 5‑42: Example of reading data from the Big Data Storage in Python
ostream = io.BytesIO()
storage.read_into(ostream, remote_directory, remote_filename)
11.5.3.6. Deleting files¶
To delete a file from the big data database of the Engineering Archive we call the delete method of the HadoopStorage class. It takes the big data archive URI and the UUID file name as parameters. In the provided example we delete the file containing the data that we have previously written and read. If one would like to find the big data file UUID that was archived in the past, see section 5.3.4 on how to do that.
Listing 5‑43, Listing 5‑44 and Listing 5‑45 show examples of deleting data from the Big Data Storage in Java, CPP and Python respectively.
11.5.3.6.1. Java example¶
Listing 5‑43: Example of deleting files in the Big Data Storage in Java
hadoopStorage.delete(uri, filename);
11.5.3.6.2. CPP example¶
Listing 5‑44: Example of deleting files in the Big Data Storage in CPP
storage.remove(remoteDirectory, remoteFilename);
11.5.3.6.3. Python example¶
Listing 5‑45: Example of deleting files in the Big Data Storage in Python
storage.remove(remote_directory, remote_filename)
11.5.4. Telemetry Archiver Management API¶
After changing configurations on the Configuration service, the Service Management API must be used to refresh the configuration on the Telemetry Archiver.
A short description of the part of the Telemetry Archiver Management API can be found in A.3.
An example of an application that uses the Telemetry Archiver Management API to refresh a configuration can be found in the TelemetryServiceManagementAPIExample.java file in the telemetry-examples project.
11.5.4.1. Imports/includes¶
Usage of the Telemetry Archiver Management API requires the following imports to establish a MAL connection: CiiFactory, QoS, ReplyTime, and ZpbMal. The TelemetryServiceManagementSync interface defines Telemetry Archiver Management methods.
11.5.4.1.1. Java¶
import java.net.URI;
import elt.mal.CiiFactory;
import elt.mal.rr.qos.QoS;
import elt.mal.rr.qos.ReplyTime;
import elt.mal.zpb.ZpbMal;
import elt.telemetry.management.TelemetryServiceManagementSync;
11.5.4.1.2. CPP¶
#include <mal/Cii.hpp>
#include <mal/utility/LoadMal.hpp>
#include <mal/rr/qos/ReplyTime.hpp>
#include <CiiTelemetryManagement.hpp>
11.5.4.1.3. Python¶
import elt.pymal as mal
from ModCiiTelemetryManagement.Elt.Telemetry.Management.TelemetryServiceManagement import TelemetryServiceManagementSync
11.5.4.2. Connection to Telemetry Archiver using MAL and closing the connection¶
The connection can be created in the same way as described in section 5.2.2. The MAL connection needs to be closed as shown in section 5.2.8.
11.5.4.3. Refreshing configurations¶
To refresh selected configurations, we call the refreshConfigurations method of the TelemetryServiceManagement interface. It takes a list of strings specifying the URIs of the configurations that we want to refresh as parameter. The URIs of the relevant data capture configurations could be obtained:
Via configuration GUI, for more information see section 4.2.
When the data capture configuration is saved in the config-service: in order to save the data capture configuration in the config-service, the location/URI where the data capture configuration will be stored must be specified. In order to inform the Telemetry Archiver of the new/updated configuration one has to call refreshConfigurations method with the same URI.
Programmatically by querying the config-service for the relevant data capture configuration. An example of programmatic querying in Java for all data captures stored under Telemetry Archiver’s service range could be seen below. For more info on how to query the config-service in other languages, see [1].
CiiConfigClient configClient = CiiConfigClient.getInstance();
String archiverServiceRange = ElasticSearchUtilities.createElasticSearchId(
URI.create("cii.config://*/telemetry/service1/datacapture/”));
List<String> dataCaptureConfigIds =
configClient.remoteIndexSearch("configuration_instance",
String.format("id:%s*", archiverServiceRange));
// dataCaptureConfigIds could now be as an input for refreshConfigurations
// method
In order to refresh all the configurations, we call the refreshAllConfigurations method of the TelemetryServiceManagement interface.
Listing 5‑46, Listing 5‑47 and Listing 5‑48 show examples refreshing configurations in Java, CPP and Python respectively. Note that the example code assumes that a configuration with the URL “cii.config:///telemetry/service1/48fe831c-436a-401b-ab27-18ee401735af”* already exists.
11.5.4.3.1. Java example¶
Listing 5‑46: Example of refreshing configurations in Java
// refresh selected configurations
List<String> ids = new ArrayList<>();
ids.add("cii.config://*/telemetry/service1/48fe831c-436a-401b-ab27-18ee401735af");
client.refreshConfigurations(ids);
// refresh all configurations
client.refreshAllConfigurations();
11.5.4.3.2. CPP example¶
Listing 5‑47: Example of refreshing configurations in CPP
// Refresh selected configurations
std::vector<std::string> dataCaptureIds
{"cii.config://*/telemetry/service1/48fe831c-436a-401b-ab27-18ee401735af"};
client->refreshConfigurations(dataCaptureIds);
// Refresh all configurations
client->refreshAllConfigurations();
11.5.4.3.3. Python example¶
Listing 5‑48: Example of refreshing configurations in Python
# Refresh selected configurations
ids = ['cii.config://*/telemetry/service1/48fe831c-436a-401b-ab27-18ee401735af']
client.refreshConfigurations(ids)
# Refresh all configurations
client.refreshAllConfigurations()
11.6. Telemetry CLI tools¶
This section describes how to use Telemetry Archiver CLI tools. These command line tools simplify basic operations without needing to write custom applications for these tasks.
11.6.1. CLI Manager¶
CLI Manager allows a user to send the Telemetry Archiver a notification to trigger a refresh of its configurations.
The default syntax for the CLI Manager is:
telemetry-manager refresh [-c <config> <config>] [-h] [-s <service endpoint>]
The -h argument prints a help description to the standard output.
The refresh command options are:
-c,--configurations <config> <config> specifies list of configuration
ids, based on which telemetry
service configurations are
refreshed. If this option is
omitted, all configurations are
refreshed
-h,--help displays this help message
-s,--service <service endpoint> specifies custom service endpoint
of telemetry archiver for manager
to connect to.
Usage example
$ telemetry-manager refresh –c config_1 config_2
Here only specific configurations are refreshed (configurations with ids config_1 and config_2).
$ telemetry-manager refresh
Here all existing configurations are refreshed.
11.6.2. CLI Archiver¶
CLI Archiver is a tool enabling users to store, download, and query data packets from and to the Engineering Archive. The CLI Archiver is not optimized for speed and is meant to be used for one-time slow archive related tasks. A single instance of the telemetry-tool doesn’t support full required rate of telemetry service.
The telemetry-tool provides the user with three different commands: store, download, and query. All commands have specific options available, further specifying the behavior of the command. The help and service options can be used with all commands. The help option is used for display the help message. The service option enables the user to specify a custom address of the Telemetry Archiver.
The default syntax for CLI archiver is:
telemetry-tool [command] [-h | specific options] | [-h] [command]
The -h argument prints a help description to the standard output.
Each command has a list of options that can be used with it. All options can be viewed with the -h option.
11.6.2.1. Storing data packets¶
Storing of data packages is possible by using the store command. Additionally, by using different provided options the user can store different files (data packets containing metadata and/or big binary files), as well as specifying different service endpoints for the archiver to connect to (service endpoint option).
The Store command syntax is as follows:
telemetry-tool store [-b <file path> <file path>] -d <file path> <file path> | -h [-s <service endpoint>]
The Store command options are:
options:
-b,--bigdata <file path> <file path> specifies file path to
bigData binary file to be stored
-d,--data <file path> <file path> specifies file path that
contains data for creation of new
dataPacket
-h,--help displays help message
-s,--service <service endpoint> specifies custom service endpoint
of telemetry archiver to connect to.
Multiple data packets can be created and stored with a single store command. If multiple file paths are provided as parameters to the option. The bigdata option is optional, but can also specify multiple file paths. Additionally, specified big data file paths correspond to their respective data packets provided with the data option (this means, that not all data packets necessarily have to contain corresponding big data files attached to them and that both types of packets are paired based on the order they were passed as parameters: 1 data packet goes with 1 big data file, etc.).
The data file is meant to be any kind of JSON based file up to 2 GB in size. While the data file does not have to follow the data packet structure (any valid json will do), it is highly recommended that it follows it (the data packet structure), otherwise analyzing and operating on such highly dynamic data will be extremely problematic.
The bigdata file could be anything (text file, image, video, compiled program) and doesn’t have a file size limit.
11.6.2.1.1. Storing metadata¶
The example below shows how to store the data point metadata into the Engineering Archive:
$ telemetry-tool store -d metaFile1.json
mcx7jHQBRBKWEuv9m9Gc
The output from the telemetry tool represents the stored metadata data packet ID (mcx7jHQBRBKWEuv9m9Gc), which the user could use later on to download the archived metadata or reference the metadata when archiving data point values (see section 6.2.1.2). The metaFile1.json is following the structure of the CII Config metadata and it is displayed below:
Listing 6‑1: an example of metaFile1.json file
{
"@type": "MdOldbNumber",
"value": 2.0,
"comment": "",
"checked": false,
"metadataInstanceVersion": 1,
"@name": "telemetry_meta1",
"@genType": "SINGLE",
"metadataInstance": "telemetry_meta1"
}
11.6.2.1.2. Storing data point values¶
The data point values are stored via the following command:
$telemetry-tool store -d data/dpValue1.json data/dpValue2.json -b BigPicture.jpg
j_HWn3ABUTxPCroFrXwo n8yTjHQBRBKWEuv9ltGT
The dataPacket1.json and dataPacket2.json are files that should follow the structure below (the structure is not enforced and the end user can archive any valid JSON):
Listing 6‑2: structure of the dpValue1.json file
{
"uri": "cii.client:///my_datapoint_id_1",
"metadataReference": "mcx7jHQBRBKWEuv9m9Gc",
"quality": "OK",
"value": 0.5,
"timestamp": 1600084745793000
}
Before storing the data point value (e.g., dpValue1.json) into the Engineering Archive, make sure that the metadata in the metadataReference field is already present in the Engineering Archive. The metadata reference can be obtained by either searching in the Engineering Archive (see section 6.2.3) or storing the metadata first (see section 6.2.1.1) and then storing the data packet with the reference of the archived metadata.
If the -b (–bigdata) flag is present, the referenced big data file is stored to the Big Data Storage and its ID is stored to corresponding data packet’s bigDataLocation field. Big data files are paired with data packets in order they are provided. In the provided example above, the dpValue1.json data packet has a reference to big data file attached (reference to archived BigPicture.jpg), while the dpValue2.json data packet does not have a reference to big data file.
The telemetry tool returns the IDs of the archived data point data packets, which are used for downloading the archived data packets from the Engineering Archive (see section 6.2.2).
11.6.2.2. Downloading data packets¶
Data packets and their corresponding big data files can be retrieved from the Engineering Archive using the download command. Data packets can be either downloaded to local disk or displayed based on options provided.
The Download command syntax is as follows:
telemetry-tool download -h | -p <packet id> <packet id> [-o <file path>]
[-s <service endpoint>]
The Download command options are:
options:
-h,--help displays help message
-o,--output <folder path> specifies the path to folder where
data packets will be stored. If
this option is ommited, downloaded
packets data is displayed instead.
-p,--packets <packet id> <packet id> specifies list of packet IDs that
will be downloaded
-s,--service <service endpoint> specifies custom service endpoint
of telemetry archiver to connect
to.
Multiple packets can be displayed/downloaded using a single download command. The output option (-o,–output) controls if the data packets will be displayed or downloaded. This option is not required, so by default, the specified data packets will only be displayed to the user. If this option is present, packets will be stored inside the folder denoted by this option’s parameter, specifying the location on the local disk where the download folder will be created. If the data packet that should be downloaded contains the location (URI denoting the location in the EA) of the big data file, that file is also retrieved and stored in the same folder.
Below two examples show the usage of both modes (display and download) for the download command.
Usage example
Displaying data packet downloaded from the Engineering Archive:
$ telemetry-tool download –p j_HWn3ABUTxPCroFrXwo
{"archived":1.583229611294E15,
"data":"{\"key\":\"testValue1\"}",
"bigDataLocation":"cii.config:\/\/*\/archive\/0a383f2f-8b37-4e11-b6c5-1d798e278da0"}
Here the specified data packet is retrieved from the EA and its content is displayed. It is not stored on the local disk.
Usage example
Downloading a data packet from Engineering Archive to local disk:
$ telemetry-tool download –p j_HWn3ABUTxPCroFrXwo –o ~/downloadFolder
Here a new folder named downloadFolder is created inside the user’s home directory. A new file is created inside containing the information stored in the data field of the downloaded data packet. If the packet has a big data file location defined, another binary file will be created. The data packet ID also specifies the name of the newly created file, where the big data binary file additionally has .bin appended to the end.
11.6.2.3. Querying data packets¶
The user can search for specific data packets using the query command. The ES Query DSL [3] is used for querying, allowing the user to find packets matching certain criteria specified by the query request (e.g. all packets having certain field set to specified value). The result of the query command is a list of IDs representing data packets that match the sent query.
The Query command syntax is as follows:
telemetry-tool query -h | -r <request definition> [-s <service endpoint>]
The Query command options are:
options:
-h,--help displays help message
-r,--request <request definition> Elasticsearch query based on which
the returned packet IDs are selected
-s,--service <service endpoint> specifies a custom service endpoint of
the telemetry archiver to connect to.
When specifying options, either request option (-r,–request) or help options (-h,–help) must be provided. The example below displays the usage of the query command.
Usage example
$ telemetry-tool query -r "data.metadataInstance: telemetry* AND data.value: 2"
j_HWn3ABUTxPCroFrXwo jvHWn3ABUTxPCroFrXwo
Here query requests data packets where the data.value field equals 2 and data.metadataInstance matches all telemetry* entries. As a result, IDs of two data packets (j_HWn3ABUTxPCroFrXwo and jvHWn3ABUTxPCroFrXwo in the above example), that match the set query are returned.
11.7. Telemetry Subscription¶
This section describes how to correctly prepare a Telemetry Archiver (TA) for archiving data point changes that are published via OLDB subscription. Telemetry Archiver subscribes to the data point changes depending on the data capture configurations which are stored in the config-service.
Each data capture configuration represents a set of rules that determine whether or not a specific data point change should be captured. It is possible to define multiple data capture configurations for one data point in order to make a more fine-grained archiving behaviour.
Each Telemetry Archiver has its own specified range that defines the location in the Configuration service from which the data capture configurations are being downloaded from. An example on how this works is shown below:
Say we have a Telemetry Archiver (TA1) and we would like it to archive data point (DP1) value changes. In order to do that we have to:
Create a data capture configuration (CiiDataCaptureConfig) with desired archiving rules set (mentioned below in the examples section).
Store data capture configuration into config-service under Telemetry Archiver’s service range.
Reload the data capture configurations of TA1 by calling one of the refreshConfiguration methods on the TA1’s Service Management API that will seamlessly reload the in-memory capture configurations with the new ones coming from the config-service.
The data capture configuration fields are documented in Appendix B.
The data capture configurations could be saved/updated with both the config-client and config-gui. See provided manuals [1] on how to effectively use config-client or config-gui. An example written in the Java programming language is shown below (similarly one can do the same via C++ or Python):
Listing 7‑1: Example of creating and saving a data capture configuration
final URI serviceRange = URI.create("cii.config;//*/telemetry/service1");
final URI oldbDatapointUri = URI.create("cii.oldb:///datapoint_1");
DataCaptureConfiguration captureConfig = new DataCaptureConfiguration(
oldbDatapointUri, // oldb datapoint uri
1.0f, // delta value change
"ABSOLUTE", // delta type set to absolute changes
"VALUE", // archive mode set to value changes
"00:01", // minimum interval (at most once per second)
"10:00", // maximum interval (at least once every 10 minutes)
true // archiving enabled
);
// data capture configuration id should be unique
captureConfig.setId(UUID.randomUUID().toString());
// save data capture configuration to config-service
try {
CiiConfigClient client = CiiConfigClient.getInstance();
client.saveTargetConfig(serviceRange, captureConfig);
} catch (CiiSerializableException e) {
System.out.println("Error while storing data capture configuration: "
+ e.getCiiMessage());
}
11.7.1. Data Capture Configuration Examples¶
We assume the Telemetry Archiver (TA1) which will subscribe to data point (DP1) changes with a service range set to cii.config://*/telemetry/archiver1:
11.7.1.1. Archive data point on absolute value change or quality change¶
In this example we would like to archive data point (DP1) in the following situation:
Data point should be archived on absolute value change (+/- 2.0)
Data point should be archived at least once every 5 minutes
Data point should be archived at most every second
Data point should be archived if the quality flag has changed
We have to create 2 capture configurations:
Data capture (DC1) that will define the rules for archiving absolute value change. The data capture configuration should have the following fields set:
Field |
Value |
|---|---|
dataPointAddress |
cii.oldb:///datapoints/dp1 |
archiveMode |
VALUE |
deltaType |
ABSOLUTE |
deltaValue |
2.0 |
minimumInterval |
1 |
maximumInterval |
05:00 |
archivingEnabled |
true |
Data capture (DC2) that will define the rules for archiving quality change:
Field |
Value |
|---|---|
dataPointAddress |
cii.oldb:///datapoints/dp1 |
archiveMode |
QUALITY |
deltaType |
“” |
deltaValue |
0 |
minimumInterval |
0 (minimum interval when capturing quality changes is not used) |
maximumInterval |
0 (maximum interval for quality change can be set as well, but in this example this is already handled in the DC1 config example) |
archivingEnabled |
true |
11.7.1.2. Archive data point on relative value change or metadata change¶
We would like to archive the data point based on the following rules:
Data point should be archived if the value changes by 4% of the current value
Data point should be archived if the metadata has changed
Again, we create two data capture configurations:
Data capture configuration (DC1) that will define the rules for relative value change. The process is the same as in section 7.1.1, except the delta type field should be set to “RELATIVE”.
Field |
Value |
|---|---|
dataPointAddress |
cii.oldb:///datapoints/dp1 |
archiveMode |
VALUE |
deltaType |
RELATIVE |
deltaValue |
0.04 |
minimumInterval |
0 (all updates will be stored) |
maximumInterval |
0 (maximum interval is not set) |
archivingEnabled |
true |
Data capture configuration (DC2) that will define the rule for metadata change. The data capture configuration that handles metadata changes does not respect the set minimum and maximum interval and will archive the data point on every metadata change. It is expected that metadata will be rarely changed.
Field |
Value |
|---|---|
dataPointAddress |
cii.oldb:///datapoints/dp1 |
archiveMode |
METADATA |
deltaType |
“” (irrelevant for metadata change) |
deltaValue |
0 (irrelevant for metadata change) |
minimumInterval |
0 (minimum interval is not respected; metadata change is always archived) |
maximumInterval |
0 (maximum interval is not set) |
archivingEnabled |
true |
11.7.1.3. Stop archiving the data point¶
There are two option for TA1 to stop archiving changes of the specified data point (DP1):
Set the archivingEnabled field to false for all data capture configurations that are referencing a DP1 (via dataPointAddress field) and call one of the refreshConfiguration methods on the TA1’s Service Management API.
Delete the data capture configuration referencing a DP1 (via dataPointAddress field) from the configuration service and call one of the refreshConfiguration methods on the TA1’s Service Management API.
11.7.2. OLDB Simulation¶
For testing purposes of the Telemetry Archiver, it might be useful to simulate the data point value updates. This could be done by:
Using OLDB mock.
Using OLDB simulator.
11.7.2.1. OLDB Mock¶
For fine grained testing purposes, it might be useful to use your own OLDB mock service instead of the production OLDB service. Internally the Telemetry Archiver is using OLDB client, which subscribes to the OLDB service for data point value updates. Consult the 3.3.1 OLDB Client Configuration section of CII Online Database user manual [6], on how to configure the OLDB client to connect to your own OLDB mock service which you are going to use as part of the testing purposes.
11.7.2.2. OLDB Simulator¶
For performance testing purposes it might be useful to use the OLDB simulator which allows you to continuously simulate data point value updates depending on the data capture configurations that are stored in the CII Configuration Service. The OLDB data point value simulation works in the following fashion:
The user starts the Telemetry Archiver with the TA’s simulateCapture configuration field set to true.
The OLDB simulator that is started within the Telemetry Archiver downloads the data capture configurations from the CII Config Service from the serviceRange specified in the TA’s configuration.
The data point info is parsed from the downloaded data capture configurations. The URI from the data capture configuration defines the URI of the data point for which the updates will be simulated.
The OLDB simulator starts generating data point updates based on parsed data point info.
The OLDB simulator is currently supporting 2 archive modes from the data capture configuration:
Value change
Quality change
If the data capture configuration archiveMode is set to VALUE_CHANGE, the ABSOLUTE value of the data point will be continuously generated with the minimum interval based the data capture configuration deltaChange field (delta change represents the value change necessary for data point to be archived). This ensures that every generated data point value is suitable for archiving. The data point RELATIVE value updates are currently not supported by the simulator.
If the data capture configuration archiveMode is set to QUALITY_CHANGE, the quality flag of the data point will be flipped (from true to false and vice versa) with the minimum interval period as defined in the data capture configuration.
The URIs in the data capture configurations could be anything as long as they follow the OLDB URI convention (cii.oldb:///uri), however the OLDB simulator supports a special behavior in case the data point URI is one of the following:
Datapoint URI |
Behavior |
|---|---|
cii.oldb:///simulated_datapoint_1 |
generate data point updates based on the data capture configuration, without any side effects. This is the regular behaviour of the OLDB simulator. |
cii.oldb:///simulated_datapoint_2 |
generate data point updates based on the data capture configuration, but omit the data point timestamp field (timestamp field of the generated data point is null). |
cii.oldb:///simulated_datapoint_3 |
generate data point updates based on the data capture configuration, but omit the data point quality flag field (quality flag of the generated data point is null). |
11.8. Telemetry Archiver Deployment¶
Telemetry Archivers (TA) are designed to be horizontally scalable. In order to achieve this, they do not know about one another and the end user has to manually specify which TA will be archiving which data points under which data capture rules.
This data point archiving specification is done through the Telemetry Archiver’s configuration (see Appendix C). Every Telemetry Archiver has to have its own configuration file, because the Telemetry Archiver configurations have to differ in at least two configuration fields (both fields have to be unique when running two services on the same machine):
telemetryServiceURI: location that defines the network interface and port on which the TA will be bound to (e.g. zpb.rr://0.0.0.0:9115/).
serviceRange: location in configuration service where the specific Archiver’s data capture configurations are located (e.g: cii.config//*/telemetry1/archiver1/)
Each Telemetry Archiver contains its configuration stored in the CII Configuration Service. The configuration file itself could be deployed in either local or remote configuration service database. The location of the configuration file is determined by either command line flag or environment variable (TELEMETRY_CONFIG). The variable should be following the CII Configuration Service URI rules (cii.config//location/path/to/config).
The order of configuration file location is the following:
Command line flag (-DTELEMETRY_CONFIG)
Environment variable (TELEMETRY_CONFIG)
If none of the above is set, default configuration will be used (cii.config://*/telemetry/config/defaultArchiverConfig)
If the configuration is stored on remote Configuration service, a CONFIG_SERVICE_LOCATION variable has to be set as well (e.g: zpb.rr://hostname:port/).
The order of the Configuration service location flag is the following:
Command line flag (-DCONFIG_SERVICE_LOCATION)
Environment variable (CONFIG_SERVICE_LOCATION)
If none of the above is set, default Configuration service location will be used (zpb.rr://ciiconfservicehost:9116/)
If one would like to run multiple TAs on the same server (or virtual machine), one has to use command line flag (-DTELEMETRY_CONFIG) as otherwise two services will try to bind on the same port and only one will succeed.
Make sure that the serviceRange field in the TAs configuration is unique, otherwise different archivers will subscribe to the same data points with the same capturing rules and you will end up with duplicated data in the archive.
11.8.1. Example¶
Say we have our custom TA configuration located in the CII configuration service under the cii.config://*/telemetry/config/custom location.
Start TA with -DTELEMETRY_CONFIG=”cii.config://*/telemetry/config/custom/” command line flag.
Store data capture configurations in configuration service under location that is specified in the serviceRange (see also section 4). If serviceRange is specified as cii.config///telemetry/archiver1, the data capture configuration should be stored under cii.config///telemetry/archiver1/datacapture/<data capture UUID>
11.8.2. Systemd Deployment¶
If you are running multiple services via systemd, you have to deploy multiple systemd unit files that will start the Telemetry Archiver executables with different -DTELEMETRY_CONFIG flag set.
11.8.3. Scaling Telemetry Archiver¶
The actual load that one Telemetry Archiver can handle entirely depends on the hardware on which the TA is running and the desired performance needs (number of subscribed data points and their update frequency). The TA was designed in a way to support horizontal scaling, meaning if more throughput is necessary you can easily deploy more archivers.
For maximum performance of the TA it is recommended to deploy it on a different machine than the one where CII OLDB Service or Engineering Archive are deployed on. Nevertheless, if your desired performance needs are lower than one server can handle then you are free to run an entire infrastructure on one server.
The only way to get the actual performance numbers of one TA node is to run performance tests on the production hardware and measurements. This is usually done by slowly increasing the load of the TA and observing the metrics (CPU, RAM, JVM metrics and TA metrics through JMX). The following are some of the general problems and solutions that are likely to occur during performance measurements:
If archiving buffer starts filling up in the TA (check JMX metrics), that means you have to increase the performance of the Engineering Archive. Before you start tinkering with the Engineering Archive, you might want to try and increase or decrease the archiving buffer batch size through the TA’s configuration. It’s possible that decreasing or increasing the batch size might improve the archiving throughput. During the performance tests that we performed, the Engineering Archive was always a bottleneck.
If CPU is the bottleneck and fully utilized add more cores or share the load by moving some of the subscribed data points to another TA node. For maximum performance make sure the TA does not share CPU resources with another virtual machine that is running on the same server.
If RAM is the bottleneck, add more RAM or share the load with another TA. A rule of thumb is to size the heap in a way that after a garbage collection, cca. 30% of the heap is still occupied. You can try to modify the heap size via JVM flags (-Xmx, -Xms). For maximum performance ensure that the system is not swapping (on high performance servers swap is usually disabled).
If the network interface can’t handle the incoming data, then you have to act accordingly to your infrastructure capabilities.
Running the TA on a more recent JVM (11) might improve performance by 10-15%, due to the improvements made in G1GC garbage collector. If you notice long stop the world GC pauses, you can try tuning the GC via JVM flags. If long GC pauses are proven as problematic, you might want to try switching to one of the newer concurrent garbage collectors (Shenandoah, ZGC) that promise garbage collector pauses lower than 10ms.
To get a better feeling of what is really going on with the system, one might want to use the CLI tools that are usually installed on a Linux machine:
vmstat - reports information about processes, memory, paging, block IO, traps, disks and CPU activity.
iostat - reports Central Processing Unit (CPU) statistics and input/output statistics for devices, partitions and network filesystems (NFS).
nicstat - prints out network statistics for all network cards (NICs), including packets, kilobytes per second, average packet sizes and more.
11.8.4. Logging¶
For logging purposes, the Telemetry Archivers are using CiiLogManager which is configured through logging configuration file. For more information about logging and possible configuration options, see the CII Log user manual [7].
11.9. Advanced Topics¶
11.9.1. Telemetry Archiver statistics¶
Telemetry Archiver exposes basic statistic using the Java MBeans JMX interface. Statistics can be obtained with the usage of jconsole. The user should start the jconsole with the same user account that started Telemetry Archiver and running the following command:
jconsole&
Telemetry Archiver can be chosen from the list of processes and connected to by clicking on the Connect button (Figure 9‑1).
Figure 9‑1: Connect to Telemetry Archiver with Jconsole
After the connection is made, the console with statistics is displayed. The console displays heap usage, CPU usage, number of threads, and similar java statistics. The specific Calculation service statistics are exposed under the elt.telemetry.service.stat namespace.
The statistics show multiple metrics:
current time,
service up-time,
number of working threads,
EA status,
number of subscribed data points,
number of dropped data points,
buffer fullness,
number of archived data points in last hour,
number of archiving errors,
number of archived data points in a day,
number of transferred data packets,
number of data packets not inserted,
number of failed data point subscriptions,
number of invalid data packets.
To obtain statistics, the user should click on the MBeans tab and browse the elt.telemetry.service.stat namespace (Figure 9‑2).
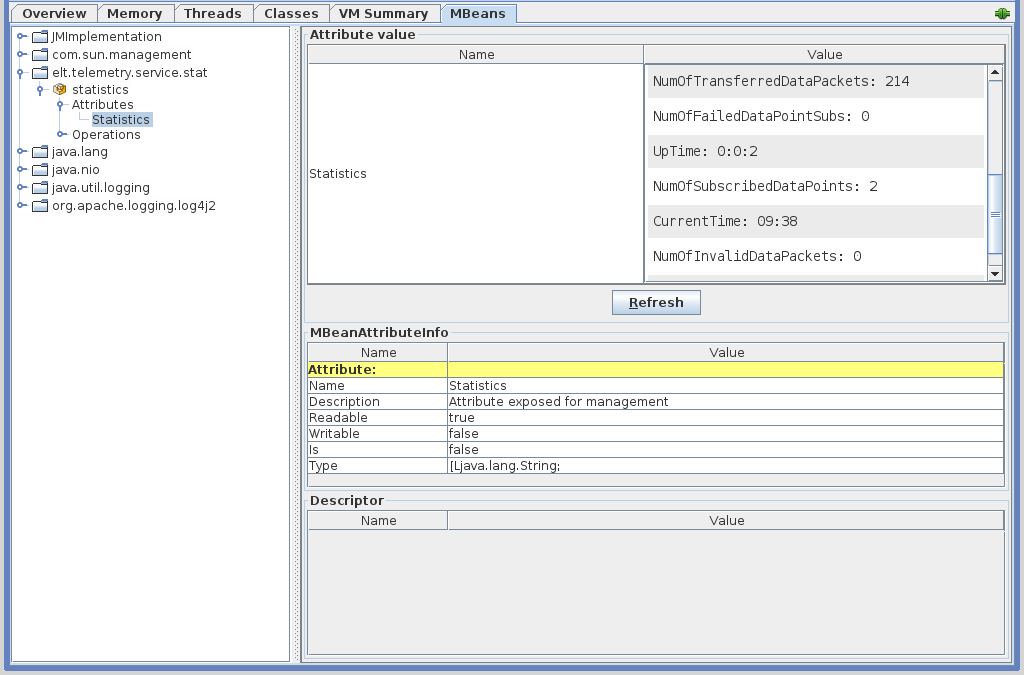
Figure 9‑2: Telemetry Archiver Statistics
11.10. Archive API¶
11.10.1. Archive API: storing, querying and downloading data¶
Telemetry Archive API provides users with the functionality to store, query and download data that is saved in the Engineering Archive. The methods, specified in the TelemetryArchiveApi interface are implemented in the TelemetryArchiveApiSyncImpl class.
Table 9.1: Archive API
Return Type |
Method and Description |
|---|---|
String |
storeData(DataPacket dataPacket) Stores a data packet (containing a timestamp, location of the data in the big data database and data in JSON format) to the Engineering Archive. Returns a string specifying the assigned ID of the data packet. |
List<String> |
storeDataList(List<DataPacket> dataPackets) Stores a list of data packets to the Engineering Archive. Returns a list of strings specifying the assigned IDs of the data packets. |
List<String> |
queryData(String queryString) Queries data packets in the Engineering Archive based on the provided query string (ES Query DSL should be used). Returns a list of strings specifying the IDs of the corresponding data packets. |
List<DataPacket> |
downloadData(List<String> dataPacketIDs) Downloads data packets with provided IDs from the Engineering Archive. |
11.10.2. Archive API: Big Data Storage¶
The Hadoop Storage library provides users with the functionality of writing data to and reading data from the big data database of the Engineering Archive. The HadoopStorage class implements the methods of the BigDataStorage interface.
Table 9.2: Big Data Storage API
Return Type |
Method and Description |
|---|---|
String |
write(URI uri, byte[] data) Writes the data to the file on the location, specified by the big data archive URI and the automatically generated UUID file name. Returns the file name. |
String |
write(URI uri, InputStream stream) Writes the data from the stream to the file on the specified location and automatically generates UUID file name. Returns the file name. |
void |
write(URI uri, int version, String filename, byte[] data) Writes the data to the file on the location, specified by the big data archive URI, version and file name. |
void |
write(URI uri, String filename, InputStream stream) Writes the data to the file on the location, specified by the big data archive URI and file name. |
void |
write(URI uri, int version, String filename, InputStream stream) Writes the data to the file on the location, specified by the big data archive URI, version and file name. |
byte[] |
read(URI uri) Reads data from the file on the location specified by the URI. |
byte[] |
read(URI uri, String filename) Reads data from the file on the location, specified by the big data archive URI and file name. |
byte[] |
read(URI uri, int version, String filename) Reads data from the file on the location, specified by the big data archive URI, version and file name. |
byte[] |
read(URI uri, OutputStream stream) Reads data from the file on the location specified by the URI. The data is written to the output stream. |
void |
read(URI uri, String filename, OutputStream stream) Reads data from the file on the location specified by the URI and file name. The data is written to the output stream. |
void |
read(URI uri, int version, String filename, OutputStream stream) Read data from the file on the location specified by the URI, the version and file name. The data is written to the output stream. |
void |
delete(URI uri, String filename) Deletes file on the location, specified by the big data archive URI and file name. |
void |
delete(URI uri, int version, String filename) Deletes file on the location, specified by the big data archive URI, version and file name. |
11.10.3. Telemetry Archiver Management API¶
The Telemetry Archiver Management API provides users with the functionality to refresh configurations. The methods, specified in the TelemetryServiceManagement interface are implemented in the TelemetryServiceManagementSyncImpl class.
Table 9.3: Service Management API
Return Type |
Method and Description |
|---|---|
void |
refreshConfigurations(List<String > ids) Refreshes configurations, specified by their IDs. The IDs are the UUIDs of the data capture configuration that can be obtained either through querying the config-service or GUI, for more info see section 5.4.3 |
void |
refreshAllConfigurations() Refreshes all configurations. |
11.11. Data Capture Configuration Options¶
The data capture configurations contain the following fields, which could be tweaked in order to get the desired archiving behaviour:
Table 9.4: Data capture configuration options
Field |
Description |
Example |
|---|---|---|
dataPointAddress |
Address of data point in OLDB |
cii.oldb:///datapoint s/dp1/ |
archiveMode |
Defines on which on-change event the data point is archived (data point value change, quality flag change, time based – e.g. once per day) |
VALUE_CHANGE or QUALITY_CHANGE or METADATA_CHANGE |
deltaValue |
Delta value change required to archive (in the case of data value change event) |
+/- 1.0 |
deltaType |
Type that the delta value field represent (absolute change or relative change) If RELATIVE delta type is chosen, the delta value represents the percentage of the data point value for which the data point value should change in order to be archived. The value 1 represents 100% change and value 0.01 represents 1% change. If ABSOLUTE delta type is chosen, the delta value represents the actual value for which the data point value should have changed in order to be archived. |
ABSOLUTE or RELATIVE |
minimumInterval |
Minimum time between specific data point archiving in the hh:mm:ss format. If the data point value has changed multiple times in a short interval, it ensures we don’t store too many values. If minimum interval is set to 0, every data point value change will be archived according to the delta field. |
00:00:10 |
maximumInterval |
Maximum interval between two data point archiving events in the hh:mm:ss format. If the data point value has not changed in the specified maximum interval, the data point value will still be archived. Setting it to 0 will disable it. |
01:15:00 (data point should be archived at least on every 1 hour and 15 minutes) |
archivingEnabled |
Enable archiving (True) or disable archiving (False) for this specific data capture configuration |
True/False |
11.12. Telemetry Archiver Configuration¶
Listing 9‑1 Telemetry Archiver configuration YAML
engineeringArchiveBackupURI: "http://ciiarchivehost:9200/"
engineeringArchiveURI: "http://ciiarchivehost:9200/"
largeStorageServiceURI: "http://ciihdfshost:9870/"
serviceRange:
- "cii.config://remote/telemetry/serviceRange2"
Each Telemetry Archiver contains its configuration stored in the CII Configuration Service.
Table 9.5: Telemetry Archiver Configuration settings
Field |
Description |
Example |
|---|---|---|
telemetryServiceURI |
Defines an IP address and port on which the Telemetry Archiver is bound to |
zpb.rr://0.0.0.0:9115 / Default is zpb.rr://0.0.0.0:9115 / |
simulateArchive |
If set to true, all data archive operations will be simulated. If set to false, data will be archived to Engineering archive |
True/False Default is False |
simulateCapture |
If set to true, all data capture is simulated (using simulator instead of real OLDB) |
True/False Default is False |
archiveQualityMask |
Permits selective archiving of a data points based on data points quality flag Possible values: UNKOWN, INVALID, VALID, SIMULATED, ALL, NONE |
UNKOWN, VALID Default is ALL |
engineeringArchiveURI |
Engineering Archive location |
Default is https://ciiarchive:92 00/ |
engineeringArchiveBac kupURI |
Engineering Archive backup URI |
Default is https://ciiarchive2:9 200/ |
maxSearchSize |
The maximum number of data packets stored in the EA that can be retrieved at once |
5000 Default is 10000 |
authenticationToken |
Authentication token that allows service to interact with the archiving system |
Default is empty string |
serviceRange (required) |
Defines the configuration service URI location from where the data capture configuration will be loaded. Multiple service ranges are allowed here |
[cii.config://*/telem etry/service1] |
archivingBufferSize |
Maximum number of data packets that the archiving buffer can contain |
50000 Default is 100000 |
bufferBatchSize |
Maximum number of data packets that one archiving batch can contain |
150 Default is 400 |
maximumBatchWait |
Maximum number of seconds that the archiving buffer will wait for data before sending a batch to the Engineering Archive (even if the batch is not full). |
5 Default is 1 |
11.13. Big Data Storage Examples¶
The following listings show examples of the usage of the Big Data Storage for the Java, CPP and Python programming languages.
Listing 9‑2: Example usage of the Big Data Storage in Java
package sampleapp;
import java.io.IOException;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.net.URI;
import java.net.URISyntaxException;
import elt.storage.HadoopStorage;
import elt.storage.BigDataStorage;
/**
* Hadoop Storage example.
*/
public class HadoopStorageExample {
/**
* Private method to generate content to be written to the remote file
*/
private static String generateContent() {
String s = "AAAA";
for (int i = 0; i < 100; i++) {
switch(i % 5) {
case 0:
s += "cccc";
break;
case 1:
s = s + s;
break;
case 2:
s += "XXXXXXXXXX";
break;
case 3:
s += "!!!!!!";
break;
case 4:
s += "<<<>>>";
break;
}
}
return s;
}
/**
* HadoopStorage main method.
*
* @param args Command line arguments (none are required).
*/
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
int status = 0;
final BigDataStorage hadoopStorage =
new HadoopStorage(new URI("http://ciihdfshost:9870"), "/esoSample");
// contains path to the archive (remote directory)
final URI uri = new URI("cii.config://*/archive");
// remote filename
final String remoteFilename = "file1.bin";
// content to store
final String contentToStore = generateContent();
try {
// save data to Hadoop, use binary stream
ByteArrayInputStream stream = new ByteArrayInputStream(contentToStore.getBytes());
System.out.println("Writing blob to hadoop storage...");
hadoopStorage.write(uri, remoteFilename, stream);
// read data from Hadoop
ByteArrayOutputStream ostream = new ByteArrayOutputStream();
System.out.println("Reading blob from hadoop storage...");
hadoopStorage.read(uri, remoteFilename, ostream);
ostream.close();
if (contentToStore.equals(ostream.toString())) {
System.out.println("OK, saved and read content are the same");
} else {
System.err.println("FAIL: data from remote not same as source");
status = 1;
}
// delete a file from Hadoop
hadoopStorage.delete(uri, remoteFilename);
} catch (Throwable th) {
System.err.println(String.format("Exception during remote operation: %s", th));
status = 5;
}
try {
// try to read from non existent file
System.out.println("Access to non existing remote file (should fail)...");
byte[] data = hadoopStorage.read(uri, remoteFilename);
} catch (Throwable th) {
System.err.println(String.format("REMOTE READ FAILURE (expected): %s", th));
}
System.exit(status);
}
}
Listing 9‑3: Example usage of the Big Data Storage in CPP
#include <iostream>
#include <sstream>
#include <string>
#include <cstdlib>
#include <ciiHadoopStorage.hpp>
#include <ciiException.hpp>
/**
* Generates sample string
* @return string, generated content
*/
static std::string generateContent() {
std::string s = "AAAA";
for (std::size_t i = 0; i < 100; i++) {
switch (i % 5) {
case 0:
s += "BBBB";
break;
case 1:
s = s + s;
break;
case 2:
s += "XXXXXXXXXX";
break;
case 3:
s += ".....";
break;
case 4:
s += "<<<>>>";
break;
}
}
return s;
}
/**
* main method
*/
int main(int argc, char **argv) {
int status = 0;
const elt::mal::Uri hadoopLocation("http://ciihdfshost:9870");
const std::string hadoopEndpoint("/esoSample");
const std::string remoteDirectory = "archive";
const std::string remoteFilename = "file.bin";
const std::string contentToStore(generateContent());
// Initialize hadoop storage,
// First parameter is Uri of the webhdfs server
// Second parameter is name of the top directory under which all files for this
// instance of hadoop storage will be stored.
elt::storage::CiiHadoopStorage storage(hadoopLocation, hadoopEndpoint);
// In this example, stream is used
std::stringstream stream(contentToStore);
// Create receiving stream
std::ostringstream ostream;
try {
// Write content of the stream to the remote file
std::cout << "Writing blob to hadoop storage..." << std::endl;
storage.write(remoteDirectory, remoteFilename, stream);
// Read content of the stream from the remote file
std::cout << "Reading blob from hadoop storage..." << std::endl;
storage.read(remoteDirectory, remoteFilename, ostream);
// Remove remote file
storage.remove(remoteDirectory, remoteFilename);
if (ostream.str() == contentToStore) {
std::cout << "OK, saved and read content are the same" << std::endl;
} else {
std::cerr << "FAIL: data from remote not same as source" << std::endl;
status = 1;
}
} catch (const elt::error::CiiException &e) {
std::cerr << "Cii Exception during remote operation: " << e.what() << std::endl;
status = 2;
} catch (const std::exception &e) {
std::cerr << "Std Exception during remote operation: " << e.what() << std::endl;
status = 5;
}
// Read from non existing remote file
try {
std::cout << "Access to non existing remote file (should fail)..." << std::endl;
storage.read(remoteDirectory, remoteFilename, ostream);
} catch (const std::exception &e) {
std::cerr << "REMOTE READ FAILURE (expected): " << e.what() << std::endl;
}
return status;
}
Listing 9‑4: Example usage of the Big Data Storage in Python
#!/usr/bin/env python
#pylint: disable=E1101,C0103,R0914,C0330,W0612
#This script demonstrates usage of HadoopStorage
import sys
import io
import traceback
import elt.storage
def generate_content():
"""Helper function that generates content string"""
s = 'AAAA'
for i in range(100):
modulo = i % 5
if modulo == 0:
s += 'bbbb'
elif modulo == 1:
s += s
elif modulo == 2:
s += 'XXXXXXXXXX'
elif modulo == 3:
s += ',,,,,,'
else:
s += '<<<>>>'
return s
# Define URI for remote webhdfs server to be used
hadoop_location = 'http://ciihdfshost:9870'
# Define top level remote directory
hadoop_endpoint = 'esoSample'
# Define remote directory
remote_directory = 'archive'
# Define remote filename
remote_filename = 'file.bin'
def _main():
"""main method implementation"""
status = 0
# Initialize hadoop storage.
# First parameter is string containing Uri of the webhdfs server
# Second parameter is name of the top directory under which all files
# for this instance of hadoop storage will be stored.
storage = elt.storage.CiiHadoopStorage(hadoop_location, hadoop_endpoint)
# In this example, stream is used
content_to_store = generate_content()
# Content to write must be raw binary values. Use io.BytesIO!
stream = io.BytesIO(content_to_store.encode('utf-8'))
try:
print('Writing blob to hadoop storage...')
# Write content of the stream to the remote file
storage.write_from(stream, remote_directory, remote_filename)
# Read content of the remote file into the stream
ostream = io.BytesIO()
print('Reading blob from hadoop storage...')
storage.read_into(ostream, remote_directory, remote_filename)
# Delete remote file
storage.remove(remote_directory, remote_filename)
if content_to_store == ostream.getvalue().decode('utf-8'):
print("OK, saved and read content are the same")
else:
print("FAIL: data from remote not same as source", file=sys.stderr)
status = 1
# pylint: disable=W0703
except Exception as e:
traceback.print_tb(sys.exc_info()[2])
print("Exception during remote operation: ", e, file=sys.stderr)
status = 5
# try to read from non existing remote file
try:
print('Access to non existing remote file (should fail)...')
ostream = io.BytesIO()
storage.read_into(ostream, remote_directory, remote_filename)
# pylint: disable=W0703
except Exception as e:
print("REMOTE READ FAILURE (expected): ", e, file=sys.stderr)
return status
def main():
"""main method wrapper"""
result = 0
try:
result = _main()
#pylint: disable=W0703
except Exception as e:
print(e)
traceback.print_tb(sys.exc_info()[2])
result = 5
return result
if __name__ == '__main__':
sys.exit(main())